15 个版本 (6 个重大更新)
| 0.7.4 | 2024年7月15日 |
|---|---|
| 0.7.2 | 2024年5月27日 |
| 0.6.1 | 2024年3月28日 |
| 0.3.0 | 2023年10月19日 |
| 0.1.1 | 2023年3月27日 |
#311 在 解析实现
每月 302 次下载
在 stam-python 中使用
325KB
6.5K SLoC
![]()
![]()
![]()
![]()
![]()
![]()
STAM 工具
STAM(用于文本上的 standoff 标注的数据模型)的命令行工具集合。
各种工具被分组在 stam 工具下,并通过子命令调用
stam align- 对两个相似文本进行对齐,映射其坐标空间。stam annotate或stam add- 添加标注或数据集或资源(从文件或通过查询)。stam batch或stam shell- 顺序处理多个子命令,或交互式运行。stam info- 返回有关 STAM 模型的信息。stam init- 初始化新的 STAM 标注存储(从头开始或作为其他存储的复制/合并)。stam import- 从简单的 TSV(制表符分隔值)格式导入 STAM 数据,允许自定义列。stam fromxml- 从基于 XML 的格式(如 xHTML、TEI)导入数据到 STAM。实际上是“解开”文本和标注。stam print- 输出模型中任何资源的文本。stam query或stam export- 查询标注存储并将输出以表格形式导出到简单的 TSV(制表符分隔值)格式。这不是无损的,但提供了对数据的合理视图。它提供了许多灵活性,允许您按需配置输出列。stam validate- 验证 STAM 模型。stam tag- 对纯文本进行基于正则表达式的标记。stam view- 将标注作为查询结果输出到 HTML(或 ANSI 彩色文本)以查看。
对于这些中的许多,您可以通过设置 --verbose 在输出中获取更多详细信息。
或者,工具提供的功能也可以通过 Rust API 作为库公开。
安装
从源码
$ cargo install stam-tools
演示
用法
在子命令之后添加 --help 标志,以获取详细的用法说明。
大多数工具将 STAM JSON 或 CSV 文件作为输入,其中包含注释存储。您也可以指定多个存储,它们将被合并成一个。通过 @include 机制提到的任何文件都将自动加载。
在写入输出时,第一个用作输入的存储文件也将用作输出。您可以通过设置 --dry-run 来防止写入输出文件,或者通过设置 --output 来防止重用第一个输入文件。
您可以通过将文件名设置为 - 来从 stdin 读取和/或向 stdout 输出,这在大多数地方都适用。
这些工具还支持读取和写入 STAM CSV。
工具
stam init & stam annotate
stam init 命令用于使用资源(--resource,纯文本或 STAM JSON)、注释数据集(--annotationset,STAM JSON)和/或注释(--annotations,STAM JSON 中的注释 JSON 列表)初始化新的 STAM 注释存储。
示例,位置参数(最后一个)是要输出的注释存储,它可以是 STAM JSON 或 STAM CSV,由文件扩展名确定
$ stam init --resource document.txt new.store.stam.json
stam annotate 命令几乎与 stam init 相同,区别在于它读取和修改现有的注释存储,而不是从头开始创建一个新的存储。
$ stam annotate --resource document.txt existing.store.stam.json
每次您使用这些命令加载注释和注释数据集时,它们都需要已经是 STAM JSON 格式。要从其他格式导入数据,请使用 stam import。
stam init 和 stam annotate 命令还可以将多个注释存储合并成一个。
如果您想加载 STAM 注释存储(或多个)并在另一个名称和/或其他格式下保存,您也可以使用 stam init(或 stam annotate),关键是要使用一个明确的与输入不同的 --output 文件名。它用于合并存储和/或将 STAM JSON 和 STAM CSV 之间转换。示例
