36个版本
| 0.9.1 | 2021年6月23日 |
|---|---|
| 0.8.2 | 2021年5月9日 |
| 0.7.0 | 2021年1月30日 |
| 0.6.5 | 2020年11月27日 |
| 0.1.0 | 2018年12月27日 |
#1030 in 图形API
11,174 每月下载量
用于135 个crate(直接使用10个)
795KB
16K SLoC
gfx-backend-metal
Metal后端用于gfx-rs。
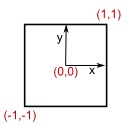
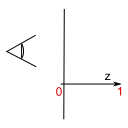
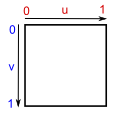
归一化坐标
| 渲染 | 深度 | 纹理 |
|---|---|---|
 |
 |
 |
绑定模型
模型尺寸
- 着色器阶段:vs, fs, cs
- 寄存器:缓冲区、纹理、采样器
- 绑定:0..31缓冲区,0..128纹理,0..16采样器
镜像
待办事项
lib.rs:
Metal后端内部结构。
管道布局
在Metal中,推送常量、顶点缓冲区和描述符集中的资源都放在本机资源绑定中,这与D3D11类似:有纹理、缓冲区和采样器的表。
我们在表中首先放置推送常量(如果有),然后是描述符集0资源,然后是其他描述符集。顶点缓冲区绑定在VS缓冲区表的最后。
当支持参数缓冲区时,每个描述符集成为缓冲区绑定,但一般放置规则是相同的。
命令记录
一次性提交主命令缓冲区实时记录到MTLCommandBuffer。特别关注记录状态:在任何渲染或计算阶段开始时恢复活动绑定。
多次提交和二级命令缓冲区被记录为“软”命令到Journal中。实际的本地记录是在相应的submit或execute_commands时进行的。当发生这种情况时,我们在记录开始时将命令缓冲区enqueue,这允许驱动程序在我们记录后续传递的同时进行传递转换。
内存
一般来说,“共享”存储用于CPU一致性内存。“管理”用于非一致性CPU可见内存。最后,“私有”存储支持设备本地内存类型。
Metal没有用于纹理的CPU可见内存。我们只允许从其中分配RGBA8 2D纹理,并且仅用于传输操作,这是Vulkan所需的最小值。实际上,这些变成了盛大的阶段缓冲区。
事件
事件由一个原子bool表示。在记录时,命令缓冲区会跟踪所有设置或重置的事件。因此,命令缓冲区内的信号是一个简单地检查本地列表的问题。在提交时,也会暂时累积使用的事件,这样我们就可以在最后一个命令缓冲区的完成处理程序中更改它们的值。我们还检查这个列表,以解决同一提交中一个命令缓冲区中触发的事件和另一个命令缓冲区中等待的事件。
等待来自不同提交的事件与等待主机的方式类似。我们阻塞所有提交,直到主机阻塞器得到解决,这些在设置事件、设备等待栅栏等特定点进行检查。
依赖关系
~10–21MB
~263K SLoC