15 个稳定版本
| 1.6.2 | 2023 年 12 月 12 日 |
|---|---|
| 1.6.1 | 2023 年 11 月 23 日 |
| 1.5.0 | 2023 年 6 月 13 日 |
| 1.4.0 | 2022 年 4 月 8 日 |
| 0.0.0 |
|
在 国际化(i18n) 中排名 #8
每月下载量 6,708
被 12 个 Crates (直接 10 个)使用
22MB
8K SLoC
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
1. 这个库的功能是什么?
它的任务很简单:它告诉你某个文本是用哪种语言编写的。这对于自然语言处理应用中的语言数据预处理非常有用,例如文本分类和拼写检查。其他用例,例如,可能包括根据电子邮件的语言将电子邮件路由到正确的地理位置的客户服务部门。
2. 为什么存在这个库?
语言检测通常作为大型机器学习框架或自然语言处理应用的一部分来完成。在不需要这些系统的完整功能或不想学习这些系统的情况下,一个小巧灵活的库会很有帮助。
到目前为止,Rust 生态系统中用于此任务的综合性开源库还包括 CLD2、Whatlang 和 Whichlang。不幸的是,它们大多数有两个主要缺点
- 检测仅适用于相当长的文本片段。对于非常短的文本片段,如推特消息,它们不能提供足够的结果。
- 参与决策过程的语言越多,检测结果越不准确。
Lingua 旨在消除这些问题。它几乎不需要任何配置,在长文本和短文本上都能提供相当准确的结果,甚至在单个单词和短语上也是如此。它结合了基于规则和统计的方法,但不使用任何单词字典。它也不需要连接到任何外部 API 或服务。一旦下载了库,就可以完全离线使用。
3. 支持哪些语言?
与其他语言检测库相比,Lingua 的重点是 质量而非数量,即在添加新语言之前,首先确保对一小组语言进行准确的检测。目前,以下 75 种语言得到支持
- A
- 南非荷兰语
- 阿尔巴尼亚语
- 阿拉伯语
- 亚美尼亚语
- 阿塞拜疆语
- B
- 巴斯克语
- 白俄罗斯语
- 孟加拉语
- 挪威博克马尔语
- 波斯尼亚语
- 保加利亚语
- C
- 加泰罗尼亚语
- 中文
- 克罗地亚语
- 捷克语
- D
- 丹麦语
- 荷兰语
- E
- 英语
- 世界语
- 爱沙尼亚语
- F
- 芬兰语
- 法语
- G
- 刚达语
- 格鲁吉亚语
- 德语
- 希腊语
- 古吉拉特语
- H
- 希伯来语
- 印地语
- 匈牙利语
- I
- 冰岛语
- 印度尼西亚语
- 爱尔兰语
- 意大利语
- J
- 日语
- K
- 哈萨克语
- 韩语
- L
- 拉丁语
- 拉脱维亚语
- 立陶宛语
- M
- 马其顿语
- 马来语
- 毛利语
- 马拉地语
- 蒙古语
- N
- 挪威尼诺斯克语
- P
- 波斯语
- 波兰语
- 葡萄牙语
- 旁遮普语
- R
- 罗马尼亚语
- 俄语
- S
- 塞尔维亚语
- 绍纳语
- 斯洛伐克语
- 斯洛文尼亚语
- 索马里语
- 茨瓦纳语
- 西班牙语
- 斯瓦希里语
- 瑞典语
- T
- 他加禄语
- 泰米尔语
- 泰卢固语
- 泰语
- 聪加语
- 茨瓦纳语
- 土耳其语
