20个版本 (12个重大更新)
| 0.13.2 | 2024年5月3日 |
|---|---|
| 0.12.1 | 2024年2月1日 |
| 0.11.1 | 2023年12月4日 |
| 0.10.0 | 2023年10月24日 |
| 0.1.0 | 2022年7月27日 |
#13 in 机器学习
8,142 每月下载量
在 12 个crate(11 个直接使用) 中使用
755KB
17K SLoC
![]()
![]()
![]()
![]()
![]()
Burn 是一个使用 Rust 构建的全新全面动态深度学习框架
其主要目标是极端的灵活性、计算效率和可移植性。
性能

因为我们相信深度学习框架的目标是将计算转化为有用的智能,所以我们将性能作为 Burn 的核心支柱。我们通过利用以下描述的多种优化技术,努力实现顶级效率。
点击每个部分获取更多详细信息 👇
自动内核融合 💥
使用 Burn 意味着可以在任何后端优化您的模型。当可能时,我们提供了一种自动和动态创建自定义内核的方法,以最小化不同内存空间之间的数据移动,这在内存移动是瓶颈时非常有用。
例如,您可以使用高级张量 API 编写自己的 GELU 激活函数(请参见下面的 Rust 代码片段)。
fn gelu_custom<B: Backend, const D: usize>(x: Tensor<B, D>) -> Tensor<B, D> {
let x = x.clone() * ((x / SQRT_2).erf() + 1);
x / 2
}
然后,在运行时,将为您的特定实现自动创建一个自定义的低级内核,其性能将与手工编写的 GPU 实现相媲美。该内核由大约 60 行 WGSL WebGPU 着色语言 组成,这是一种极其冗长的底层着色语言,您可能不希望用它来编写深度学习模型!
到目前为止,我们的融合策略仅适用于我们自己的 WGPU 后端,并且仅支持部分操作。我们计划很快添加更多操作,并将此技术扩展到其他未来的内部后端。
异步执行 ❤️🔥
对于 Burn 团队从头开始开发的后端,使用异步执行风格,这允许执行各种优化,例如之前提到的自动内核融合。
异步执行还确保框架的正常执行不会阻塞模型计算,这意味着框架开销不会对执行速度产生显著影响。相反,模型中的密集计算也不会干扰框架的响应性。有关我们异步后端的信息,请参阅这篇博客文章。
线程安全构建块 🦞
Burn通过利用Rust的所有权系统来强调线程安全。在Burn中,每个模块都是其权重的所有者。因此,可以将一个模块发送到另一个线程进行梯度计算,然后将梯度发送到可以聚合它们的主线程,voilà,您就得到了多设备训练。
这与PyTorch所采取的方法非常不同,在PyTorch中,反向传播实际上会改变每个张量参数的grad属性。这不是一个线程安全的操作,因此需要较低级别的同步原语,有关参考,请参阅分布式训练。请注意,这仍然非常快,但不同后端之间不兼容,并且很难实现。
智能内存管理 🦀
深度学习框架的主要作用之一是减少运行模型所需的内存量。处理内存的简单方法是每个张量都有自己的内存空间,张量创建时分配内存,张量超出作用域时释放内存。然而,分配和释放数据非常昂贵,因此通常需要一个内存池来达到良好的吞吐量。Burn提供了一个基础设施,可以轻松创建和选择后端内存管理策略。有关Burn中内存管理的更多详细信息,请参阅这篇博客文章。
Burn的另一个非常重要的内存优化是我们通过良好的所有权系统跟踪张量何时可以进行就地修改。尽管这本身是一个相当小的内存优化,但在训练或运行大型模型进行推理时,它会产生相当大的影响,从而进一步减少内存使用。有关更多信息,请参阅关于张量处理的这篇博客文章。
自动内核选择 🎯
一个好的深度学习框架应该确保模型在所有硬件上都能平稳运行。然而,并非所有硬件在执行速度方面都有相同的行为。例如,矩阵乘法内核可以以许多不同的参数启动,这些参数对矩阵的大小和硬件非常敏感。使用错误的配置可能会大大降低执行速度(在极端情况下,可能降低10倍甚至更多),因此选择正确的内核变得至关重要。
使用我们自制的后端,我们自动运行基准测试,并使用合理的缓存策略为当前硬件和矩阵大小选择最佳配置。