$ stam init --output merged.store.stam.csv mystore1.store.stam.json mystore2.store.stam.json
您还可以将 STAMQL 查询传递给 stam annotate 来添加(或删除)注释。
stam annotate --query 'ADD ANNOTATION WITH DATA "my-vocab" "type" "sentence"; TARGET ?x { SELECT TEXT ?x WHERE RESOURCE "smallquote.txt" OFFSET 0 25; }' demo.store.stam.json
stam info
stam info 命令提供有关注释存储的一些高级详细信息(资源数量、注释等),或者使用 --verbose 标志,它会以相当原始的格式呈现所有它持有的数据。
示例
$ stam info my.store.stam.json
stam query
stam query 工具用于查询注释存储并将选定的 STAM 数据导出到简单的表格数据格式(TSV,制表符分隔值)。您可以使用 --columns 参数精确地配置要导出的列,或者简单地依赖自动检测的默认设置。有关支持列的列表,请参阅 stam query --help。
使用 --query 参数执行完整查询,随后是 STAM 查询语言(STAMQL) 中的查询语句。
示例 1) STAMQL 中的查询
$ stam query --query 'SELECT ANNOTATION ?a WHERE DATA "myset" "pos" = "noun";'
但是,如果您只想获取所有注释、资源、数据,而不想构建查询,可以使用快捷方式,只需通过--type参数指定annotation、key、data、resource或dataset。
示例 2)获取所有注释(如果省略--type和--query,则为默认行为)
$ stam query --type annotation my.store.stam.json
对于某些类型,您可以将--verbose设置为输出更多信息,例如,在查询注释时,它还会输出与注释相关的所有注释数据。请注意,使用此功能时,stam import无法将注释导入回来。
示例 3)以所有数据详细获取所有注释
$ stam query --verbose --type annotation my.store.stam.json
示例 4)获取所有键
$ stam query --type key my.store.stam.json
其中一个更强大的功能是,您可以通过指定一个集合ID、分隔符和键ID(默认为斜杠)来指定自定义列,例如:my_set/part_of_speech。如果您在查询中具有DATA或KEY约束(如示例 1 中所示),则此类列将自动为您添加,如果您不希望这样,则设置--strict-columns。如果键存在,此自定义列将保留相应的值。
示例 5)显式指定包括自定义列在内的列
$ stam query --columns Id,Text,TextResource,BeginOffset,EndOffset,my_set/part_of_speech my.store.stam.json
示例 6)子查询和多个结果变量
$ stam query --query 'SELECT ANNOTATION ?sentence WHERE DATA "myset" "type" = "sentence"; { SELECT ANNOTATION ?word WHERE RELATION ?sentence EMBEDS; DATA "myset" "type" = "word"; }'
这将导致一个TSV文件,其中每个句子都会为句子中的每个单词重复,列中会返回一个结果编号,以及变量名称。
此工具生成的TSV输出不是无损的,即它不能编码STAM支持的所有内容,与STAM JSON和STAM CSV不同。然而,它确实为您提供了大量的灵活性,以快速输出与您的特定目的相关的数据。
对于修改注释存储的查询,请使用stam annotate而不是stam query。
stam export
stam export是stam query的别名,它们的功能是相同的。
stam import