- U
- 乌克兰语
- 乌尔都语
- V
- 越南语
- W
- 威尔士语
- X
- 科萨语
- Y
- 约鲁巴语
- Z
- 祖鲁语
4. 准确度如何?
Lingua 可以报告每个支持的语言所提供的捆绑测试数据的准确度统计信息。每个语言的测试数据分为三个部分
- 一个包含至少5个字符的单词列表
- 一个包含至少10个字符的词对列表
- 一个包含各种长度的完整语法句子的列表
语言模型和测试数据都是从德国莱比锡大学提供的Wortschatz语料库的独立文档中创建的。用于训练的数据是从各种新闻网站上爬取的,每个语料库包含一百万个句子。用于测试的语料库是由任意选择的网站组成的,每个语料库包含一万个句子。从每个测试语料库中分别提取了1000个单字、1000个词对和1000个句子。
基于生成的测试数据,我比较了在 Lingua 支持的75种语言数据上运行 Lingua、CLD2、Whatlang 和 Whichlang 的检测结果。在检测过程中,其他库不支持的语言被简单地忽略。
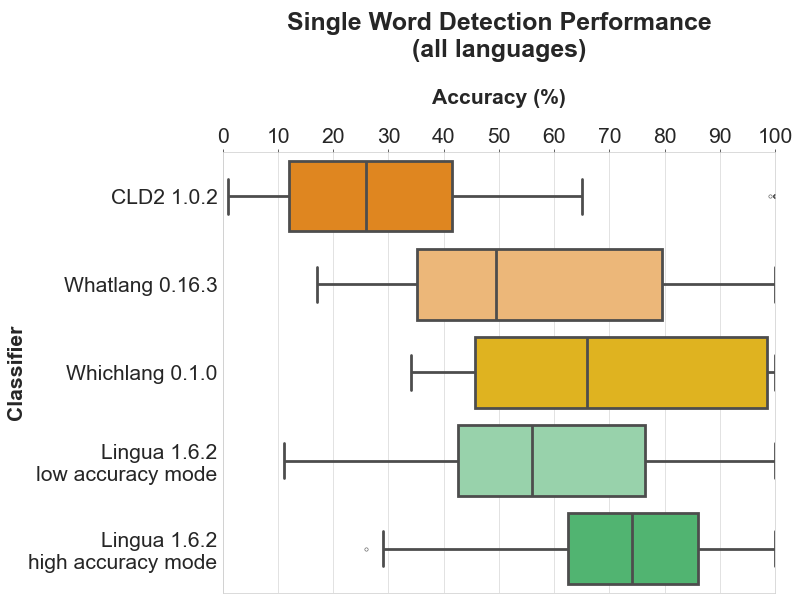
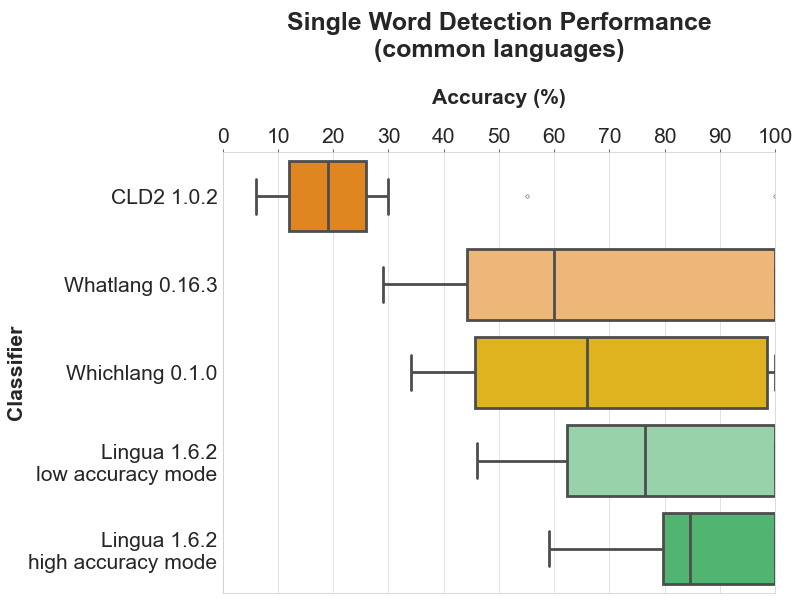
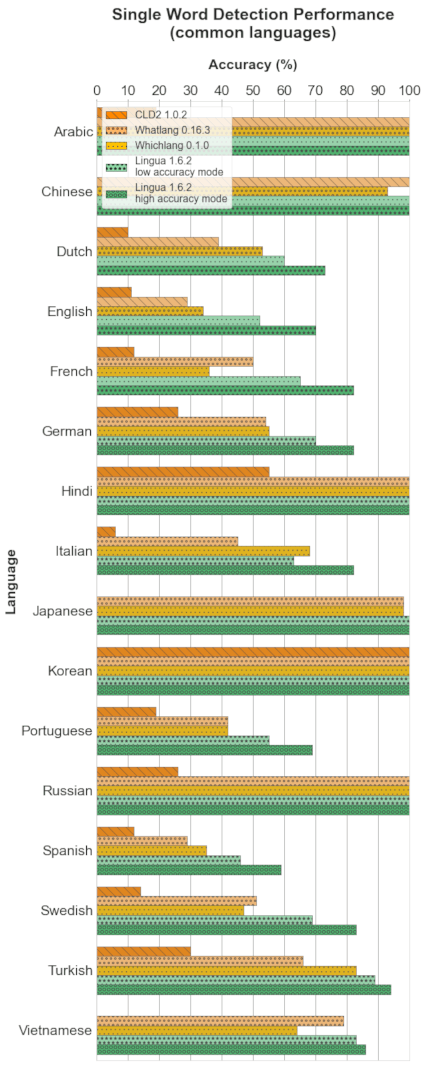
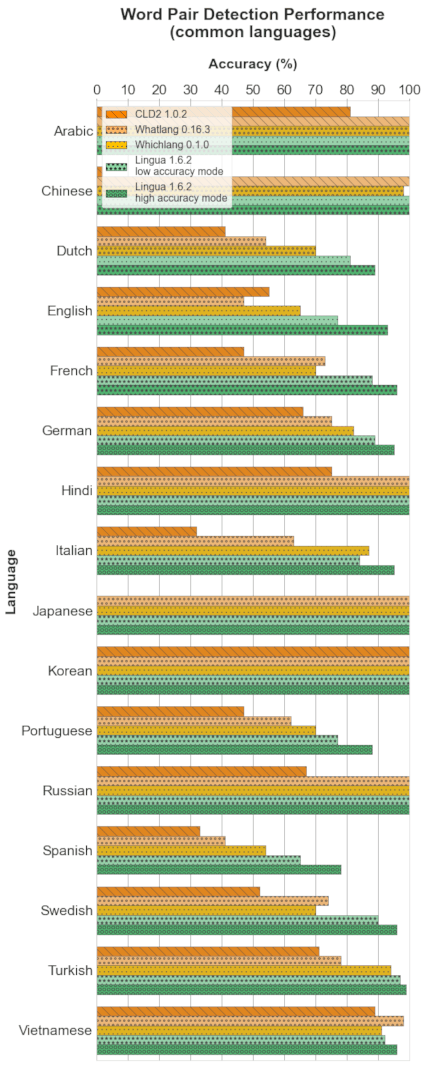
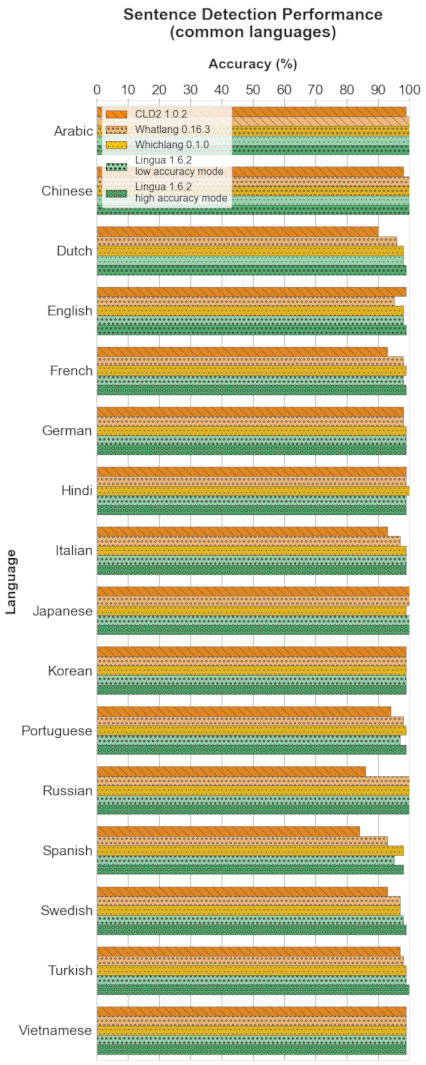
以下每个部分包含四个图表。条形图显示了每个支持语言的具体准确度结果。箱形图说明了每个分类器的准确度值的分布。箱子本身代表中间50%的数据所在区域。在彩色箱子内,水平线标记了分布的中位数。
每个部分的头两个图表分别显示了每个分类器中所有支持语言的检测结果。最后两个图表仅限于所有比较分类器都支持的目前16种语言的公共子集。这种区分是有意义的,因为第一个箱形图给人留下了 Whichlang 是最准确的分类器的印象,但实际上并非如此。Whichlang 只支持16种语言,而 Lingua 支持75种语言。对于第二个箱形图,Whatlang 和 Lingua 支持的语言已被限制为 Whichlang 支持的16种语言。这提供了更准确的比较,并表明总体而言,Lingua 是这次比较中最准确的语言检测库。
4.1 单词检测
4.1.1 所有语言
条形图

4.1.2 公共语言
条形图
4.2 词对检测
4.2.1 所有语言
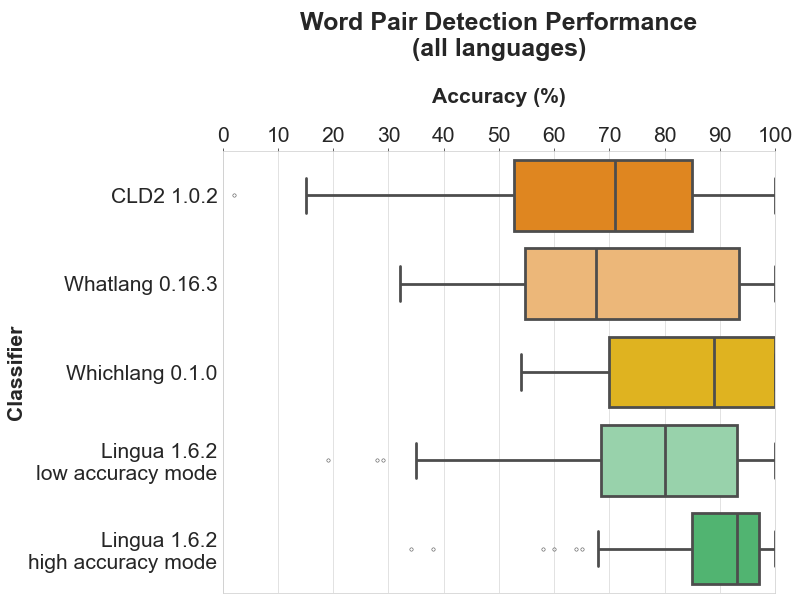
条形图

4.2.2 常见语言
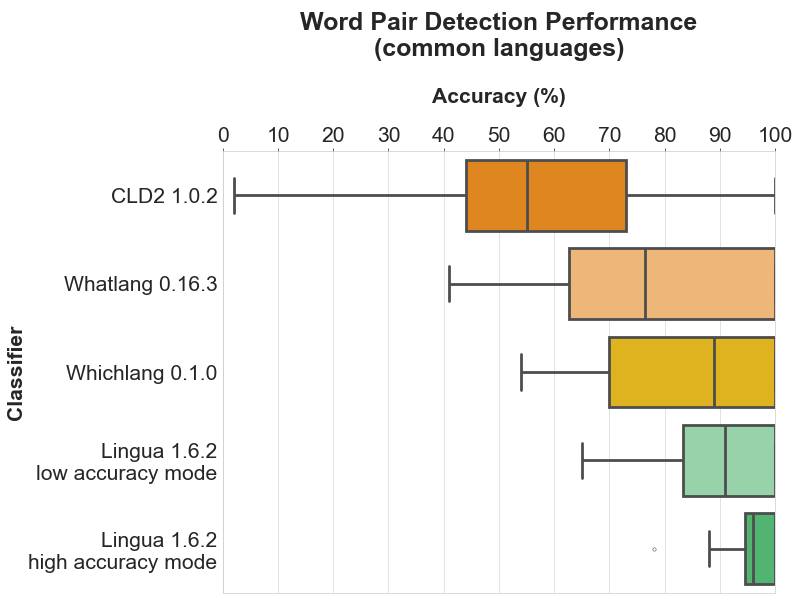
条形图
4.3 句子检测
4.3.1 所有语言

条形图

4.3.2 常见语言

条形图
4.4 平均检测
4.4.1 所有语言
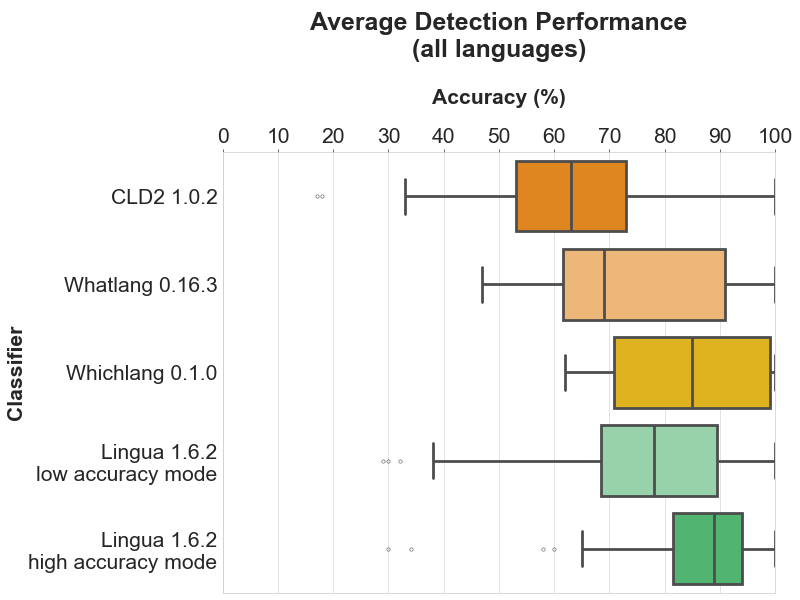
条形图

4.4.2 常见语言
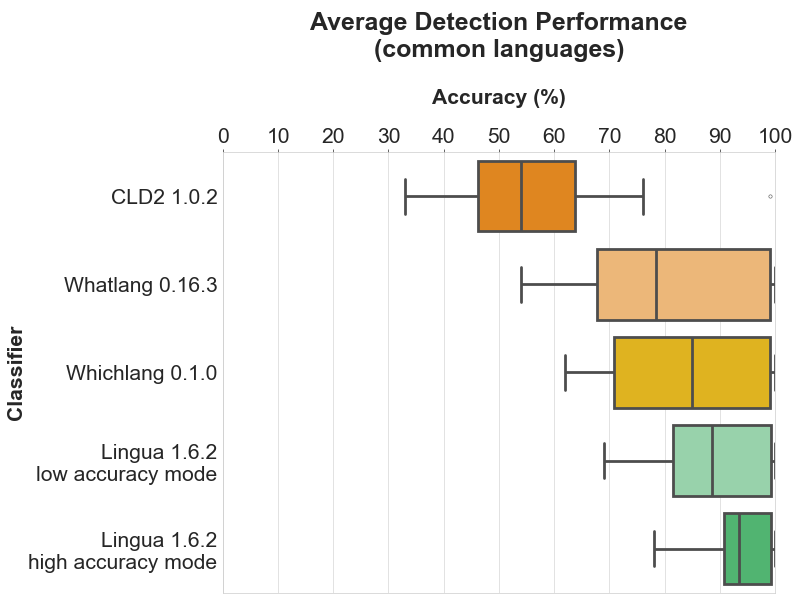
条形图
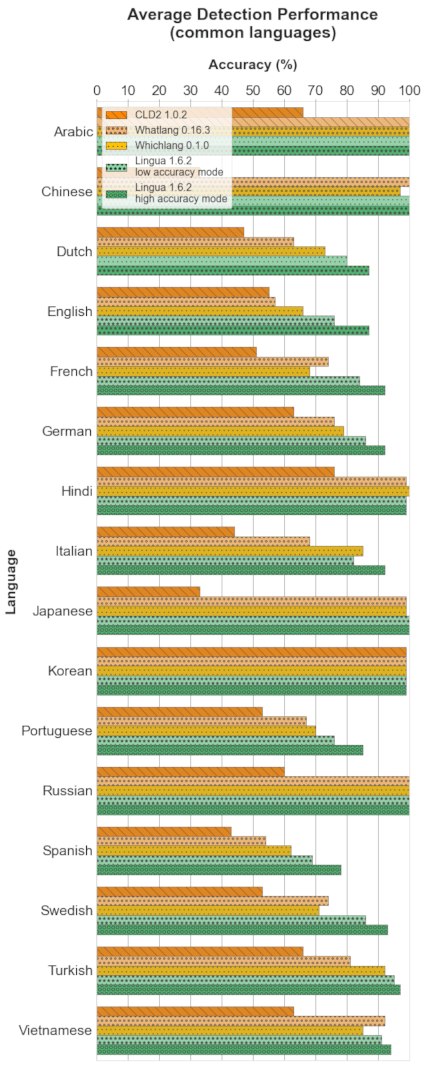
4.5 平均值、中位数和标准差
