35 个版本 (14 个稳定版)
| 1.6.2 | 2024年7月23日 |
|---|---|
| 1.4.0 | 2024年4月30日 |
| 1.0.0 | 2024年3月30日 |
| 0.9.1 | 2024年3月17日 |
| 0.2.6 | 2021年10月22日 |
#25 in 数学
每月下载量 146
在 4 crates 中使用
2MB
35K SLoC
Russell Sparse - 大型稀疏线性系统的求解器(封装了MUMPS和UMFPACK)
![]()
此 crate 是 Russell - Rust 科学库 的一部分
内容
简介
此库实现了处理稀疏矩阵的工具,以及使用最佳库(如 UMFPACK(推荐) 和 MUMPS(用于非常大的系统))解决大型稀疏系统的函数。
此库实现了稀疏矩阵的三个存储格式
- COO:坐标矩阵,也称为稀疏三元组。
- CSC:压缩稀疏列矩阵
- CSR:压缩稀疏行矩阵
此外,为了统一处理上述稀疏矩阵数据结构,此库实现了
- SparseMatrix:可以是 COO、CSC 或 CSR 矩阵
COO矩阵在需要更新矩阵的值时表现最佳,因为它可以轻松访问三元组(i,j,aij)。例如,重复访问是有限元方法(FEM)代码在逼近偏微分方程时的主要用例。此外,COO矩阵允许存储重复条目;例如,三元组 (0, 0, 123.0) 可以存储为两个三元组 (0, 0, 100.0) 和 (0, 0, 23.0)。再次强调,这是有限元代码的主要需求,因为所谓的组装过程,其中元素添加到“全局刚度”矩阵的相同位置。不过,在某个阶段必须对重复条目进行求和,以便进行线性求解(例如,MUMPS,UMFPACK)。这些线性求解器还使用更节省内存的存储格式CSC和CSR。有关更多信息,请参阅russell_sparse文档。
此库还提供了读取和写入包含(大量)稀疏矩阵的Matrix Market文件的函数,这些矩阵可用于性能基准测试或其他研究。函数[read_matrix_market()]读取Matrix Market文件并返回一个[CooMatrix]。要写入Matrix Market文件,我们可以使用函数[write_matrix_market()],它接受一个[SparseMatrix],因此自动将COO转换为CSC或COO转换为CSR,同时执行重复项的求和。函数write_matrix_market还写入一个SMAT文件(类似于Matrix Market格式),没有标题,并且索引从0开始。SMAT文件可以提供给神奇的Vismatrix工具,以交互式地可视化稀疏矩阵的结构和值;请参阅下面的示例。
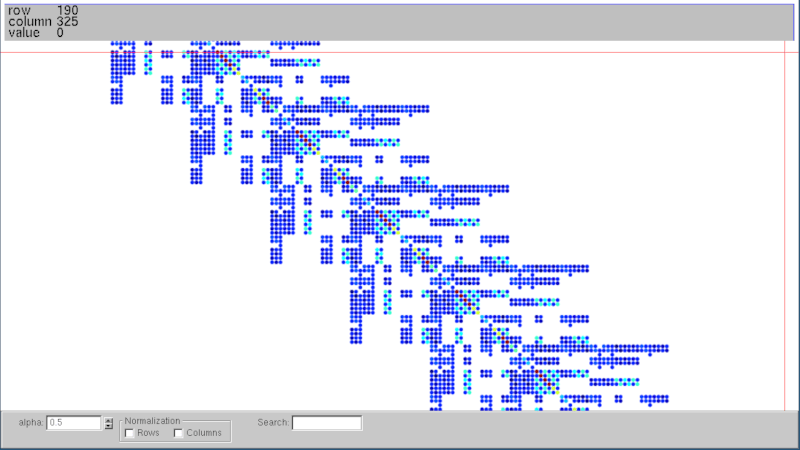
文档
安装
此crate依赖于一些非Rust高性能库。有关安装这些依赖项的步骤,请参阅主README文件。
设置 Cargo.toml
![]()
👆检查crate版本并相应更新Cargo.toml
[dependencies]
russell_sparse = "*"
可选功能
以下(Rust)功能可用
intel_mkl:使用Intel MKL代替OpenBLASlocal_suitesparse:使用本地编译的SuiteSparse版本with_mumps:启用MUMPS求解器(本地编译)
请注意,主README文件介绍了根据每个功能编译所需的库的步骤。
🌟 示例
本节说明了如何使用russell_sparse。另请参阅
使用 UMFPACK 解一个小型稀疏线性系统
use russell_lab::{vec_approx_eq, Vector};
use russell_sparse::prelude::*;
use russell_sparse::StrError;
fn main() -> Result<(), StrError> {
// constants
let ndim = 3; // number of rows = number of columns
let nnz = 5; // number of non-zero values
// allocate solver
let mut umfpack = SolverUMFPACK::new()?;
// allocate the coefficient matrix
let mut coo = SparseMatrix::new_coo(ndim, ndim, nnz, Sym::No)?;
coo.put(0, 0, 0.2)?;
coo.put(0, 1, 0.2)?;
coo.put(1, 0, 0.5)?;
coo.put(1, 1, -0.25)?;
coo.put(2, 2, 0.25)?;
// print matrix
let a = coo.as_dense();
let correct = "┌ ┐\n\
│ 0.2 0.2 0 │\n\
│ 0.5 -0.25 0 │\n\
│ 0 0 0.25 │\n\
└ ┘";
assert_eq!(format!("{}", a), correct);
// call factorize
umfpack.factorize(&mut coo, None)?;
// allocate two right-hand side vectors
let b = Vector::from(&[1.0, 1.0, 1.0]);
// calculate the solution
let mut x = Vector::new(ndim);
umfpack.solve(&mut x, &coo, &b, false)?;
let correct = vec![3.0, 2.0, 4.0];
vec_approx_eq(&x, &correct, 1e-14);
Ok(())
}
有关更多示例,请参阅russell_sparse文档。
另请参阅文件夹examples。
工具
此crate包含一个名为solve_matrix_market的工具,用于研究现有稀疏求解器的性能(目前为MUMPS和UMFPACK)。
solve_matrix_market读取Matrix Market文件并求解线性系统
A ⋅ x = b
其中,右侧(b)是一个只包含1的向量。
