32 个稳定版本
| 新版本 2.4.0 | 2024 年 8 月 22 日 |
|---|---|
| 2.3.2 | 2024 年 8 月 21 日 |
| 2.2.0 | 2024 年 7 月 25 日 |
| 1.16.0 | 2024 年 7 月 8 日 |
| 1.8.2 | 2024 年 3 月 28 日 |
在 并发 类别中排名第 80
每月下载量 811 次
被 3 个 Crates 使用
105KB
268 行
orx-concurrent-bag
![]()
![]()
一个高效、便捷且轻量级的只增并发数据结构,允许高性能并发收集。
- 便捷:
ConcurrentBag可以简单地作为一个共享引用在多个线程之间安全地共享。它是一个具有特殊并发状态实现的PinnedConcurrentCol。底层的PinnedVec和并发袋可以相互转换。 - 高效:
ConcurrentBag是一个无锁结构,适合并发、无复制和高性能增长。您可以查看 基准测试 和进一步的 性能说明 以获取详细信息。
示例
底层的 PinnedVec 保证使得使用共享引用安全增长变得简单,从而提供了如以下所示的便捷 API。
use orx_concurrent_bag::*;
let bag = ConcurrentBag::new();
let (num_threads, num_items_per_thread) = (4, 1_024);
let bag_ref = &bag;
std::thread::scope(|s| {
for i in 0..num_threads {
s.spawn(move || {
for j in 0..num_items_per_thread {
// concurrently collect results simply by calling `push`
bag_ref.push(i * 1000 + j);
}
});
}
});
let mut vec_from_bag = bag.into_inner().to_vec();
vec_from_bag.sort();
let mut expected: Vec<_> = (0..num_threads).flat_map(|i| (0..num_items_per_thread).map(move |j| i * 1000 + j)).collect();
expected.sort();
assert_eq!(vec_from_bag, expected);
并发状态和属性
并发状态通过一个原子长度简单地建模。这个状态与 PinnedConcurrentCol 的组合导致以下属性
- 向集合中的位置写入不会阻塞其他写入,可以并发发生多个写入。
- 每个位置恰好写入一次。
- ⟹ 不存在写和写的竞争条件。
- 一次只能发生一个增长。增长是无复制的,且不改变已推入元素的内存位置。
- 底层固定向量始终有效,可以通过
into_inner(self)在任何时间取出。 - 只有在将袋转换为底层
PinnedVec之后才能进行读取。 - ⟹ 不存在读和写的竞争条件。
基准测试
使用 push 的性能
您可以在 benches/collect_with_push.rs 中找到基准测试的详细信息。
在实验中,使用了 rayon 的并行迭代器、AppendOnlyVec 和 ConcurrentBag 的 push 方法来从多个线程收集结果。此外,还评估了 ConcurrentBag 的不同底层固定向量。
// reserve and push one position at a time
for j in 0..num_items_per_thread {
bag.push(i * 1000 + j);
}
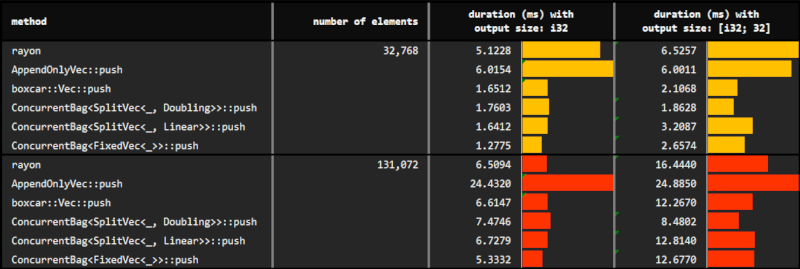
我们观察到 ConcurrentBag 允许高效地进行元素的并发收集
- 并发包的默认增长策略
Doubling,由于其无需任何先验知识而非常灵活,似乎已经超越了其他选择。因此,在大多数情况下都可以使用。 Linear增长策略需要一个参数来确定底层SplitVec的均匀片段容量。当我们希望更保守地进行分配时,可能会选择这种策略。记住,与标准 Vec 类似,Doubling的容量呈指数增长;而正如其名称所暗示的,Linear则线性增长。- 最后,
Fixed增长策略最不灵活,需要完美了解硬约束的容量(如果超过则会引发恐慌)。由于它并不优于Doubling或Linear,因此除了在极少数情况下我们想要预先分配已知所需的确切内存之外,我们并不一定需要使用Fixed。
