30 个版本 (13 个稳定版)
| 2.7.0 | 2024年8月12日 |
|---|---|
| 2.6.0 | 2024年7月25日 |
| 2.5.0 | 2024年6月15日 |
| 2.3.0 | 2024年3月24日 |
| 0.8.5 | 2023年9月14日 |
#151 in 数据结构
每月301次下载
165KB
2.5K SLoC
orx-linked-list
![]()
![]()
高效的递归单链表和双链表实现。
- 高效:请参阅基准测试部分以获取常见链表操作的性能报告。此外,
List实现通过使用NodeIndex强调了安全常数时间访问和修改。 - 单链或双链:这是
List的泛型参数。正如预期的那样,Doubly允许比Singly更多操作;然而,它每个节点保持两个引用而不是一个。 - 递归:
List允许通过在常数时间内组合两个链表来创建列表。
变体
List<Variant, T>其中T是元素类型List<Singly, T>:是单链表,其中每个节点都包含对下一个节点的引用。- 这等同于
List<Singly<MemoryReclaimOnThreshold<2>>, T>。 - 另一种内存策略是
List<Singly<MemoryReclaimNever>, T>。
- 这等同于
List<Doubly, T>:是双链表,其中每个节点都包含对前一个和下一个节点的引用。- 这等同于
List<Doubly<MemoryReclaimOnThreshold<2>>, T>。 - 另一种内存策略是
List<Doubly<MemoryReclaimNever>, T>。
- 这等同于
有关可能的内存管理策略,请参阅高级用法部分。
方法的时间复杂度
为了表示仅适用于Doubly链表,而不适用于Singly的方法,使用了(d)指示符。
以下是一系列具有常数时间复杂度O(1)的方法列表。
| O(1)方法 |
|---|
front, back:访问列表的前端和后端 |
get:访问给定索引的任何节点 |
push_front, push_back:向列表前端或后端(d)添加元素 |
pop_front, pop_back:从列表前端和后端(d)弹出元素 |
insert_prev_to, insert_next_to:在给定索引的现有节点之前或之后插入一个值(d) |
append_front, append_back:将另一个列表追加到列表的前端或后端 |
iter, iter_from_back:从列表的前端或后端(d)创建迭代器;迭代的时间复杂度为O(n) |
iter_forward_from, iter_backward_from:从给定索引的任何中间节点创建向前或向后(d)迭代器;迭代的时间复杂度为O(n) |
| O(n)方法 |
|---|
index_of:获取元素的索引,该索引可稍后用于O(1)方法 |
contains, position_of:检查值的存在的或位置 |
insert_at:将元素插入列表的任意位置 |
remove_at:从列表的任意位置删除元素 |
iter, iter_from_back:从前端或后端(d)迭代列表 |
iter_forward_from, iter_backward_from:从给定索引的任何中间节点向前或向后(d)迭代 |
retain, retain_collect:保留满足谓词的元素,并可选地收集删除的元素 |
示例
常见用法
orx_linked_list::List提供了常见的链表功能,特别强调保持数据结构的递归性质,这允许以常数时间合并列表。
use orx_linked_list::*;
fn eq<'a, I: Iterator<Item = &'a u32> + Clone>(iter: I, slice: &[u32]) -> bool {
iter.clone().count() == slice.len() && iter.zip(slice.iter()).all(|(a, b)| a == b)
}
let _list: List<Singly, u32> = List::new();
let _list: List<Doubly, u32> = List::new();
let mut list = List::<Doubly, _>::from_iter([3, 4, 5]);
assert_eq!(list.front(), Some(&3));
assert_eq!(list.back(), Some(&5));
assert!(eq(list.iter(), &[3, 4, 5]));
assert!(eq(list.iter_from_back(), &[5, 4, 3]));
assert_eq!(list.pop_front(), Some(3));
assert_eq!(list.pop_back(), Some(5));
list.push_back(5);
list.push_front(3);
assert!(eq(list.iter(), &[3, 4, 5]));
let other = List::<Doubly, _>::from_iter([6, 7, 8, 9]);
list.append_back(other);
assert!(eq(list.iter(), &[3, 4, 5, 6, 7, 8, 9]));
let other = List::<Doubly, _>::from_iter([0, 1, 2]);
list.append_front(other);
assert!(eq(list.iter(), &[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]));
list.retain(&|x| x < &5);
assert!(eq(list.iter(), &[0, 1, 2, 3, 4]));
let mut odds = vec![];
let mut collect_odds = |x| odds.push(x);
list.retain_collect(&|x| x % 2 == 0, &mut collect_odds);
