64个版本 (33个稳定版)
| 新 3.5.0 | 2024年8月22日 |
|---|---|
| 3.2.0 | 2024年7月25日 |
| 2.14.0 | 2024年6月28日 |
| 2.7.1 | 2024年3月28日 |
| 0.9.2 | 2023年9月10日 |
#87 在 数据结构
每月下载量 2,553
用于 9 crates
255KB
4.5K SLoC
orx-split-vec
![]()
![]()
具有动态容量和固定元素的效率高且常量访问时间的向量。
B. 动机
在许多情况下,固定元素是至关重要的。
- 它对于实现使用瘦引用的**高效、便捷和安全的自引用集合**至关重要,详见
SelfRefCol,以及其特殊情况,如LinkedList。 - 对于**并发**程序很重要,因为它消除了与元素隐式携带到不同内存位置相关的安全担忧。这有助于减少和解决并发复杂性,并导致高效的并发数据结构。参见
ConcurrentIter、ConcurrentBag或ConcurrentOrderedBag,这些并发数据结构可以方便地构建在固定向量的固定元素保证之上。 - 它对于允许**不可变推送**向量至关重要;即
ImpVec。当所需的集合是一个物品的包或容器,而不是具有集体意义时,这是一个非常有用的操作。在这种情况下,ImpVec允许避免某些借用检查器的复杂性、堆分配和宽指针,如Box或Rc或等等。
C. 与 FixedVec 的比较
FixedVec 是另一个旨在实现相同目标但具有不同特性的 PinnedVec 实现。您可以在下表中进行比较。
FixedVec |
SplitVec |
|---|---|
实现了 PinnedVec => 可以被 ImpVec 或 SelfRefCol 或 ConcurrentBag 等包装。 |
实现了 PinnedVec => 也可以被它们包装。 |
| 创建时需要确切知道容量。 | 可以根据对所需容量的任何水平的前置信息来创建。 |
容量不能超出;当在容量时调用push时,会引发恐慌。 |
可以动态增长。此外,它还提供了控制其如何增长的能力。 |
它只是std::vec::Vec的一个包装;因此,具有等效的性能。 |
性能优化的内置增长策略也具有与std::vec::Vec等效的性能。 |
对SplitVec进行性能优化后,它在性能方面现在可以与std::vec::Vec相媲美(请参阅E. 基准测试中的实验)。这可能会使SplitVec成为比FixedVec更具主导性的选择。
C. 带有固定元素的扩展
正如其名所示,SplitVec是一种表示为多个连续数据片段序列的向量。
当所有片段都完全被利用时,向量被认为处于其容量。当向量在容量时需要进一步增长时,会分配一个新的片段。因此,增长不需要将内存复制到新的内存位置。已经推送的元素保持在它们的内存位置上。
C.1. 可用增长策略:Linear | Doubling | Recursive
新片段的容量由选择的增长策略确定。假设vec: SplitVec<_, G>其中G: Growth包含一个容量为C的片段,这也是向量的容量,因为它是唯一的片段。假设,我们用完了所有容量;即vec.len() == vec.capacity()(C)。如果我们尝试推送一个新的元素,SplitVec将分配具有以下容量的第二个片段
Growth 策略 |
1st 片段容量 | 2nd 片段容量 | 向量容量 |
|---|---|---|---|
线性 |
C |
C |
2 *C |
加倍 |
C |
2 *C |
3 *C |
C被初始化为2的幂,用于Linear策略,并且在Doubling策略中固定为4,以允许进行访问时间优化。
此外,还存在Recursive增长策略,它在开始时表现为Doubling策略。然而,它以降低随机访问时间性能为代价,允许无成本的append操作。
允许常数时间随机访问的增长策略还实现了GrowthWithConstantTimeAccess特质,这些当前是Doubling和Linear策略。
请参阅E. 基准测试部分以获取权衡和详细信息。总结如下
- 当需要固定元素并且我们需要接近标准向量串行和随机访问性能时,请使用
SplitVec<T, Doubling>(或等价地SplitVec<T>)- 或
- 当元素很大且我们没有良好的容量估计时,我们可以从分割向量的无复制增长中受益。
- 使用
SplitVec<T, Recursive>- 当需要具有固定元素并且我们需要接近标准向量的串行访问性能,同时可以接受较慢的随机访问性能时,或者
