1个不稳定版本
| 0.1.3 | 2022年4月28日 |
|---|
#179 in 可视化
540KB
3K SLoC
![]()
![]()
![]()
![]()
![]()
plotrs
一个命令行应用程序,用于将csv数据集绘制到图表上。它通过从.ron文件中读取图表定义,然后从一个或多个csv文件中提取数据,并生成.png图像来工作。目前仅支持散点图。
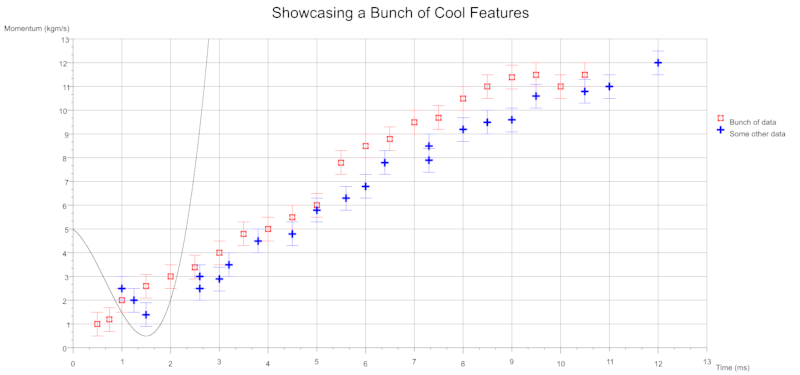
在远古时代,我使用GNU Octave来绘制关于等离子体吸收和光伏热电电流的数据。作为我的Rust之旅的一部分,我想尝试编写一个以类似风格绘制数据点的程序。
特性
- 将最佳拟合曲线叠加到您的图表上
- 图表元素/组件的位置和大小将根据您想要的图像大小动态计算
- 可以使用多种颜色和符号来绘制数据集
- 数据可以来自一个或多个csv文件 - 您只需针对给定文件中的某些列进行提取
- 误差条 - 单独或联合绘制x和y的误差
- 如果您的数据使用负x-y值,则绘制适当的象限
安装
cargo安装plotrs
如何使用
创建一个包含您想要的图表配置的.ron文件,并使用以下命令生成png
plotrs -g <graph_type> -c <path_to_config_ron_file> -o <dir_for_output_png>
例如
plotrs -g scatter -c scatter_config.ron -o here/please
请注意,如果您的画布太小,则标题和轴标签可能会变得模糊。
图表.ron模式
散点定义
Scatter(
title: "Engery against Time for Fuzzing About Things",
canvas_pixel_size: (840, 600),
x_axis_label: "Time (ms)",
x_axis_resolution: 11, // Number of times the x-axis will be divided to show your data scale
y_axis_label: "Energy (kJ)",
y_axis_resolution: 11, // Number of times the y-axis will be divided to show your data scale
has_grid: false, // Should the graph have a light grey background grid
has_legend: false, // should a legend be generated? Only really useful with multiple data sets
// data sets can be sourced from the same csv or from different ones and each can be configured with different colours/symbols
data_sets: [
DataSet(
data_path: "scatter.csv",
has_headers: true, // if your data has headers set to `true` so they can be ignored
x_axis_csv_column: 0, // which column contains the x values
x_axis_error_bar_csv_column: None, // which column contains x uncertainty Some(usize) or None
y_axis_csv_column: 1, // which column contains the y values
y_axis_error_bar_csv_column: None, // which column contains y uncertainty Some(usize) or None
name: "Very interesting", // legend will indicate which colour and symbol correspond to which data set
colour: Orange, // the colour to render a data point
symbol: Cross, // the shape a plotted data point should take
symbol_radius: 5, // The size of a drawn symbol in (1+ symbol_radius) pixels
symbol_thickness: 0, // The thinkness of a drawn symbol in (1 + symbol_thickness) pixels
best_fit: None, // A curve to fit to the axes. Some(BestFit) or None
),
],
)
您的csv数据可能看起来像(注意列之间没有空白!)