assert!(eq(list.iter(), &[0, 2, 4]));
assert!(eq(odds.iter(), &[1, 3]));
NodeIndex使用方法
NodeIndex允许在常时间内以安全保证对集合进行索引。由增长方法(如push_back或append_next_to)返回的索引可以存储在外部。否则,可以使用index_of方法以线性时间搜索并获取值的索引。您可能已看到,这些索引使常数时间访问和修改方法成为可能。
use orx_linked_list::*;
fn eq<'a, I: Iterator<Item = &'a char> + Clone>(iter: I, slice: &[char]) -> bool {
iter.clone().count() == slice.len() && iter.zip(slice.iter()).all(|(a, b)| a == b)
}
let mut list = List::<Doubly, _>::from_iter(['a', 'b', 'c', 'd']);
let x = list.index_of(&'x');
assert!(x.is_none());
let maybe_b = list.index_of(&'b'); // O(n)
assert!(maybe_b.is_some());
let b = maybe_b.unwrap();
let data_b = list.get(b); // O(1)
assert_eq!(data_b, Some(&'b'));
// O(1) to create the iterators from the index
assert!(eq(list.iter_forward_from(b).unwrap(), &['b', 'c', 'd']));
assert!(eq(list.iter_backward_from(b).unwrap(), &['b', 'a']));
list.insert_prev_to(b, 'X').unwrap(); // O(1)
list.insert_next_to(b, 'Y').unwrap(); // O(1)
assert!(eq(list.iter(), &['a', 'X', 'b', 'Y', 'c', 'd']));
let removed = list.remove(b); // O(1)
assert_eq!(removed, Ok('b'));
assert!(eq(list.iter(), &['a', 'X', 'Y', 'c', 'd']));
// not possible to wrongly use the index
assert_eq!(list.get(b), None);
assert_eq!(
list.get_or_error(b).err(),
Some(NodeIndexError::RemovedNode)
);
// indices can also be stored on insertion
let mut list = List::<Doubly, _>::from_iter(['a', 'b', 'c', 'd']);
let x = list.push_back('x'); // grab index of x in O(1) on insertion
_ = list.push_back('e');
_ = list.push_back('f');
assert!(eq(list.iter(), &['a', 'b', 'c', 'd', 'x', 'e', 'f']));
let data_x = list.get(x); // O(1)
assert_eq!(data_x, Some(&'x'));
list.insert_prev_to(x, 'w').unwrap(); // O(1)
list.insert_next_to(x, 'y').unwrap(); // O(1)
assert!(eq(list.iter(), &['a', 'b', 'c', 'd', 'w', 'x', 'y', 'e', 'f']));
高级用法
NodeIndex在克服链表的主要缺点(它需要O(n)时间才能到达应用O(1)变异的位置)方面非常有用。通过保留所需的NodeIndex,这些变异可以在O(1)时间内完成。但是,为了使用这些常数时间方法,节点索引必须是有效的。
可能导致节点索引无效并使用它时在相关方法中返回NodeIndexError的三个可能原因如下:
- a. 我们在一个不同的
List上使用了NodeIndex。 - b. 当从
List中移除相应元素时,我们使用了NodeIndex。 - c. 为了提高内存利用率,
List在内部执行了内存回收。
请注意,a 和 b 显然是错误,因此收到错误是直接的。实际上,我们可以看到,在 List 上使用 NodeIndex 比在 usize 上使用 Vec 要安全得多,因为我们没有在标准向量中保护这些错误。
然而,c 完全与 List 的底层内存管理相关。有两种可用的策略,它们被设置为 Singly 和 Doubly 的泛型参数。
MemoryReclaimOnThreshold<D>MemoryReclaimNever
默认策略:MemoryReclaimOnThreshold<2>
向 List 添加元素会导致底层存储按预期增长。另一方面,从列表中删除元素会在相应位置留下空隙。换句话说,值被取走,但取走值的内存位置不会立即用于新的元素。
当 MemoryReclaimOnThreshold<D> 策略自动回收这些空隙,当利用率低于阈值时。该阈值是常量泛型参数 D 的函数。具体来说,当封闭节点的数量与所有节点的比例超过 2^D 之一时,将回收关闭节点的内存。
- 当
D = 0时:当利用率低于 0.00% 时(相当于从不)将回收内存。 - 当
D = 1时:当利用率低于 50.00% 时将回收内存。 - 当
D = 2时:当利用率低于 75.00% 时将回收内存。 - 当
D = 3时:当利用率低于 87.50% 时将回收内存。 - ...