这会增加少量的开销,因为会增加预热执行时间,但在经过几次正向和反向传递后,会迅速稳定下来,从长远来看节省了大量时间。请注意,此功能不是强制的,可以在冷启动优先于优化吞吐量时禁用。
特定硬件的功能 🔥
深度学习主要依赖于矩阵乘法作为其核心操作,因为这是全连接神经网络的建模方式,这并不是什么秘密。
越来越多的硬件制造商针对矩阵乘法工作负载优化他们的芯片。例如,Nvidia有它的Tensor Cores,而今天的大多数手机都有AI专用芯片。到目前为止,我们支持Tensor Cores,使用LibTorch和Candle后端,但尚未支持其他加速器。我们希望这个问题在某个时候得到解决,以便为我们的WGPU后端提供支持。
自定义后端扩展 🎒
“Burn”旨在成为最灵活的深度学习框架。虽然保持与各种后端的兼容性至关重要,但“Burn”还提供了扩展后端实现功能的能力,以满足您个人建模需求。
这种多功能性在许多方面都有优势,例如支持自定义操作,如闪存注意力,或手动为特定后端编写自己的内核以提高性能。更多详情请参阅《Burn Book》中的这一部分 🔥。
训练 & 推理

使用“Burn”,整个深度学习工作流程都变得简单,您可以使用用户友好的仪表板监控训练进度,并在从嵌入式设备到大型GPU集群的任何地方运行推理。
“Burn”从头开始构建时考虑了训练和推理。值得注意的是,与PyTorch等框架相比,“Burn”简化了从训练到部署的过渡,消除了代码更改的需要。
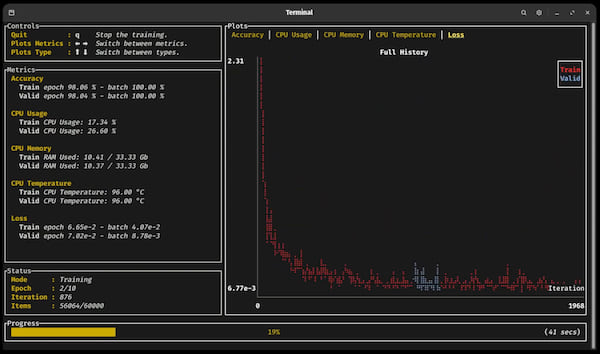
点击以下部分以展开 👇
训练仪表板 📈
正如您在前面的视频中看到的(点击图片!)基于Ratatui的终端UI仪表板允许用户轻松跟踪训练,而无需连接到任何外部应用程序。
您可以在实时中可视化训练和验证指标更新,并使用箭头键分析任何注册指标的终身进展或最近历史。中断训练循环而不会崩溃,允许潜在检查点完整写入或重要代码片段完成,而不会中断 🛡
ONNX支持 🐫
ONNX(开放神经网络交换)是一种开放标准格式,可以导出深度学习模型的架构和权重。
“Burn”支持导入遵循ONNX标准的模型,这样您就可以轻松地将您在其他框架(如TensorFlow或PyTorch)中编写的模型移植到“Burn”,以利用我们框架提供的所有优势。
我们将在《Burn Book》的这一部分进一步描述我们的ONNX支持 🔥。
注意:此包正在积极开发中,目前支持有限集的ONNX运算符。
浏览器中的推理 🌐
我们的几个后端可以编译为Web Assembly:Candle和NdArray用于CPU,WGPU用于GPU。这意味着您可以直接在浏览器中运行推理。我们提供了几个示例
后端
 Burn致力于在尽可能多的硬件上以尽可能快的速度运行,并具有稳健的实现。我们相信这种灵活性对于现代需求至关重要,因为在云中训练模型后,您可以在客户硬件上部署,这些硬件因用户而异。
Burn致力于在尽可能多的硬件上以尽可能快的速度运行,并具有稳健的实现。我们相信这种灵活性对于现代需求至关重要,因为在云中训练模型后,您可以在客户硬件上部署,这些硬件因用户而异。与其他框架相比,Burn支持许多后端的方法非常不同。按照设计,大多数代码在Backend trait上是通用的,这使我们能够使用可互换的后端构建Burn。这使得后端的组合成为可能,并增加额外的功能,如自动微分和自动内核融合。
我们已实现了许多后端,所有这些都在下面列出 👇
WGPU(WebGPU):跨平台GPU后端 🌐
适用于在任何GPU上运行的首选后端。
基于最受欢迎且支持良好的Rust图形库WGPU,此后端通过使用WebGPU着色语言WGSL自动针对Vulkan、OpenGL、Metal、Direct X11/12和WebGPU。它还可以编译为Web Assembly以在浏览器中运行,同时利用GPU,请参见此演示。有关此后端的更多优点信息,请参阅此博客。
WGPU后端是我们的第一个“内部后端”,这意味着我们对其实现细节有完全控制权。它完全优化了前面提到的性能特征,因为它是我们进行各种优化的研究游乐场。
有关更多信息,请参阅WGPU后端README。
Candle:使用Candle绑定后端 🕯