x,y
0.5,0.5
1.0,1.0
1.5,1.5
在一个目录中,您可能有
- my_config.ron
- data.csv
要生成png,您可以在目录中运行 plotrs -g scatter -c my_config.ron,它将在文件旁边写入png。
符号类型/颜色
以下符号可用于绘制数据点
- 十字
- 圆圈
- 三角形
- 正方形
- 点
以下颜色
- 白色
- 黑色
- 灰色
- 橙色
- 红色
- 蓝色
- 绿色
- 粉色
最佳拟合方案
每个数据集定义也可以指定要绘制的最佳拟合线。在下面的示例中,数据集很小,符号被着色为白色以隐藏在背景画布上,它们实际上只是定义了坐标轴的范围,以展示最佳拟合。
线性
y = gradient * x + y_intercept
一些(线性(渐变: 1.0,y轴截距: 0.0,颜色:黑色))

二次方程
y = intercept + (linear_coeff * x) + (quadratic_coeff * x.powf(2))
一些(二次方程(截距: 1.0,线性系数: 0.0,二次系数: 1.0,颜色:黑色))
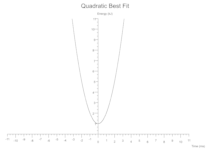
三次方程
y = intercept + (linear_coeff * x) + (quadratic_coeff * x.powf(2)) + + (cubic_coeff * x.powf(3))
一些(三次方程(截距: 1.0,线性系数: -0.5,二次系数: 1.0,三次系数: 1.0,颜色:黑色))

通用多项式
对于自定义多项式,您需要提供一个系数映射,其中每个键是nth次幂x将被提升,值是要与之相乘的系数。
大约
for (k, v) in coefficients.iter() {
y += v * x.powf(k);
}
以下将三次最佳拟合扩展为四次多项式
一些(通用多项式(系数: {0: 1.0, 1: 1.0, 2: 1.0, 3: 1.0, 4: -1.0},颜色:黑色))
这在人眼中看起来有点像:1 + x + x^2 + x^3 - x^4。

