3个不稳定版本
| 0.5.0 | 2023年2月28日 |
|---|---|
| 0.4.1 | 2022年9月8日 |
| 0.4.0 | 2021年1月22日 |
#215 in 生物学
255KB
5K SLoC
Finch
![]()
![]()
Finch是基因组数据的min-wise独立排列局部敏感哈希("MinHashing")实现。此存储库提供了一个库和命令行界面,用于重新实现One Codex的现有内部聚类/序列搜索工具(并添加了新功能/扩展!)在Rust。
入门
安装
您可以从源代码构建Finch,这需要Rust >= 1.49。Rust的Cargo包管理器(有关Cargo安装说明,请参阅rustup)可以自动构建和安装Finch,使用cargo install finch_cli。如果您需要Python绑定,您必须采取额外步骤(请参阅Python支持)。或者,下载预构建的二进制文件或从PyPi pip install finch-sketch进行安装。
示例用法
要开始,我们首先为几个FASTA或FASTQ文件计算sketches。这些sketches是底层基因组数据的紧凑、样本表示,并允许finch快速估计数据集之间的距离。使用finch sketch命令进行sketching文件
finch sketch example.fastq example2.fastq
生成的草图文件(example.fastq.sk 和 example2.fastq.sk)可以与其他 finch 命令一起使用(以及其他 MinHash 实现1)。请注意,Finch 的所有命令都可以接受草图或原始序列文件。如果传入后者的文件,finch 将在飞行中生成草图。然而,飞行中生成的草图不会被保存,因此如果您打算多次使用草图,应该调用 finch sketch。
一旦草图生成,就可以比较多个测序运行以确定它们的相似程度。
finch dist example.fastq.sk example2.fastq.sk
这将打印出包含一些关键距离统计信息的 JSON 格式结果,包括 containment 和 jaccard 相似度分数以及 mashDistance 距离估计。
[
{
"commonHashes": 30,
"containment": 0.03,
"jaccard": 0.015228426395939087,
"mashDistance": 0.1669789474914277,
"query": "example2.fastq",
"reference": "example1.fastq",
"totalHashes": 1000
}
]
在这种情况下,这些文件估计的距离为 ~0.17,包含量为 0.03(即两个 FASTQ 共享 3% 的最小元素)。请注意,通过使用更大的 --n-hashes 参数重新计算草图可以为高度相似的数据库提供额外的分辨率。
接下来,我们可能想找到与我们的示例 FASTQ 在整个 RefSeq 中最接近的基因组。为此,我们只需将示例查询文件作为第一个参数传递,将包含 RefSeq 中所有基因组的草图文件作为第二个参数传递(有关与 finch 一起工作的预计算 RefSeq 数据库的示例数据部分)。
finch dist ./example.fastq.sk ./refseq_sketches_21_1000.sk --max-dist 0.2
在这里,我们还将最大距离设置为 0.2,以便过滤掉不太相关的基因组(距离为 0 表示完全相同的基因组)。设置最大距离确保只返回相关结果 -- 省略此参数将返回到 RefSeq 中所有基因组的距离。
注意:以下每个命令都将在下文中详细说明,并且通过传递每个命令的 --help 标志还可以获得更多信息,例如 finch dist --help。
设计目标
我们对 Finch 有三个主要的设计目标
-
支持跟踪 k-mer/minmer 计数;
-
改进用于原始序列数据(即 FASTQ)的错误过滤;以及
-
改进性能。
支持计数
Finch 是第一个支持跟踪每个唯一 k-mer/minmer 浓度的 MinHash 实现。这除了支持更高级的过滤(在此实现)和计数感知距离度量(未来研究的领域)之外,还允许对数据进行有用的快速解释(例如,使用 finch hist 可视化测序深度)。由于 Finch 也支持 新的 Mash JSON 兼容格式,因此我们可以将此计数信息保存下来以供下游处理和比较。
⚠️ 注意,尽管 Finch 支持常见的 JSON 交换格式,但由于哈希种子值不兼容,仍然可能存在不兼容性(Finch 使用种子值
0,而 Mash 使用42;有关更多讨论,请参阅 此问题)。
过滤
Finch 的一个关键设计目标是能够准确且稳定地绘制细菌分离株的变量深度测序(即,不需要高质量的组装)。虽然 Mash 具有指定固定绝对截止值(或使用 Bloom 过滤器过滤掉样本中的独特 minmers)的能力,但在实践中,这种过滤机制在变化的测序深度、基因组大小和测序错误特征上表现不佳。这里实现的 Finch 过滤方法扩展了原始 Mash 论文中的一些想法,以及关于聚类临床 C. diff 分离株的先前工作。
Finch 包含两种自动过滤类别(默认为对 FASTQ 进行过滤)来解决这一挑战
-
基于计数的自适应过滤:我们的默认实现“过度绘制”一个输入文件(即,包含比用户指定的更多倍数的 minmers)并动态确定一个合适的基于计数的过滤截止值,该截止值可以去除低丰度的 k-mers(这些主要由随机错误组成)。作为备选方案,此实现从不排除可能被认为是错误的上限比例的 minmers(