基于Hugging Face的Candle,这是一个专注于性能和易用性的Rust极简主义机器学习框架,此后端可以在CPU上运行,支持Web Assembly,或在Nvidia GPU上使用CUDA。
有关更多信息,请参阅Candle后端README。
免责声明: 此后端尚未完全完成,但在某些上下文中(如推理)可以工作。
LibTorch:使用LibTorch绑定后端 🎆
PyTorch在深度学习领域无需介绍。此后端利用PyTorch Rust绑定,使您能够在CPU、CUDA和Metal上使用LibTorch C++内核。
有关更多信息,请参阅LibTorch后端README。
NdArray:使用NdArray原语作为数据结构后端 🦐
这个CPU后端承认并不是我们最快的后端,但提供了极致的可移植性。
它是唯一支持no_std的后端。
有关更多信息,请参阅NdArray后端README。
Autodiff:将反向传播引入任何后端的装饰器 🔄
与上述后端不同,Autodiff实际上是一个装饰器。这意味着它不能单独存在;它必须封装另一个后端。
仅仅将Autodiff包装到基本后端,就可以透明地为其配备自动微分支持,使调用模型上的反向操作成为可能。
use burn::backend::{Autodiff, Wgpu};
use burn::tensor::{Distribution, Tensor};
fn main() {
type Backend = Autodiff<Wgpu>;
let x: Tensor<Backend, 2> = Tensor::random([32, 32], Distribution::Default);
let y: Tensor<Backend, 2> = Tensor::random([32, 32], Distribution::Default).require_grad();
let tmp = x.clone() + y.clone();
let tmp = tmp.matmul(x);
let tmp = tmp.exp();
let grads = tmp.backward();
let y_grad = y.grad(&grads).unwrap();
println!("{y_grad}");
}
值得注意的是,对于在不支持自动微分(推理)的后端上运行的模式,不可能犯调用向后的错误,因为此方法仅由自动微分后端提供。
有关更多详细信息,请参阅自动微分后端README。
融合:为支持其的后端提供内核融合的后端装饰器 💥
此后端装饰器增强了后端的功能,前提是内部后端支持。请注意,您可以将其与其他后端装饰器(如自动微分)组合使用。目前,只有WGPU后端支持融合内核。
use burn::backend::{Autodiff, Fusion, Wgpu};
use burn::tensor::{Distribution, Tensor};
fn main() {
type Backend = Autodiff<Fusion<Wgpu>>;
let x: Tensor<Backend, 2> = Tensor::random([32, 32], Distribution::Default);
let y: Tensor<Backend, 2> = Tensor::random([32, 32], Distribution::Default).require_grad();
let tmp = x.clone() + y.clone();
let tmp = tmp.matmul(x);
let tmp = tmp.exp();
let grads = tmp.backward();
let y_grad = y.grad(&grads).unwrap();
println!("{y_grad}");
}
值得注意的是,我们计划根据计算边界和内存边界操作实现自动梯度检查点,这将与融合后端配合工作,使您的代码在训练期间运行速度更快,请参阅此问题。
有关更多详细信息,请参阅融合后端README。
入门指南

刚刚听说Burn?您来对地方了!只需继续阅读本节,我们希望您能快速加入。
《Burn手册 🔥》