通过使用 extend 方法而不是 push 方法,可以进一步提高性能。您可以在下一小节中看到结果,并在性能注释中找到详细信息。
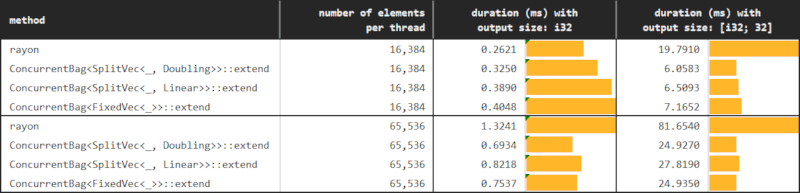
使用 extend 的性能
您可以在benches/collect_with_extend.rs中找到基准测试的详细信息。
在这个后续实验中,唯一的区别是我们使用 extend 而不是 push 与 ConcurrentBag 一起。期望这种方法将解决在 小数据 & 少工作量 情况下由于伪共享导致的性能下降。
在完全均匀的场景中,我们可以如下平均地将工作分配给线程。
// reserve num_items_per_thread positions at a time
// and then push as the iterator yields
let iter = (0..num_items_per_thread).map(|j| i * 100000 + j);
bag.extend(iter);
然而,我们不需要拥有完美的均匀性或对每个线程要推送的项目数量的完美信息,就可以获得 extend 的好处。我们可以简单地按 step_by 分步进行,并以 batch_size 元素为扩展单位。足够大的 batch_size,使得批处理大小元素超过缓存行,就可以防止因伪共享而导致的性能急剧下降。
// reserve batch_size positions at each iteration
// and then push as the iterator yields
for j in (0..num_items_per_thread).step_by(batch_size) {
let iter = (j..(j + batch_size)).map(|j| i * 100000 + j);
bag.extend(iter);
}
虽然通过 ConcurrentBag::push 进行并发收集非常高效,但只要可能,就应该考虑使用 ConcurrentBag::extend 进行收集,因为它会改变规模。如图所示,仅在收集数千个元素时以每批64个元素的批次收集,就能提供数量级的改进。
并发友元集合
ConcurrentBag |
ConcurrentVec |
ConcurrentOrderedBag |
|
|---|---|---|---|
| 写操作 | 通过 push 或 extend 方法保证每个元素正好写入一次 |
通过 push 或 extend 方法保证每个元素正好写入一次 |
有两个不同之处。首先,一个位置可以多次写入。其次,可以使用 set_value 和 set_values 方法在任何时间以任何顺序写入包中的任意元素。这提供了很大的灵活性,同时将安全性责任移交给调用者;因此,设置方法都是 unsafe。 |
| 读取 | 主要是只写集合。通过 unsafe get 和 iter 方法进行已推送元素的并发读取。调用者必须避免竞争条件。 |
读写集合。已经推送的元素可以通过 get 和 iter 方法安全地读取。 |
目前不支持。由于写入操作具有灵活但不可靠的特性,作为调用者难以提供所需的安全保证。 |
| 元素排序 | 由于写入操作是通过通过在固定向量末尾添加元素来实现,使用 push 和 extend,因此,可能存在多个线程执行收集元素到袋中的代码,导致元素收集的顺序不同。 |
由于写入操作是通过通过在固定向量末尾添加元素来实现,使用 push 和 extend,因此,可能存在多个线程执行收集元素到袋中的代码,导致元素收集的顺序不同。 |
这是本收集的主要目标,允许并发且按正确顺序收集元素。尽管这看似不简单;当与 ConcurrentOrderedBag 一起使用 ConcurrentIter 时,几乎可以轻易实现。 |
into_inner |
一旦并发收集完成,袋可以安全且低成本地转换为其底层的 PinnedVec<T>。 |
一旦并发收集完成,vec 可以安全地转换为其底层的 PinnedVec<ConcurrentOption<T>>。注意,元素被包裹在一个 ConcurrentOption 中,以便提供线程安全的并发读写操作。 |
通过灵活的设置器进行增长,允许写入任何位置,ConcurrentOrderedBag 有可能包含间隙。 into_inner 调用提供了一些有用的度量,例如,推送元素的数目是否与向量的最大索引相匹配;然而,它不能保证袋子是无间隙的。调用者需要负责通过一个 unsafe 调用来解包以获取底层的 PinnedVec<T>。 |
性能注意事项
我们旋转多少次和多久?