底层 PinnedVec 在内存回收操作中不会重新分配。相反,它有效地在已回收的内存内移动元素来填充空隙并修复节点之间的链接。然而,由于元素的位置将会移动,已经获得的 NodeIndex 可能会指向错误的位置。
- 幸运的是,
NodeIndex了解这个操作。因此,不可能错误地使用索引。如果我们获得了一个节点索引,然后列表回收内存,然后我们尝试在这个列表上使用这个节点索引,我们会收到NodeIndexError::ReorganizedCollection。 - 不幸的是,
NodeIndex现在已经没有用了。我们所能做的就是通过例如index_of方法进行线性搜索来重新获得索引。
use orx_linked_list::*;
fn float_eq(x: f32, y: f32) -> bool {
(x - y).abs() < f32::EPSILON
}
// MemoryReclaimOnThreshold<2> -> memory will be reclaimed when utilization is below 75%
let mut list = List::<Doubly, _>::new();
let a = list.push_back('a');
list.push_back('b');
list.push_back('c');
list.push_back('d');
list.push_back('e');
assert!(float_eq(list.node_utilization(), 1.00)); // utilization = 5/5 = 100%
// no reorganization; 'a' is still valid
assert_eq!(list.get_or_error(a), Ok(&'a'));
assert_eq!(list.get(a), Some(&'a'));
_ = list.pop_back(); // leaves a hole
assert!(float_eq(list.node_utilization(), 0.80)); // utilization = 4/5 = 80%
// no reorganization; 'a' is still valid
assert_eq!(list.get_or_error(a), Ok(&'a'));
assert_eq!(list.get(a), Some(&'a'));
_ = list.pop_back(); // leaves the second hole; we have utilization = 3/5 = 60%
// this is below the threshold 75%, and triggers reclaim
// we claim the two unused nodes / holes
assert!(float_eq(list.node_utilization(), 1.00)); // utilization = 3/3 = 100%
// nodes reorganized; 'a' is no more valid
assert_eq!(
list.get_or_error(a),
Err(NodeIndexError::ReorganizedCollection)
);
assert_eq!(list.get(a), None);
// re-obtain the index
let a = list.index_of(&'a').unwrap();
assert_eq!(list.get_or_error(a), Ok(&'a'));
assert_eq!(list.get(a), Some(&'a'));
替代策略:MemoryReclaimNever
然而,通过简单地消除情况c,我们可以确保节点索引始终有效,除非我们手动使其无效。将内存回收策略设置为MemoryReclaimNever可以确保不会有自动或隐式的内存重组。
- 使用
List<Singly<MemoryReclaimNever>, T>代替List<Singly, T>,或者 - 使用
List<Doubly<MemoryReclaimNever>, T>代替List<Doubly, T>。
这种方法的缺点是,如果有大量的弹出或删除操作,内存利用率可能会很低。然而,List通过以下两种方法为调用者提供了管理内存的能力:
List::node_utilization(&self) -> f32方法可以用来查看活动/使用的节点数与使用节点数的比例。调用者可以通过以下方式决定何时采取行动。List::reclaim_closed_nodes(&mut self)方法可以用来手动运行内存回收操作,这将使node_utilization达到100%,同时使已创建的节点索引无效。
use orx_linked_list::*;
fn float_eq(x: f32, y: f32) -> bool {