下表显示了每种语言和分类器的详细统计数据,包括平均值、中位数和标准差。
4.5.1 所有语言
打开表格
| 语言 | 平均 | 单词 | 词对 | 句子 | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lingua (高精度模式) |
Lingua (低精度模式) |
Whichlang | Whatlang | CLD2 | Lingua (高精度模式) |
Lingua (低精度模式) |
Whichlang | Whatlang | CLD2 | Lingua (高精度模式) |
Lingua (低精度模式) |
Whichlang | Whatlang | CLD2 | Lingua (高精度模式) |
Lingua (低精度模式) |
Whichlang | Whatlang | CLD2 | |
| 南非荷兰语 | ||||||||||||||||||||
| 阿尔巴尼亚语 | ||||||||||||||||||||
| 阿拉伯语 | ||||||||||||||||||||
| 亚美尼亚语 | ||||||||||||||||||||
| 阿塞拜疆语 | ||||||||||||||||||||
| 巴斯克语 | ||||||||||||||||||||
| 白俄罗斯语 | ||||||||||||||||||||
| 孟加拉语 | ||||||||||||||||||||
| Bokmal | ||||||||||||||||||||
| 波斯尼亚语 | ||||||||||||||||||||
| 保加利亚语 | ||||||||||||||||||||
| 加泰罗尼亚语 | ||||||||||||||||||||
| 中文 | ||||||||||||||||||||
| 克罗地亚语 | ||||||||||||||||||||
| 捷克语 | ||||||||||||||||||||
| 丹麦语 | ||||||||||||||||||||
| 荷兰语 | ||||||||||||||||||||
| 英语 | ||||||||||||||||||||
| 世界语 | ||||||||||||||||||||
| 爱沙尼亚语 | ||||||||||||||||||||
| 芬兰语 | ||||||||||||||||||||
| 法语 | ||||||||||||||||||||
| 刚达语 | ||||||||||||||||||||
| 格鲁吉亚语 | ||||||||||||||||||||
| 德语 | ||||||||||||||||||||
| 希腊语 | ||||||||||||||||||||
| 古吉拉特语 | ||||||||||||||||||||
| 希伯来语 | ||||||||||||||||||||
| 印地语 | ||||||||||||||||||||
| 匈牙利语 | ||||||||||||||||||||
| 冰岛语 | ||||||||||||||||||||
| 印度尼西亚语 | ||||||||||||||||||||
| 爱尔兰语 | ||||||||||||||||||||