指数
y = (constant * base.powf(power * x)) + vertical_shift;
一些(指数(常数: 0.5,基数: 2.7,幂: -1.0,垂直位移: 3.0,颜色:黑色))
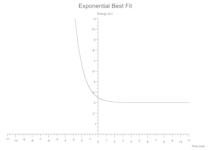
高斯
`y = (variance * (2.0 * PI).sqrt()).powf(-1.0) * E.powf(-(x - expected_value).powf(2.0) / (2.0 * variance.powf(2.0)))`
一些(高斯(期望值: 0.0,方差: 0.3,颜色:黑色))

正弦波
y = amplitude * ((period * x) + phase_shift).sin() + vertical_shift;
一些(正弦(振幅: 2.0,周期: 1.0,相位位移: 0.0,垂直位移: 3.0,颜色:黑色))
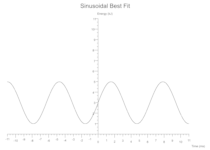
余弦波
y = amplitude * ((period * x) + phase_shift).cos() + vertical_shift;
一些(余弦(振幅: 2.0,周期: 1.0,相位位移: 0.0,垂直位移: 3.0,颜色:黑色))
示例
简单散点图
图像尺寸动态缩放元素
基于图像尺寸(canvas_size)自动计算文本和坐标轴位置。您还可以切换从坐标轴比例绘制的浅灰色背景网格。
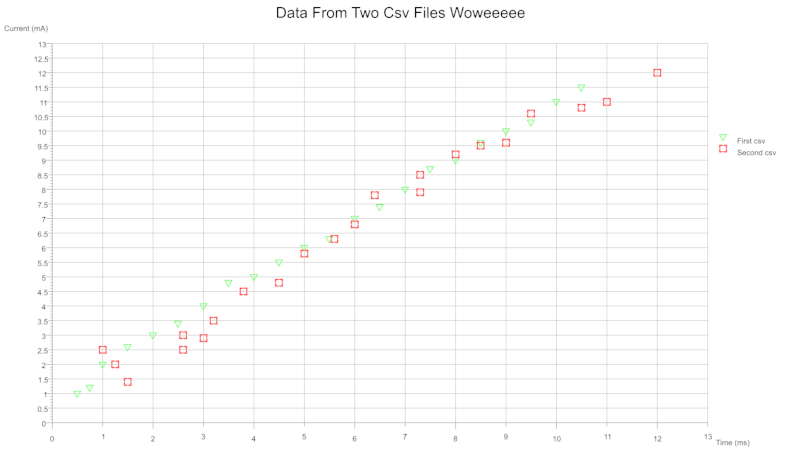
散点多数据
从单个或多个csv文件中,您可以在单个图表上绘制多个数据集。每个数据集可以配置为使用不同的颜色和/或符号。图例可以切换开启和关闭。符号的大小和厚度可以按数据集配置。
从包含多个数据集的多列csv中
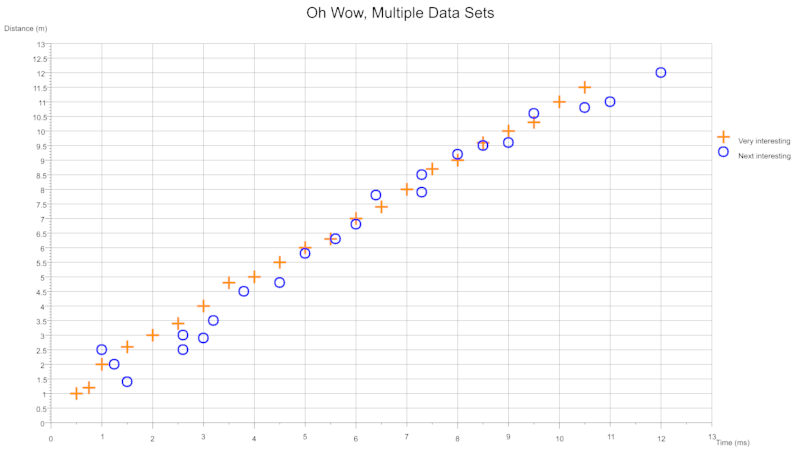
从包含成对列的两个csv文件中
散点误差线
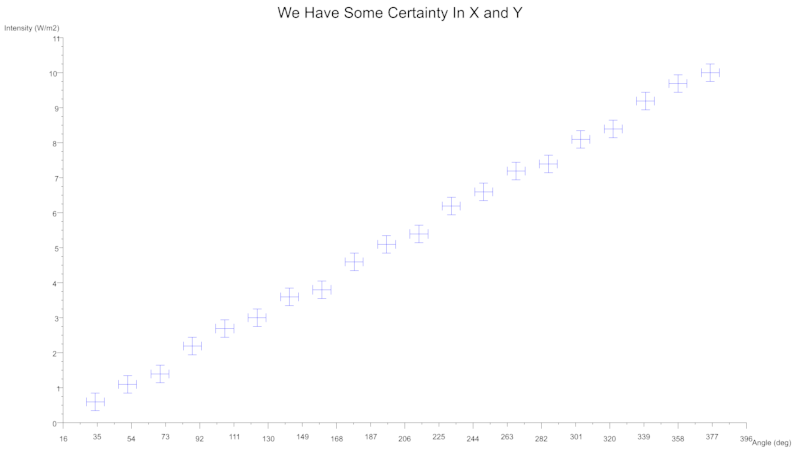