(x - y).abs() < f32::EPSILON
}
// MemoryReclaimNever -> memory will never be reclaimed automatically
let mut list = List::<Doubly<MemoryReclaimNever>, _>::new();
let a = list.push_back('a');
list.push_back('b');
list.push_back('c');
list.push_back('d');
list.push_back('e');
assert!(float_eq(list.node_utilization(), 1.00)); // utilization = 5/5 = 100%
// no reorganization; 'a' is still valid
assert_eq!(list.get_or_error(a), Ok(&'a'));
assert_eq!(list.get(a), Some(&'a'));
_ = list.pop_back(); // leaves a hole
_ = list.pop_back(); // leaves the second hole
_ = list.pop_back(); // leaves the third hole
assert!(float_eq(list.node_utilization(), 0.40)); // utilization = 2/5 = 40%
// still no reorganization; 'a' is and will always be valid unless we manually reclaim
assert_eq!(list.get_or_error(a), Ok(&'a'));
assert_eq!(list.get(a), Some(&'a'));
list.reclaim_closed_nodes();
// we can manually reclaim memory any time we want to maximize utilization
assert!(float_eq(list.node_utilization(), 1.00)); // utilization = 2/2 = 100%
// we are still protected by list & index validation
// nodes reorganized; 'a' is no more valid, we cannot wrongly use the index
assert_eq!(
list.get_or_error(a),
Err(NodeIndexError::ReorganizedCollection)
);
assert_eq!(list.get(a), None);
// re-obtain the index
let a = list.index_of(&'a').unwrap();
assert_eq!(list.get_or_error(a), Ok(&'a'));
assert_eq!(list.get(a), Some(&'a'));
内部特性
orx_linked_list::List利用了SelfRefCol的安全保证和效率特性。
SelfRefCol将其安全保证建立在所有引用都将是同一集合的元素这一事实上。通过防止引入外部引用或泄漏引用,可以使用**常规的&引用**来安全地构建自引用集合。- 经过仔细封装,
SelfRefCol防止将外部引用传递到列表中,以及将列表节点引用泄漏到外部。一旦建立这一点,它就提供了方便地修改列表节点引用的方法。这些特性使得在这个crate中实现链表非常方便,几乎不需要使用unsafe关键字,没有通过指针的读写,也没有通过索引访问。与std::collections::LinkedList实现相比,可以观察到orx_linked_list::List是一个**更高级的实现**。 - 此外,
orx_linked_list::List比标准链表**快得多**。其中一个主要原因是SelfRefCol将所有元素都保存在彼此附近,而不是在内存中的任意位置,这导致了更好的缓存局部性。
基准测试
变异结束
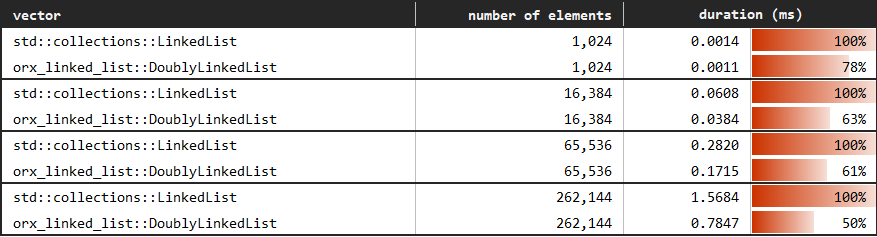
您可以在以下链接中查看基准测试:benches/mutation_ends.rs。
这个基准测试比较了调用 push_front、push_back、pop_front 和 pop_back 方法的性能。

迭代
您可以在以下链接中查看基准测试:benches/iter.rs。
这个基准测试比较了通过 iter 方法迭代的性能。
贡献
欢迎贡献!如果您发现错误、有问题或认为可以改进,请打开一个 issue 或创建一个 PR。
许可证
本库采用 MIT 许可证。有关详细信息,请参阅 LICENSE。
依赖关系
~640KB
~11K SLoC