| 意大利语 | ||||||||||||||||||||
| 日语 | ||||||||||||||||||||
| 哈萨克语 | ||||||||||||||||||||
| 韩语 | ||||||||||||||||||||
| 拉丁语 | ||||||||||||||||||||
| 拉脱维亚语 | ||||||||||||||||||||
| 立陶宛语 | ||||||||||||||||||||
| 马其顿语 | ||||||||||||||||||||
| 马来语 | ||||||||||||||||||||
| 毛利语 | ||||||||||||||||||||
| 马拉地语 | ||||||||||||||||||||
| 蒙古语 | ||||||||||||||||||||
| Nynorsk | ||||||||||||||||||||
| 波斯语 | ||||||||||||||||||||
| 波兰语 | ||||||||||||||||||||
| 葡萄牙语 | ||||||||||||||||||||
| 旁遮普语 | ||||||||||||||||||||
| 罗马尼亚语 | ||||||||||||||||||||
| 俄语 | ||||||||||||||||||||
| 塞尔维亚语 | ||||||||||||||||||||
| 绍纳语 | ||||||||||||||||||||
| 斯洛伐克语 | ||||||||||||||||||||
| 斯洛文尼亚语 | ||||||||||||||||||||
| 索马里语 | ||||||||||||||||||||
| 茨瓦纳语 | ||||||||||||||||||||
| 西班牙语 | ||||||||||||||||||||
| 斯瓦希里语 | ||||||||||||||||||||
| 瑞典语 | ||||||||||||||||||||
| 他加禄语 | ||||||||||||||||||||
| 泰米尔语 | ||||||||||||||||||||
| 泰卢固语 | ||||||||||||||||||||
| 泰语 | ||||||||||||||||||||
| 聪加语 | ||||||||||||||||||||
| 茨瓦纳语 | ||||||||||||||||||||
| 土耳其语 | ||||||||||||||||||||
| 乌克兰语 | ||||||||||||||||||||
| 乌尔都语 | ||||||||||||||||||||
| 越南语 | ||||||||||||||||||||
| 威尔士语 | ||||||||||||||||||||
| 科萨语 | ||||||||||||||||||||
| 约鲁巴语 | ||||||||||||||||||||
| 祖鲁语 | ||||||||||||||||||||
| 平均值 | ||||||||||||||||||||
| 中位数 | 89.0 | 78.0 | 85.0 | 69.0 | 63.0 | 74.0 | 56.0 | 66.0 | 49.5 | 26.0 | 93.0 | 80.0 | 89.0 | 67.5 | 71.0 | 99.0 | 96.0 | 99.0 | 97.0 | 98.0 |