push 和 extend 方法的唯一等待或旋转条件:当底层的 PinnedVec 需要增长时。请注意,固定向量的增长是无复制的。因此,当它旋转时,它等待的只是分配。由于增长次数是确定的,所以旋转次数也是确定的。
例如,假设我们将总共 15_000 个元素并发地推送到一个空的袋子中。
- 进一步假设我们使用默认的
SplitVec<_, Doubling>作为底层固定向量。在整个执行过程中,我们将分配容量为 [4, 8, 16, ..., 4096, 8192] 的片段,总容量将达到 16_380。换句话说,在整个执行过程中我们将恰好分配 12 次。 - 如果我们使用具有恒定片段长度 1_024 的
SplitVec<_, Linear>,我们将分配 15 个等容量的片段。 - 如果我们使用严格的
FixedVec<_>,我们必须预分配一个安全数量,并且永远不会超过这个数字。因此,将永远不会有任何旋转。
False Sharing
我们需要注意潜在的假共享风险,这可能导致在逐个将元素添加到ConcurrentBag::push时性能显著下降。
由于假共享导致的性能下降可能在以下两个条件同时满足时观察到
- 小数据:要添加的数据很小,一个缓存行中能容纳的元素越多,风险越大;
- 工作量小:多个线程/核心以高频率向并发袋中添加元素;即,在
push调用之间需要非常少或可以忽略的工作/时间。
上面的例子符合这种情况。每个线程在推送元素之间只执行一次乘法和加法运算,要推送的元素很小。
ConcurrentBag为要推送的每个值分配唯一的位位置。在位置级别上线程之间没有真正的共享。- 然而,缓存行包含多个位置。一个线程更新特定位置会使得另一个线程上的整个缓存行失效。
- 线程最终频繁地重新加载缓存行,而不是执行将元素写入袋的实际工作。这可能导致性能显著下降。
extend以避免假共享
假设我们有n个线程正在填充一个ConcurrentBag。在任何给定时刻,线程A通过传递一个生成64个元素的迭代器调用extend。并发袋将为这次扩展调用保留64个连续的位置。来自其他线程的并发推送或扩展调用将无法访问这些位置。假设64个元素的大小足够大
- 线程A写入这些64个位置不会使其他线程的缓存行失效。同样,其他线程写入他们保留的位置也不会使线程A的缓存行失效。
- 此外,这还将减少与逐个推送元素相比的原子更新次数。
从push到extend的代码更改不大。上面的例子可以修改如下以避免假共享的性能下降。
use orx_concurrent_bag::*;
let (num_threads, num_items_per_thread) = (4, 1_024);
let bag = ConcurrentBag::new();
let batch_size = 64;
let bag_ref = &bag;
std::thread::scope(|s| {
for i in 0..num_threads {
s.spawn(move || {
for j in (0..num_items_per_thread).step_by(batch_size) {
let iter = (j..(j + batch_size)).map(|j| i * 1000 + j);
bag_ref.extend(iter);
}
});
}
});
贡献
欢迎贡献!如果你注意到错误,有疑问或认为可以改进的地方,请打开问题或创建PR。
许可证
本库采用MIT许可证。有关详细信息,请参阅LICENSE。
依赖关系
~460KB