数据目录中包含一个名为 bfwb62.mtx 的 Matrix Market 文件示例,您可以从 https://sparse.tamu.edu/ 下载更多矩阵
例如,运行以下命令
cargo run --release --bin solve_matrix_market -- ~/Downloads/matrix-market/bfwb62.mtx
或者
cargo run --release --bin solve_matrix_market -- --help
来查看选项。
solve_matrix_market 的默认求解器是 UMFPACK。要使用 MUMPS 运行,请使用 --genie (-g) 标志
cargo run --release --bin solve_matrix_market -- -g mumps ~/Downloads/matrix-market/bfwb62.mtx
输出如下所示
{
"main": {
"platform": "Russell",
"blas_lib": "OpenBLAS",
"solver": "MUMPS-local"
},
"matrix": {
"name": "bfwb62",
"nrow": 62,
"ncol": 62,
"nnz": 202,
"complex": false,
"symmetric": "YesLower"
},
"requests": {
"ordering": "Auto",
"scaling": "Auto",
"mumps_num_threads": 0
},
"output": {
"effective_ordering": "Amf",
"effective_scaling": "RowColIter",
"effective_mumps_num_threads": 1,
"openmp_num_threads": 24,
"umfpack_strategy": "Unknown",
"umfpack_rcond_estimate": 0.0
},
"determinant": {
"mantissa_real": 0.0,
"mantissa_imag": 0.0,
"base": 2.0,
"exponent": 0.0
},
"verify": {
"max_abs_a": 0.0001,
"max_abs_ax": 1.0000000000000004,
"max_abs_diff": 5.551115123125783e-16,
"relative_error": 5.550560067119071e-16
},
"time_human": {
"read_matrix": "43.107µs",
"initialize": "266.59µs",
"factorize": "196.81µs",
"solve": "166.87µs",
"total_ifs": "630.27µs",
"verify": "2.234µs"
},
"time_nanoseconds": {
"read_matrix": 43107,
"initialize": 266590,
"factorize": 196810,
"solve": 166870,
"total_ifs": 630270,
"verify": 2234
},
"mumps_stats": {
"inf_norm_a": 0.0,
"inf_norm_x": 0.0,
"scaled_residual": 0.0,
"backward_error_omega1": 0.0,
"backward_error_omega2": 0.0,
"normalized_delta_x": 0.0,
"condition_number1": 0.0,
"condition_number2": 0.0
}
}
MUMPS + OpenBLAS 问题
我们发现当 OpenMP 线程数自动选择,即使用可用线程数时,MUMPS + OpenBLAS 变得非常、非常慢。因此,建议使用 OpenBLAS 时将 LinSolParams.mumps_num_threads 设置为 1(当使用 OpenBLAS 时此值自动设置)。
这个问题也被参考文献 #1 发现,该文献表示(第 72 页)"我们观察到 OpenBLAS 库在 MUMPS 中的多线程导致多个线程冲突,有时会导致求解器显著变慢。"
因此,我们必须采取以下两种方法之一
- 如果为 MUMPS 修复 OpenMP 线程数,则将 OpenBLAS 的 OpenMP 线程数设置为 1
- 如果为 OpenBLAS 修复 OpenMP 线程数,则将 MUMPS 的 OpenMP 线程数设置为 1
在使用 MUMPS + Intel MKL 时没有注意到这个问题。
重现此问题的命令
OMP_NUM_THREADS=20 ~/rust_modules/release/solve_matrix_market -g mumps ~/Downloads/matrix-market/inline_1.mtx -m 0 -v --override-prevent-issue
为了重现此问题,我们还需要
- Git hash = e020d9c8486502bd898d93a1998a0cf23c4d5057
- 删除 Debian OpenBLAS、MUMPS 等。
- 使用
02-ubuntu-openblas-compile.bash安装编译好的 MUMPS 求解器
参考文献
- Dorozhinskii R (2019) 线性求解器配置用于线性隐式时间积分和高效并行传热-流体计算中的数据传输. 计算科学和工程硕士学位论文。慕尼黑工业大学信息学院。
开发者
c_code目录包含对稀疏求解器(MUMPS、UMFPACK)的薄封装build.rs文件使用cc构建C封装zscripts目录还包含以下内容memcheck.bash:使用 Valgrind 检查 C 代码中的内存泄漏run-examples:运行examples目录中的所有示例run-solve-matrix-market.bash:从bin目录运行 solve-matrix-market 工具
依赖项
~3–4.5MB
~78K SLoC