k倍于指定的--err-filter错误率,默认为 21%)。 -
定向过滤:我们还应用一个“定向过滤器”来去除在一种方向上发现频率极高的 k-mers;实际上,这些通常是测序适配器或其他非代表性样本的假象(并可能错误地减少两个草图之间的相似性)。
实际上,这些优化显著提高了变量深度分离株和完成组装之间的距离估计的稳定性和准确性。下面的图表显示了高质量细菌组装和代表不同测序深度的 FASTQ 文件草图的距离:无过滤(cutoff=0)、“天真”过滤(cutoff=1)和 Finch 的自适应、变量截止过滤。我们使用包含度衡量,结果越接近 100% 越好
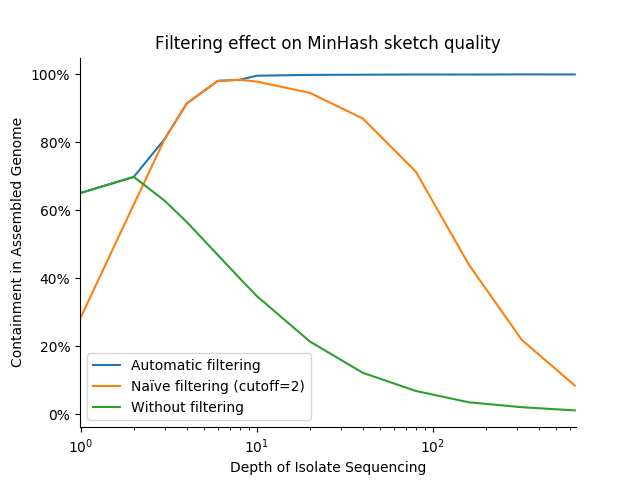
值得注意的是,此策略在测序深度上表现良好,而固定的截止值 0 和 1 永远无法实现接近 100% 的预期包含度(并且前者在适度的深度上失败)。它对重复错误也很稳健(即,错误 k-mers/minmers 的计数 >= 2),这可能在测序深度低至 10-20X 时开始引起问题。
速度/性能
除了 Rust 提供的一些内存安全性保证之外,我们还在现有实现上看到了相当的速度提升。理想情况下,哈希应该是 MinHashing 的限制步骤。分析表明 finch 大约花费了三分之一的运行时间在 murmurhash3_x64_128 上,因此我们应该接近这个理论极限。
| Mash | Mash(过滤后的) | Sourmash | Finch | Finch(过滤后的) | |
|---|---|---|---|---|---|
| 时间 | 238秒 | 276秒 | 518秒 | 99秒 | 104秒 |
| 最大内存(MB) | 1.2 | 501.1 | 13.9 | 21.8 | 60.0 |
注意:基准测试在 2015 年初的 MacBook Pro 上运行。基准测试是对 4.8Gb FASTQ 文件进行草图绘制(SRR5132341.fastq),草图大小为 n=10,000。Finch 过滤后的结果使用默认选项,而 Mash 使用
-b 500Mb分配 500Mb 的 Bloom 过滤器。基准测试使用了以下 Mash 的提交(23776db)和 sourmash 的提交(5da5ee7)
用法
Finch 支持四种主要操作,其中许多操作具有类似的参数。
共享参数
Finch 可以通过多个参数来控制绘图的方式(这些选项也适用于 dist,hist 和 info 命令)。
-n <N>/--n-hashes <N>控制sketch的整体大小(更高的值在比较中提供更好的分辨率)。默认1000。-k <K>/--kmer-length <K>设置要散列的kmer的大小(更高的值使比较在分类学上更具体)。默认21。--seed <S>设置散列的种子。只有在直接导出sketch与其他版本的Mash算法进行比较时,才应更改此值,后者使用非零默认种子。默认0。
绘图后,会执行过滤,可以通过多个选项进行控制
-f/--filter/--no-filter决定是否应用过滤(如果没有指定,默认情况下为FASTQ文件执行过滤,不为FASTA文件执行过滤)--min-abun-filter <MIN>/--max-abun-filter <MAX>设置所有kmer必须存在的绝对最小和最大丰度(包含)。最小过滤器将覆盖任何自适应错误过滤器猜测(以下)。--err-filter <ERR_VALUE>是默认的自适应过滤方案。从概念上讲,ERR_VALUE应该大约是测序仪的误差率或更高。请注意,高误差率测序数据(即长读测序)通常在MinHashing中表现不佳。--strand-filter <V>设置链过滤器截止值。
请注意,如果从oversketch中留下的kmer不足以满足sketch大小,sketch将失败。有两种选项可能有所帮助
--oversketch <N>可以用来增加oversketch的大小(通常是200倍),并增加过滤后的版本足够大的可能性。--no-strict将允许Finch使用小于指定大小的sketch继续进行。请谨慎使用。
finch sketch
finch sketch 将读取FASTA或FASTQ文件,并生成一个可用于进一步的"sketch"。
如果正在读取的文件是sketch并且设置了过滤标志(-f/--filter),则将重新应用丰度过滤器以允许post-sketch过滤。但是,链过滤器只能应用于原始FAST(A/Q)文件,因为在保存sketch时丢失了链级数据。
默认情况下,sketch 会在它绘制的 FAST(A/Q) 文件旁边生成带有 .sk 后缀的文件。可以通过传递 -O(大写 O)将输出写入标准输出或 -o <file>(小写 o)将输出写入文件来覆盖此行为。要从标准输入读取,使用文件名 -;这允许将文件流式传输到 finch,例如 cat testfile.fq | finch sketch -o testfile.sk -。
如果编辑 src/mash/hash.h 并将哈希值设置为 0 或通过设置 --seed 42 手动覆盖 Finch 的种子值,则 Sketch 应与原始 Mash 实现兼容。
finch dist
finch dist 将计算不同 Sketch 之间的 Jaccard 距离。如果列出的文件是 FASTA/Q 而不是 Sketch,Finch 将自动使用与 sketch 中相同的命令行参数将它们绘制到内存中,或者对于第一个文件之后的文件,使用绘制第一个文件时使用的参数。