要有效地开始使用Burn,了解其关键组件和理念至关重要。这就是我们强烈建议新用户阅读《Burn手册 🔥》的前几节。它提供了详细的示例和解释,涵盖了框架的各个方面,包括从张量、模块和优化器等构建块到编写自己的GPU内核等高级用法。
项目不断演变,我们尽可能地保持手册与新的增补保持更新。然而,我们有时可能会错过一些细节,所以如果您看到什么奇怪的地方,请告诉我们!我们也很乐意接受Pull Requests 😄
示例 🙏
让我们从一个代码片段开始,展示这个框架的使用是多么直观!在下面的示例中,我们声明了一个带有一些参数的神经网络模块及其正向传递。
use burn::nn;
use burn::module::Module;
use burn::tensor::backend::Backend;
#[derive(Module, Debug)]
pub struct PositionWiseFeedForward<B: Backend> {
linear_inner: nn::Linear<B>,
linear_outer: nn::Linear<B>,
dropout: nn::Dropout,
gelu: nn::Gelu,
}
impl<B: Backend> PositionWiseFeedForward<B> {
pub fn forward<const D: usize>(&self, input: Tensor<B, D>) -> Tensor<B, D> {
let x = self.linear_inner.forward(input);
let x = self.gelu.forward(x);
let x = self.dropout.forward(x);
self.linear_outer.forward(x)
}
}
我们在存储库中有一个相当多的示例,展示了如何在不同场景中使用框架。为了获得更实际的见解,您可以克隆存储库并在您的计算机上直接运行其中的任何示例!
预训练模型 🤖
我们维护了一个最新且经过精心挑选的模型和示例列表,它们都是用Burn构建的,请参阅tracel-ai/models存储库以获取更多详细信息。
没有看到您想要的模型?请毫不犹豫地提出问题,我们可能会优先处理。使用Burn构建了模型并想分享?您也可以打开Pull Request,并在社区部分添加您的模型!
为什么使用Rust进行深度学习? 🦀
深度学习是一种特殊的软件形式,您需要非常高级的抽象以及非常快的执行时间。Rust是这种用例的完美候选者,因为它提供了零成本抽象,可以轻松创建神经网络模块,并对内存进行精细控制以优化每个细节。
一个框架在高级别上易于使用非常重要,这样其用户就可以专注于在AI领域进行创新。然而,由于运行模型如此严重依赖于计算,性能不能被忽视。
到目前为止,解决此问题的主流解决方案一直是提供Python API,但依赖于绑定到底层语言(如C/C++)的低级语言。这减少了可移植性,增加了复杂性,并在研究人员和工程师之间产生了摩擦。我们认为Rust对抽象的方法使其足够灵活,可以解决这种两种语言的二分法。
Rust 还自带了 Cargo 包管理器,这使得在任何环境下构建、测试和部署都变得极其容易,这在 Python 中通常是一个头疼的问题。
尽管 Rust 最初以难学而著称,但我们坚信它能够带来更可靠、无错误且构建速度更快的解决方案(在练习一段时间后 😅)!
社区

如果你对这个项目感到兴奋,请不要犹豫,加入我们的 Discord!我们尽力对来自任何背景的每个人都很欢迎。你可以向社区提问并分享你构建的内容!
贡献
在贡献之前,请花点时间审查我们的 行为准则。还强烈建议您阅读我们的 架构文档,其中解释了我们的部分架构决策。有关更多详细信息,请参阅我们的 贡献指南。
状态
Burn 目前正在积极开发中,将会出现重大变更。尽管任何导致的问题可能很容易解决,但目前没有保证。
许可证
Burn 在 MIT 许可证和 Apache 许可证(版本 2.0)的条款下分发。有关详细信息,请参阅 LICENSE-APACHE 和 LICENSE-MIT。提交拉取请求被视为对这些许可条款的同意。
依赖项
~38–87MB
~1.5M SLoC