stam import工具用于将TSV(制表符分隔值)文件中的表格数据导入到STAM中。与stam query一样,您可以使用--columns参数精确配置要导入的列。默认情况下,导入功能将尝试将TSV文件的第一行解析为标题,并使用该标题来确定列配置。您通常会设置--annotationset以设置用于自定义列的默认注释集。如果您设置--annotationset my_set,则列如part_of_speech将在该集中解释(与您明确写出my_set/part_of_speech相同)。
以下是一个可能的导入TSV文件的简单示例(带有--annotationset my_set)
Text TextResource BeginOffset EndOffset part_of_speech
Hello hello.txt 0 5 interjection
world hello.txt 6 10 noun
导入功能具有一些特殊功能。如果您的TSV数据没有提及文本资源(s)中的特定偏移量,它们将在导入过程中自动查找!如果文本资源根本不存在,它们可以在某些约束内重建(输出文本可能仅以分词形式存在)。如果您的数据没有明确引用资源,则使用--resource参数指向将作为默认值使用的现有资源,或使用--new-resource进行重建行为。
通过设置--resource hello.txt或--new-resource hello.txt,您可以导入以下更为简化的TSV文件。
Text part_of_speech
Hello interjection
world noun
导入器支持TSV文件中的空行。在重建文本时,这些空行将映射到待构建文本中的换行符(这可以通过--outputdelimiter2进行配置)。同样,行之间的分隔符可以通过--outputdelimiter进行配置,默认为空格。
请注意,stam import无法导入所有stam query可以导出的内容。它只能导入使用--type Annotation(默认)导出的行,其中每一行对应一个注释。
stam grep
stam grep工具可用于在文本中匹配正则表达式,它将返回所有匹配出现的资源标识符、偏移量和精确文本。
示例
$ stam grep -e "[hzwHZW]ij" frogdeep.store.stam.json
example.deep 690:693 Hij 1/1
example.deep 799:802 hij 1/1
制表符分隔的列如下
- 资源ID
- 开始偏移量和结束偏移量(非包含)在Unicode点中
- 匹配的文本
- 当前捕获组以及总捕获组数量(如果有)
stam tag
stam tag工具可用于在文本中匹配正则表达式并随后将注释与找到的结果关联起来。这是一个用于执行例如分词或其他标记任务的工具。
stam tag命令接受一个包含标记器正则表达式规则的TSV文件(示例)。该文件包含以下列
- 正则表达式遵循此语法。表达式可能包含一个或多个捕获组,其中包含将要标记的项目,在这种情况下,任何其他内容都被视为上下文,不会被标记。
- 注释数据集ID
- 数据键ID
- 要设置的值。如果此值遵循$1,$2等语法,则将分配该捕获组的值(1为索引)。
规则示例
#EXPRESSION #ANNOTATIONSET #DATAKEY #DATAVALUE
\w+(?:[-_]\w+)* simpletokens type word
[\.\?,/]+ simpletokens type punctuation
[0-9]+(?:[,\.][0-9]+) simpletokens type number
将此应用于文本资源示例
# first we create a store and add a text resource
$ stam init --resource sometext.txt my.store.stam.json
# then we start the tagging
$ stam tag --rules rules.tsv my.store.stam.json
stam view
stam view工具用于可视化注释。默认可视化是HTML。这将输出一个自包含的静态HTML文档到标准输出(该文档不引用任何外部资产)。另一种可视化是带有ANSI转义码的文本(--format ansi),这适合在终端中显示,而不是在浏览器中。您想要可视化的注释通过--query参数请求,使用STAMQL查询。
--query参数可以指定多次。第一个查询始终是选择查询,它确定主要选择是什么,可以是您能查询的所有包含文本的内容(即资源、注释、文本选择)。