- 当频繁且重要地执行向量的其他向量或分割向量的
append操作时。
- 当对增长的增长块大小有良好的想法时,使用
SplitVec<T, Linear>以减少std::vec::Vec或Doubling或Recursive的倍增带来的浪费容量。
C.2. 自定义增长策略
为了定义自定义增长策略,需要实现 Growth 特性。实现很简单。该特性包含两个方法。以下方法是必需的
fn new_fragment_capacity<T>(&self, fragments: &[Fragment<T>]) -> usize
请注意,它接受所有已分配的片段作为参数,并需要决定新片段的容量。
第二个方法 fn get_fragment_and_inner_indices<T>(&self, vec_len: usize, fragments: &[Fragment<T>], element_index: usize) -> Option<(usize, usize)> 有默认实现,如果策略允许高效地计算索引,则可以重写。
D. 示例
D.1. 与 std::vec::Vec 相似的使用
use orx_split_vec::*;
let mut vec = SplitVec::new();
vec.push(0);
vec.extend_from_slice(&[1, 2, 3]);
assert_eq!(vec, &[0, 1, 2, 3]);
vec[0] = 10;
assert_eq!(10, vec[0]);
vec.remove(0);
vec.insert(0, 0);
assert_eq!(6, vec.iter().sum());
assert_eq!(vec.clone(), vec);
let std_vec: Vec<_> = vec.into();
assert_eq!(&std_vec, &[0, 1, 2, 3]);
D.2. SplitVec 特定操作
use orx_split_vec::*;
#[derive(Clone)]
struct MyCustomGrowth;
impl Growth for MyCustomGrowth {
fn new_fragment_capacity_from(&self, fragment_capacities: impl ExactSizeIterator<Item = usize>) -> usize {
fragment_capacities.last().map(|f| f + 1).unwrap_or(4)
}
}
impl PseudoDefault for MyCustomGrowth {
fn pseudo_default() -> Self {
MyCustomGrowth
}
}
// set the growth explicitly
let vec: SplitVec<i32, Linear> = SplitVec::with_linear_growth(4);
let vec: SplitVec<i32, Doubling> = SplitVec::with_doubling_growth();
let vec: SplitVec<i32, MyCustomGrowth> = SplitVec::with_growth(MyCustomGrowth);
// methods revealing fragments
let mut vec = SplitVec::with_doubling_growth();
vec.extend_from_slice(&[0, 1, 2, 3]);
assert_eq!(4, vec.capacity());
assert_eq!(1, vec.fragments().len());
vec.push(4);
assert_eq!(vec, &[0, 1, 2, 3, 4]);
assert_eq!(2, vec.fragments().len());
assert_eq!(4 + 8, vec.capacity());
// SplitVec is not contagious; instead a collection of contagious fragments
// so it might or might not return a slice for a given range
let slice: SplitVecSlice<_> = vec.try_get_slice(1..3);