| 标准差 | 13.17 | 17.39 | 14.21 | 17.27 | 18.54 | 18.54 | 25.09 | 26.6 | 27.23 | 28.81 | 13.25 | 19.12 | 15.66 | 21.07 | 22.74 | 11.06 | 11.84 | 0.85 | 6.04 | 12.16 |
4.5.2 常见语言
打开表格
| 语言 | 平均 | 单词 | 词对 | 句子 | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lingua (高精度模式) |
Lingua (低精度模式) |
Whichlang | Whatlang | CLD2 | Lingua (高精度模式) |
Lingua (低精度模式) |
Whichlang | Whatlang | CLD2 | Lingua (高精度模式) |
Lingua (低精度模式) |
Whichlang | Whatlang | CLD2 | Lingua (高精度模式) |
Lingua (低精度模式) |
Whichlang | Whatlang | CLD2 | |
| 阿拉伯语 | ||||||||||||||||||||
| 中文 | ||||||||||||||||||||
| 荷兰语 | ||||||||||||||||||||
| 英语 | ||||||||||||||||||||
| 法语 | ||||||||||||||||||||
| 德语 | ||||||||||||||||||||
| 印地语 | ||||||||||||||||||||
| 意大利语 | ||||||||||||||||||||
| 日语 | ||||||||||||||||||||
| 韩语 | ||||||||||||||||||||
| 葡萄牙语 | ||||||||||||||||||||
| 俄语 | ||||||||||||||||||||
| 西班牙语 | ||||||||||||||||||||
| 瑞典语 | ||||||||||||||||||||
| 土耳其语 | ||||||||||||||||||||
| 越南语 | ||||||||||||||||||||
| 平均值 | ||||||||||||||||||||
| 中位数 | 93.5 | 88.5 | 85.0 | 78.5 | 54.0 | 84.5 | 76.5 | 66.0 | 60.0 | 19.0 | 96.0 | 91.0 | 89.0 | 76.5 | 55.0 | 99.0 | 99.0 | 99.0 | 98.0 | 97.5 |
| 标准差 | 6.56 | 10.44 | 14.21 | 16.91 | 16.44 | 13.51 | 20.23 | 26.6 | 28.33 | 25.57 | 6.03 | 10.76 | 15.66 | 21.17 | 25.16 | 0.58 | 1.31 | 0.85 | 1.98 | 4.95 |
5. 它有多快?