您还可以使用误差线来表示不确定性,可以为任一坐标轴指定误差线。
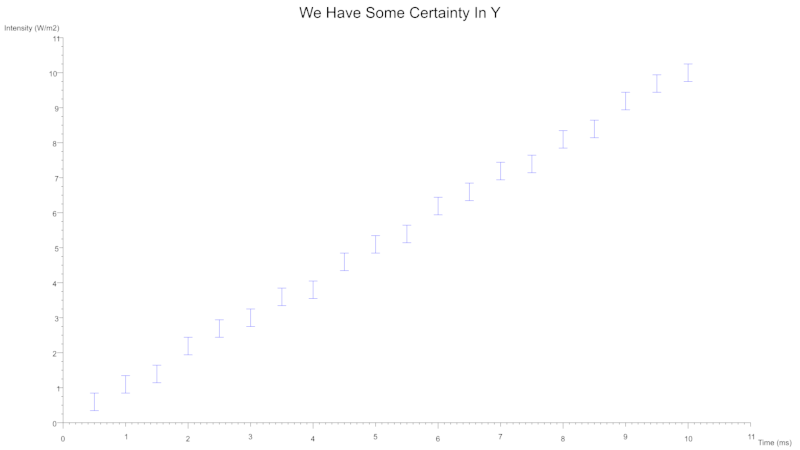
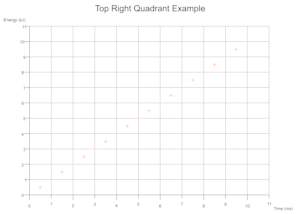
根据数据得出的象限
根据给定数量的数据集的值范围,在执行过程中确定所需的笛卡尔象限,并将比例标记和坐标轴标签适当地移动。
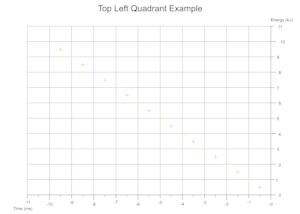
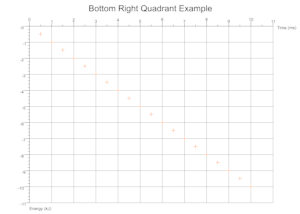
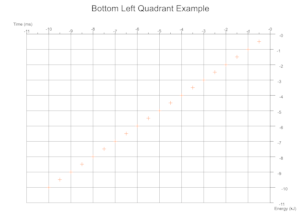
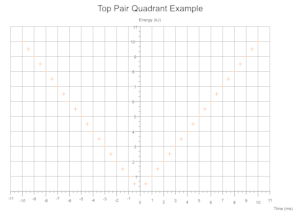
故障排除
轴上的数字很长,相互重叠
尝试将x和y轴分辨率更改为是您最大值加10%的因数的数字。在幕后发生的事情是在数据集中找到最大值并稍微缩放,这样数据点就不会直接绘制在轴上,从而遮挡一些文本/标记。当绘制坐标轴时,它具有一定的像素长度,分辨率决定了它被分割成多少次以显示比例标记。要将数据值(f32)映射到像素(u32),有一个转换,其中单个像素代表某些值或长度的数据。对于尴尬的分辨率,两个比例标记之间的像素长度可能是一个长浮点数而不是四舍五入的整数。
例如,如果您的数据中最大的 x 值是 10,请尝试将 x_axis_resolution 设置为 10 * 1.1 = 11,这将生成 11 个整数的刻度标记。同样,分辨率为 22 也会生成同样好的标记,因为 11 可以完美地放入 22。
标题/轴标签/图例模糊不清
如果文字边缘变得模糊,请尝试增加画布的大小。
贡献
- 如果您对某些内容不确定,请先提出问题。
- 分支它
- 使用键盘上的Tippy tap
- 提交一个PR
许可协议
待办事项
- 在图例中显示BestFit类型
- 允许覆盖字体
- 检查子集和加法以确保u32像素不会溢出,可能吗?
- 将绘制方法拆分/简化,然后添加一亿个测试,许多关于位置计算
- 哪些方法和模块可以用来绘制其他图表类型...
依赖项
~19–30MB
~311K SLoC