assert_eq!(slice, SplitVecSlice::Ok(&[1, 2]));
let slice = vec.try_get_slice(3..5);
// the slice spans from fragment 0 to fragment 1
assert_eq!(slice, SplitVecSlice::Fragmented(0, 1));
let slice = vec.try_get_slice(3..7);
assert_eq!(slice, SplitVecSlice::OutOfBounds);
// or the slice can be obtained as a vector of slices
let slices = vec.slices(0..3);
assert_eq!(1, slices.len());
assert_eq!(slices[0], &[0, 1, 2]);
let slices = vec.slices(3..5);
assert_eq!(2, slices.len());
assert_eq!(slices[0], &[3]);
assert_eq!(slices[1], &[4]);
let slices = vec.slices(0..vec.len());
assert_eq!(2, slices.len());
assert_eq!(slices[0], &[0, 1, 2, 3]);
assert_eq!(slices[1], &[4]);
D.3. 固定元素
除非从向量中删除元素,否则已推送到 SplitVec 的元素的内存位置 永远不会 改变,除非明确更改。
use orx_split_vec::*;
let mut vec = SplitVec::new(); // Doubling growth as the default strategy
// split vec with 1 item in 1 fragment
vec.push(42usize);
assert_eq!(&[42], &vec);
assert_eq!(1, vec.fragments().len());
assert_eq!(&[42], &vec.fragments()[0]);
// let's get a pointer to the first element
let addr42 = &vec[0] as *const usize;
// let's push 3 + 8 + 16 new elements to end up with 3 fragments
for i in 1..(3 + 8 + 16) {
vec.push(i);
}
for (i, elem) in vec.iter().enumerate() {
assert_eq!(if i == 0 { 42 } else { i }, *elem);
}
// now the split vector is composed of 11 fragments each with a capacity of 10
assert_eq!(3, vec.fragments().len());
// the memory location of the first element remains intact
assert_eq!(addr42, &vec[0] as *const usize);
// we can safely dereference it and read the correct value
// dereferencing is still unsafe for SplitVec,
// but the underlying guarantee will be used by wrappers such as ImpVec or SelfRefCol
assert_eq!(unsafe { *addr42 }, 42);
E. 性能测试
回想一下,使用分割向量的动机是为了从固定元素中获得好处,并在特定情况下避免标准向量的内存复制;而不是作为替代品。性能优化和基准测试的目的是确保关键操作的性能保持在期望范围内。似乎 SplitVec 满足这一点。经过优化,内置增长策略在增长、串行访问和随机访问基准测试中似乎与 std::vec::Vec 的性能相似,在追加基准测试中表现更好。
您可以在以下子节中找到每个基准测试的详细信息。下面表格中的所有数字都表示以毫秒为单位的时间。