可以通过以下方式运行所有分类器的各种基准测试
cargo bench --features benchmark
基准测试测量了将2,000个句子分类为16种常见语言所需的时间,这些语言是每个语言检测器所支持的。以下结果是在iMac 3.6 GHz 8核心Intel Core i9,40 GB RAM上生成的。Whichlang的处理时间最短,Lingua最长。
| 检测器 | 单线程 | 多线程 |
|---|---|---|
| Whichlang | 2.046 ms | 351.03 µs |
| CLD 2 | 8.923 ms | 2.05 ms |
| Whatlang (常见语言) | 47.74 ms | 5.61 ms |
| Whatlang (所有语言) | 113.08 ms | 12.99 ms |
| Lingua (低精度模式,常见语言) | 180.54 ms | 24.55 ms |
| Lingua (高精度模式,常见语言) | 333.31 ms | 37.35 ms |
| Lingua (低精度模式,所有语言) | 373.15 ms | 48.18 ms |
| Lingua (高精度模式,所有语言) | 622.00 ms | 96.65 ms |
准确度报告脚本测量了每个语言检测器为支持的所有75种语言中的每一种对3000个输入文本进行分类所需的时间。
| 检测器 | 时间 |
|---|---|
| Whichlang | 0.13秒 |
| CLD 2 | 1.67秒 |
| Lingua (低精度模式,多线程) | 3.11秒 |
| Whatlang | 9.82秒 |
| Lingua (高精度模式,多线程) | 10.36秒 |
| Lingua (低精度模式,单线程) | 21.06秒 |
| Lingua (高精度模式,单线程) | 57.15秒 |
6. 为什么它比其他库更好?
每个语言检测器都使用在某个训练语料库中的字符分布上训练的概率n-gram模型。大多数库仅使用大小为3(三元组)的n-gram,这对于检测由多个句子组成的长文本片段的语言是令人满意的。然而,对于短短语或单个单词,三元组是不够的。输入文本越短,可用的n-gram越少。从如此少的n-gram估计出的概率是不可靠的。这就是为什么Lingua使用1到5大小的n-gram,从而实现了对正确语言的更准确的预测。
第二个重要的区别是,Lingua不仅使用这种统计模型,还使用基于规则的引擎。该引擎首先确定输入文本的字母表,并搜索在一种或多种语言中独一无二的字符。如果可以通过这种方式可靠地选择一种语言,那么统计模型就不再必要了。在任何情况下,基于规则的引擎都会过滤掉不满足输入文本条件的语言。然后,在第二步中,才考虑概率n-gram模型。这样做是有意义的,因为加载更少的语言模型意味着更少的内存消耗和更好的运行时性能。
通常,使用相应的api方法限制在分类过程中要考虑的语言集总是一个好主意。如果您事先知道某些语言永远不会出现在输入文本中,请不要让它们参与分类过程。基于规则的引擎的过滤机制相当好,但是基于您对输入文本的了解进行过滤总是更可取的。
7. 如何重现准确度结果?
如果您想重现上述的准确性结果,您可以通过以下步骤为自己生成所有分类器和所有语言的测试报告:
cargo run --release --bin accuracy_reports --features accuracy-reports
在这里使用 --release 标志非常重要,因为在调试模式下加载语言模型需要太多时间。对于每个检测器和语言,一个测试报告文件将被写入到 /accuracy-reports,位于 src 目录旁边。例如,这里是当前 Lingua 德语报告的输出
##### German #####
>>> Accuracy on average: 89.23%
>> Detection of 1000 single words (average length: 9 chars)
Accuracy: 73.9%
Erroneously classified as Dutch: 2.3%, Danish: 2.1%, English: 2%, Latin: 1.9%, Bokmal: 1.6%, Basque: 1.2%, Esperanto: 1.2%, French: 1.2%, Italian: 1.2%, Swedish: 1%, Afrikaans: 0.8%, Tsonga: 0.7%, Nynorsk: 0.6%, Spanish: 0.6%, Yoruba: 0.6%, Finnish: 0.5%, Sotho: 0.5%, Welsh: 0.5%, Estonian: 0.4%, Irish: 0.4%, Polish: 0.4%, Swahili: 0.4%, Tagalog: 0.4%, Tswana: 0.4%, Bosnian: 0.3%, Icelandic: 0.3%, Romanian: 0.3%, Albanian: 0.2%, Catalan: 0.2%, Croatian: 0.2%, Indonesian: 0.2%, Lithuanian: 0.2%, Maori: 0.2%, Turkish: 0.2%, Xhosa: 0.2%, Zulu: 0.2%, Latvian: 0.1%, Malay: 0.1%, Slovak: 0.1%, Slovene: 0.1%, Somali: 0.1%
>> Detection of 1000 word pairs (average length: 18 chars)
Accuracy: 94.1%
Erroneously classified as Dutch: 0.9%, Latin: 0.8%, English: 0.7%, Swedish: 0.6%, Danish: 0.5%, French: 0.4%, Bokmal: 0.3%, Irish: 0.2%, Tagalog: 0.2%, Afrikaans: 0.1%, Esperanto: 0.1%, Estonian: 0.1%, Finnish: 0.1%, Italian: 0.1%, Maori: 0.1%, Nynorsk: 0.1%, Somali: 0.1%, Swahili: 0.1%, Tsonga: 0.1%, Turkish: 0.1%, Welsh: 0.1%, Zulu: 0.1%
>> Detection of 1000 sentences (average length: 111 chars)
Accuracy: 99.7%
Erroneously classified as Dutch: 0.2%, Latin: 0.1%
8. 如何将其添加到您的项目中?