距离和包含关系将仅从查询到参考集合的一个或多个查询中计算;默认情况下,列表中的第一个 Sketch 将用作查询,所有其他 Sketch 将用作参考。可以通过传递 --queries <sketch_1>,<sketch_2 来手动覆盖此行为,并可以使用其他 Sketch 作为参考。此外,传递 --pairwise 选项将计算所有 Sketch 之间的距离。
由于不同的计数算法和停止标准,距离可能略微不同于原始 Mash 程序和旧版 finch 中的计算。传递 -old-dist 标志将回退到旧版 finch 的计算;自版本 0.3 以来已删除对 Mash 精确距离计算的支持。
finch hist
finch hist 将为提供的每个 Sketch 输出 JSON 格式的直方图。直方图是每个深度的 minmers 数量的列表,例如,对于具有两个 minmers 的 Sketch,一个深度为 1(第一个位置),另一个深度为 3(第三个位置),其直方图为 {"sketch_name": [1, 0, 1]}。
⚠️ 您可以使用以下命令与Matplotlib一起快速获取直方图:
finch hist test.fastq.sk | python -c 'import json; import matplotlib.pyplot as plt; import sys; v = json.loads(sys.stdin.read()).values()[0]; plt.plot(range(1, len(v)+1), v); plt.show()'. 注意,finch hist的JSON输出可能在未来的版本中更改,例如,更紧凑的{count: value}格式或类似格式。
finch info
finch info将为提供的每个sketch输出格式化的列表,包括% GC、覆盖率等。
⚠️ 请注意,这些返回的值是近似的,用于计算的算法仍然是粗略的,并且可能会发生变化。
示例数据
我们已使用此脚本对NCBI RefSeq集合(截至2017年3月27日)进行了sketch,并为每个细菌和病毒基因组提供了单个sketch的tar包。链接:k=21和n=1,000,k=31和n=1,000,k=21和n=10,000,以及k=31和n=10,000。
参考文献 & 备注
还有其他几种Mash算法的实现,应该与此版本兼容/可比较,尤其是
备注
- 1 然而,请参阅此问题跟踪互操作性,并注意其他实现可能使用不同的种子值。
Python支持
您可以使用Pip安装Finch
pip install finch-sketch
您可以使用以下命令将Finch编译成Python库:
pip install maturin
cd lib
maturin build --features=python --release --strip
# or maturin develop, etc
# to cross-compile linux wheels:
cp ../README.md .
# and edit the `readme` key of Cargo.toml
docker run --rm -v $(pwd):/io ghcr.io/pyo3/maturin:main build --features=python --release --strip --interpreter=python3.10 --compatibility=manylinux2010
然后,例如,为了计算两个E. coli之间的相似性:
from finch import sketch_file
sketch_one = sketch_file('WIS_EcoB_v2.fas')
sketch_two = sketch_file('WIS_Eco10798_DRAFTv1.fas')
cont, jacc = sketch_one.compare(sketch_two)
Cap'n Proto
在src/serialization文件中有一个finch.capnp,以及MinHash模式输出(https://github.com/marbl/Mash/blob/54e6d66b7720035a2605a02892cad027ef3231ef/src/mash/capnp/MinHash.capnp)
这两个都是在安装了 capnp 和以下命令后生成的:cargo install capnpc
capnp compile -orust:finch-lib/src/serialization/ --src-prefix=finch-lib/src/serialization/ finch-lib/src/serialization/finch.capnp
capnp compile -orust:finch-lib/src/serialization/ --src-prefix=finch-lib/src/serialization/ finch-lib/src/serialization/mash.capnp
然后搜索并替换 crate:: 路径来修复它 crate::serialization::。
贡献
可以通过GitHub问题报告问题或改进建议。我们很高兴接受和/或指导任何添加或修复(最好是作为pull request提交)。有关我们的行为准则,请参阅 CODE_OF_CONDUCT.md。
依赖项
~6MB
~110K SLoC