E.1. 增长
您可以在 benches/grow.rs 中看到基准测试。
该基准通过逐个推送元素来比较向量的构建时间。基线是通过std::vec::Vec::with_capacity创建的向量,它对要推送的元素数量有完美的信息。比较的变体是没有关于容量先验知识的向量:std::vec::Vec::new,SplitVec<_, Linear>和SplitVec<_, Doubling>。
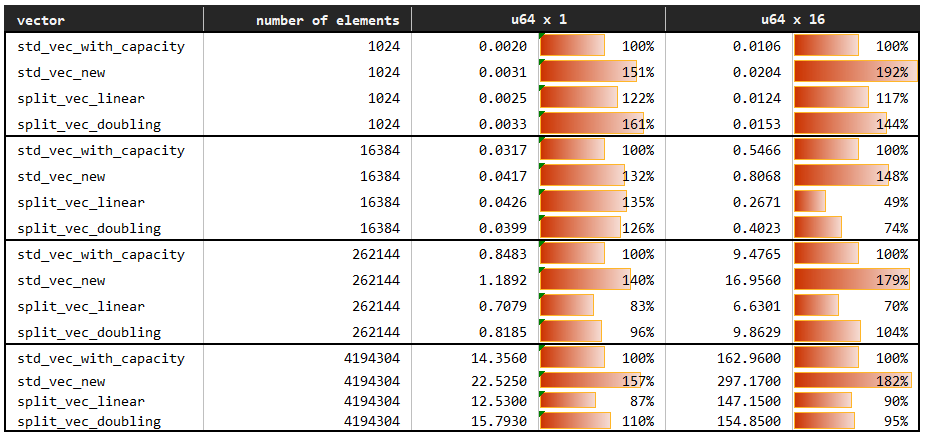
基线std_vec_with_capacity的性能比没有容量信息的std_vec_new快1.5到2.0倍,后者在增长时需要复制。如前所述,SplitVec的增长保证无复制,确保推送的元素保持固定。因此,预计其性能介于两者之间。然而,其性能几乎与std_vec_with_capacity相当,有时甚至更快。
由于Recursive策略的行为与Doubling策略完全相同,因此在此省略。关于其差异,请参阅随机访问和追加基准。
E.2. 随机访问
您可以在benches/random_access.rs中查看基准。
在此基准中,我们以随机顺序通过索引访问向量元素。这里基线再次是使用Vec::with_capacity创建的标准向量,它被与Linear和Doubling增长策略的SplitVec进行比较,这些策略专门针对随机访问进行了优化。此外,还包括了不提供常数时间随机访问操作的Recursive增长策略。
请注意,Recursive使用Growth特质的默认get_fragment_and_inner_indices实现,因此反映了没有专用访问方法的自定义增长策略的预期随机访问性能。
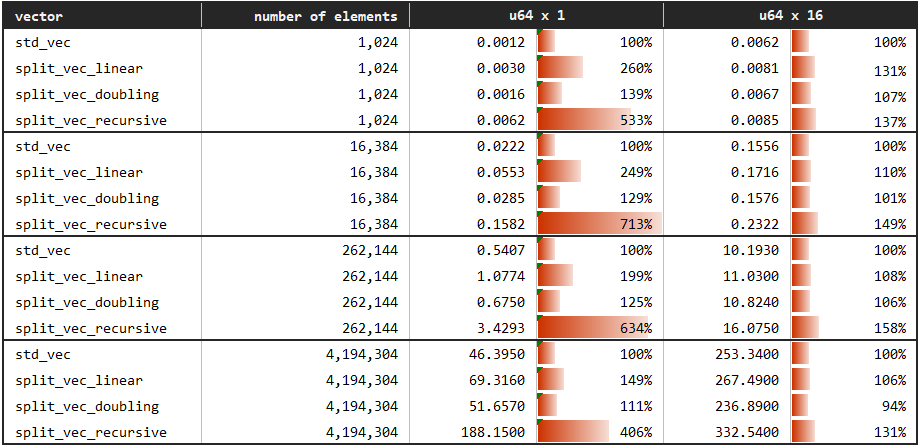
我们可以看到,Linear比Doubling慢。与标准向量相比,Doubling的随机访问性能最多慢50%,并且随着元素大小或元素数量的增加,差异趋于减小。
另一方面,Recursive没有常数时间复杂度的随机访问操作,这在表中可以观察到。对于小元素,它比慢速访问慢4到7倍,对于大型结构体,大约慢1.5倍。为了使权衡清晰简洁;SplitVec<_, Recursive>主要区别于标准和分割向量替代品在于随机访问性能(较差)和追加性能(较好)。
E.3. 串行访问
您可以在benches/serial_access.rs中查看基准。
在这里,我们测试了从第一个元素到最后一个元素按顺序访问向量每个元素的情况。我们使用相同的标准向量作为基线。为了完整性,基线与Doubling、Linear和Recursive增长策略进行比较;然而,SplitVec实际上使用相同的迭代器,以允许任何增长策略进行串行访问。
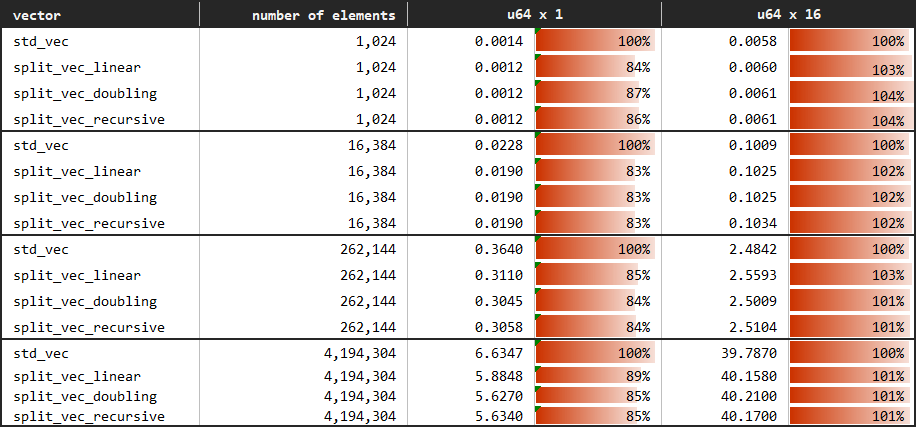
结果显示,这些变体之间存在细微的偏差,但并没有显著差异。
E.4. 附加内容
您可以在以下位置找到基准测试:benches/serial_access.rs。
在某些情况下,将向量添加到向量中可能是一个关键操作。一个例子是将树结构或链表或向量本身递归地添加到另一个中。我们可能将一个树添加到另一个树中以获得一个新的合并树。这种操作可以通过复制数据来保持所需的结构,或者简单地接受传入的块(无操作)。
std::vec::Vec<_>、SplitVec<_>和SplitVec<_, Linear>都通过保持其内部结构来进行此操作,从而允许高效的随机访问。SplitVec<_, Recursive>另一方面,利用其分块结构并采用后一种方法。因此,向其中添加另一个向量没有成本,即无操作。这不会降低串行访问性能。然而,它会导致随机访问变慢。请参考上面的对应基准测试。
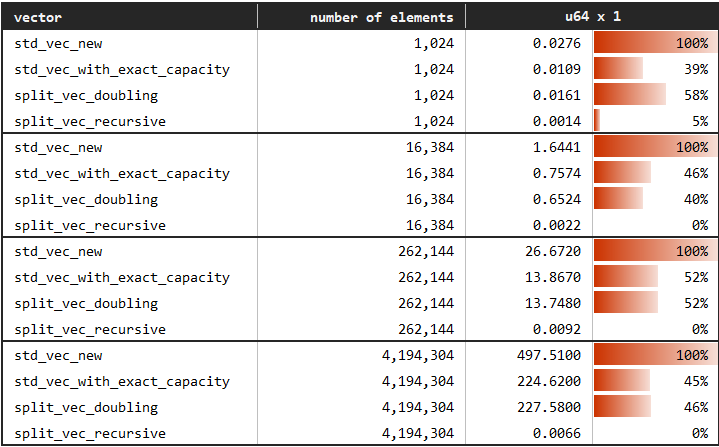
您可以看到,当没有关于所需容量的先验信息时,SplitVec<T, Doubling>(等价于使用默认值的SplitVec<T>)比std::vec::Vec快大约两倍。当我们拥有完美的信息,并使用std::vec::Vec::with_capacity创建我们的向量并提供确切的所需容量时,std::vec::Vec和SplitVec的表现是等效的。这使得SplitVec成为一个更佳的选择。
另一方面,SplitVec<T, Recursive>允许零成本的添加,且与要添加的数据的大小无关。
许可证
本库受MIT许可证许可。有关详细信息,请参阅LICENSE。