将 Lingua 添加到您的 Cargo.toml 文件中,如下所示
[dependencies]
lingua = "1.6.2"
默认情况下,这将下载所有 75 种受支持语言的模型依赖项,总大小约为 90 MB。如果您的带宽或硬盘空间有限,或者您根本不需要所有语言,您可以在您的 Cargo.toml 中指定要下载的语言模型的子集,作为单独的功能
[dependencies]
lingua = { version = "1.6.2", default-features = false, features = ["french", "italian", "spanish"] }
9. 如何构建?
为了自己构建源代码,您需要在您的计算机上安装 稳定的 Rust 工具链,以便可以使用 cargo,Rust 的包管理器。
git clone https://github.com/pemistahl/lingua-rs.git
cd lingua-rs
cargo build
源代码附带了一个广泛的单元测试套件。要运行它们,只需说
cargo test
借助 PyO3 和 Maturin,库已被编译成一个 Python 扩展模块,以便它可以在任何 Python 软件中使用。它在 Python 包索引 中可用,并且可以使用以下命令安装
pip install lingua-language-detector
要自己构建 Python 扩展模块,创建一个虚拟环境并安装 Maturin。
python -m venv .venv
source .venv/bin/activate
pip install maturin
maturin build
10. 如何使用?
10.1 基本用法
use lingua::{Language, LanguageDetector, LanguageDetectorBuilder};
use lingua::Language::{English, French, German, Spanish};
let languages = vec![English, French, German, Spanish];
let detector: LanguageDetector = LanguageDetectorBuilder::from_languages(&languages).build();
let detected_language: Option<Language> = detector.detect_language_of("languages are awesome");
assert_eq!(detected_language, Some(English));
10.2 最小相对距离
默认情况下,Lingua 返回给定输入文本的最可能语言。然而,有些词在多种语言中拼写相同。例如,单词 prologue 既是有效的英语单词也是法语单词。在这种情况下,Lingua 可能会输出英语或法语,这在特定上下文中可能是错误的。对于这种情况,可以指定每个可能语言对数化和加权和必须满足的最小相对距离。它可以以下述方式表示
use lingua::LanguageDetectorBuilder;
use lingua::Language::{English, French, German, Spanish};
let detector = LanguageDetectorBuilder::from_languages(&[English, French, German, Spanish])
.with_minimum_relative_distance(0.9)
.build();
let detected_language = detector.detect_language_of("languages are awesome");
assert_eq!(detected_language, None);
请注意,语言概率之间的距离取决于输入文本的长度。输入文本越长,语言之间的距离就越大。因此,如果您想对非常短的文字短语进行分类,不要设置过高的最小相对距离。否则,像上面的例子一样,大多数时候将返回 None。这是语言检测不可靠的情况下的返回值。
10.3 置信值
了解最可能的语言很好,但计算出的可能性有多可靠?与其他被检查的语言相比,最可能的语言有多不可能?这些问题也可以得到解答
use lingua::Language::{English, French, German, Spanish};
use lingua::LanguageDetectorBuilder;
fn main() {
let languages = vec![English, French, German, Spanish];
let detector = LanguageDetectorBuilder::from_languages(&languages).build();
let confidence_values = detector
.compute_language_confidence_values("languages are awesome")
.into_iter()
.map(|(language, confidence)| (language, (confidence * 100.0).round() / 100.0))
.collect::<Vec<_>>();
assert_eq!(
confidence_values,
vec![
(English, 0.93),
(French, 0.04),
(German, 0.02),
(Spanish, 0.01)
]
);
}
在上面的例子中,返回了一个包含所有可能语言的二元组向量的数组,这些语言按其置信值降序排列。每个值都在 0.0 和 1.0 之间。所有语言的概率之和为 1.0。如果语言被规则引擎明确识别,则此语言的值始终为 1.0。其他语言将收到 0.0 的值。
还有一个方法可以返回特定语言的确信值
use lingua::Language::{English, French, German, Spanish};
use lingua::LanguageDetectorBuilder;
fn main() {
let languages = vec![English, French, German, Spanish];
let detector = LanguageDetectorBuilder::from_languages(&languages).build();
let confidence = detector.compute_language_confidence("languages are awesome", French);
let rounded_confidence = (confidence * 100.0).round() / 100.0;
assert_eq!(rounded_confidence, 0.04);
}
此方法计算出的值介于0.0和1.0之间。如果语言被规则引擎明确识别,则总是返回值1.0。如果给定的语言不支持此检测器实例,则总是返回值0.0。
10.4 预加载与延迟加载
默认情况下,Lingua 使用延迟加载,只在需要时加载被认为与基于规则的过滤器引擎相关的语言模型。例如,对于网络服务,预先将所有语言模型加载到内存中,以避免在等待服务响应时出现意外的延迟。如果您想启用预加载模式,可以这样做
LanguageDetectorBuilder::from_all_languages().with_preloaded_language_models().build();
LanguageDetector 的多个实例在内存中共享相同的语言模型,这些模型由实例异步访问。
10.5 低精度模式与高精度模式
Lingua 的高检测精度是以速度明显慢于其他语言检测器为代价的。大型语言模型也消耗了大量的内存。这些要求可能不适合资源不足的系统。如果您主要需要分类长文本或需要节省资源,可以启用一个仅将小部分语言模型加载到内存中的 低精度模式
LanguageDetectorBuilder::from_all_languages().with_low_accuracy_mode().build();
这种方法的缺点是,由少于120个字符的短文本的检测精度将显著降低。然而,对于超过120个字符的文本,检测精度基本上不受影响。
在高精度模式(默认模式)下,如果加载所有语言模型,语言检测器将消耗大约970 MB的内存。在低精度模式下,内存消耗减少到大约72 MB。目标是后续版本中进一步降低内存消耗。
为了更小的内存占用和更快的性能,可以在构建语言检测器时减少语言集。在大多数情况下,不建议从所有支持的语言构建检测器。当您了解要分类的文本时,您几乎总是可以排除某些语言为不可能或不太可能发生。
10.6 混合语言文本中的多语言检测
与大多数其他语言检测器不同,Lingua 能够在混合语言文本中检测多种语言。这个特性可以得到相当合理的结果,但它仍然处于实验状态,因此检测结果高度依赖于输入文本。它在高精度模式下效果最佳,每个语言都有多个长单词。短语和它们的单词越短,结果越不准确。在构建语言检测器时减少语言集也可以提高这项任务的准确性,如果文本中出现的语言与相应语言检测器实例支持的语言相同。
use lingua::DetectionResult;
use lingua::Language::{English, French, German};
use lingua::LanguageDetectorBuilder;
fn main() {
let languages = vec![English, French, German];
let detector = LanguageDetectorBuilder::from_languages(&languages).build();
let sentence = "Parlez-vous français? \
Ich spreche Französisch nur ein bisschen. \
A little bit is better than nothing.";
let results: Vec<DetectionResult> = detector.detect_multiple_languages_of(sentence);
if let [first, second, third] = &results[..] {
assert_eq!(first.language(), French);
assert_eq!(
&sentence[first.start_index()..first.end_index()],
"Parlez-vous français? "
);
assert_eq!(second.language(), German);
assert_eq!(
&sentence[second.start_index()..second.end_index()],
"Ich spreche Französisch nur ein bisschen. "
);
assert_eq!(third.language(), English);
assert_eq!(
&sentence[third.start_index()..third.end_index()],
"A little bit is better than nothing."
);
}
}
在上面的例子中,返回了一个 DetectionResult 向量。向量中的每个条目描述了一个连续的单语言文本部分,提供了相应子字符串的起始和结束索引。
10.7 单线程与多线程语言检测
上面解释的 LanguageDetector 方法都是在单线程中运行的。如果您想对非常大的文本集进行分类,您可能希望使用多个线程有效地利用所有可用的CPU核心以获得最佳性能。
每个单线程方法都有一个多线程等价方法,它接受一个文本列表并返回一个结果列表。
| 单线程 | 多线程 |
|---|---|
detect_language_of |
detect_languages_in_parallel_of |
detect_multiple_languages_of |
detect_multiple_languages_in_parallel_of |
compute_language_confidence_values |
compute_language_confidence_values_in_parallel |
compute_language_confidence |
compute_language_confidence_in_parallel |
10.8 构建LanguageDetector的方法
可能存在分类任务,你事先就知道你的语言数据肯定不是拉丁语写的,例如(真是个惊喜 :-)。在这种情况下,如果排除某些语言或不显式包含相关语言,检测的准确性可能会更高。
use lingua::{LanguageDetectorBuilder, Language, IsoCode639_1, IsoCode639_3};
// Include all languages available in the library.
LanguageDetectorBuilder::from_all_languages();
// Include only languages that are not yet extinct (= currently excludes Latin).
LanguageDetectorBuilder::from_all_spoken_languages();
// Include only languages written with Cyrillic script.
LanguageDetectorBuilder::from_all_languages_with_cyrillic_script();
// Exclude only the Spanish language from the decision algorithm.
LanguageDetectorBuilder::from_all_languages_without(&[Language::Spanish]);
// Only decide between English and German.
LanguageDetectorBuilder::from_languages(&[Language::English, Language::German]);
// Select languages by ISO 639-1 code.
LanguageDetectorBuilder::from_iso_codes_639_1(&[IsoCode639_1::EN, IsoCode639_1::DE]);
// Select languages by ISO 639-3 code.
LanguageDetectorBuilder::from_iso_codes_639_3(&[IsoCode639_3::ENG, IsoCode639_3::DEU]);
11. WebAssembly 支持
这个库可以被编译为 WebAssembly (WASM),这使得你可以在任何基于 JavaScript 的项目中使用 Lingua,无论是在浏览器中还是在运行在 Node.js 的后端。
编译的最简单方法是使用 wasm-pack。安装后,你可以构建具有 Web 目标的库,使其可以直接在浏览器中使用。
wasm-pack build --target web
默认情况下,所有 75 种支持的语言都包含在编译的 wasm 文件中,该文件的大小约为 74 MB。如果你只需要某些语言的子集,你可以告诉 wasm-pack 包含哪些语言。
wasm-pack build --target web -- --no-default-features --features "french,italian,spanish"
这将在本仓库的顶层创建一个名为 pkg 的目录,其中包含编译的 wasm 文件和 JavaScript 以及 TypeScript 绑定。然后,在 HTML 文件中,你可以像以下示例那样调用 Lingua
<script type="module">
import init, { LanguageDetectorBuilder } from './pkg/lingua.js';
init().then(_ => {
const detector = LanguageDetectorBuilder.fromAllLanguages().build();
console.log(detector.computeLanguageConfidenceValues("languages are awesome"));
});
</script>
还有一些针对 Node.js 和所有主要浏览器的集成测试。要运行它们,只需说
wasm-pack test --node --headless --chrome --firefox --safari
wasm-pack 的输出将托管在一个 单独的仓库 中,该仓库允许添加更多与 JavaScript 相关的配置、测试和文档。然后 Lingua 也将添加到 npm 注册表 中,允许在 JavaScript 或 TypeScript 项目中轻松下载和安装。
12. 1.7.0 版本的下一步是什么?
查看计划中的问题。
13. 贡献
-
Josh Rotenberg 为使用 Elixir 编程语言 与 Lingua 一起编写了一个包装器。
-
Simon Liang 为使用 Lingua 与 NodeJS 一起编写了一个包装器。
对 Lingua 的任何贡献都将非常感激。请阅读 CONTRIBUTING.md 中的说明,了解如何将新语言添加到库中。
依赖关系
~11–23MB
~491K SLoC