任何后续查询都是高亮查询,它们确定您想要突出显示选择查询产生的选择中的哪些部分。突出显示是通过在文本下方绘制线条并可选地通过显示额外信息的标记来完成的。

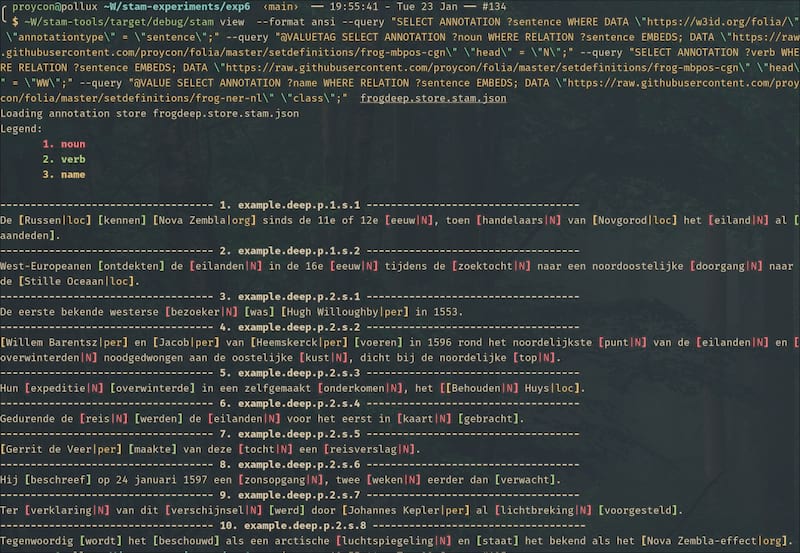
带标记的示例

可以通过在查询前添加以下属性之一来启用标记
@KEYTAG- 输出一个带有键的标记,与查询中第一个DATA约束相关@KEYVALUETAG- 输出包含键和值的标签,与查询中第一个 DATA 约束相关@VALUETAG- 输出仅包含值的标签,与查询中第一个 DATA 约束相关@IDTAG- 输出所选 ANNOTATION 的公共标识符的标签
如果您不想匹配第一个 DATA 约束,而是第 n 个,则指定一个数字来引用查询中按顺序指定的 DATA 约束(1 为索引)。注意,只计算 DATA 约束
@KEYTAG=n - 输出与查询中第 n 个 DATA 约束相关的键标签@KEYVALUETAG=n - 输出与查询中第 n 个 DATA 约束相关的键和值标签@VALUETAG=n - 输出与查询中第 n 个 DATA 约束相关的值标签
还可以提供属性来设置 HTML 输出的样式
@STYLE=class - 将关联指定的 CSS 类(您需要关联适当的样式表)。默认情况下,预先定义了几个简单的类:italic、bold、red、green、blue、super。@HIDE- 不添加高亮下划线,也不将条目添加到图例。如果您只想应用@STYLE,这可能很有用。
如果没有提供属性,则该查询将不显示标签或样式,只显示高亮下划线。
在高亮查询中,主选择查询中的变量可用,您应该在约束中使用它,否则性能将不佳!您的所有查询都应该有变量名,并且它们将出现在图例中(除非您传递 --no-legend)。
这里展示了各种可视化查询的实例:https://github.com/knaw-huc/stam-experiments/tree/main/exp6
使用 --format ansi 输出 ANSI 而不是 HTML 的示例
stam align
stam align 工具用于计算两个文本之间的对齐;它识别两个文本中哪些部分是相同的,并计算两个坐标系之间的映射。实现了两个来自生物信息学的相关序列对齐算法以完成此操作:Smith-Waterman 和 Needleman-Wunsch。这两个算法的得分参数都是可配置的。
生成的对齐结果作为注释添加,称为转置,根据 STAM Transpose 扩展。
此工具允许对任何两个文本选择进行对齐,这些选择通过两个 --query 参数传递,并采用 STAMQL 查询。或者,如果您想对齐两个资源(这是一个常见场景),您只需使用两次 --resource 参数,这是一个更方便的快捷方式。
示例调用
# first we create a store and add a two resource
$ stam init --resource text1.txt --resource text2.txt my.store.stam.json
# then we start the alignment (will be written to the annotation store)
$ stam align --verbose --resource text1.txt --resource text2.txt my.store.stam.json
使用 --verbose 标志,对齐将以简单的 TSV 格式输出到标准输出,包括两边的偏移量,示例摘录
/tmp/218.txt 1373-1439 /tmp/hoof001hwva02_01_0231.txt 1282-1348 "betoonen als dat van Weesp daer ick bij citatie in persoon tegens " "betoonen als dat van Weesp daer ick bij citatie in persoon tegens "
/tmp/218.txt 1444-1508 /tmp/hoof001hwva02_01_0231.txt 1348-1412 "hem begost ende wijder voor heb te procederen tot alsulke peenen" "hem begost ende wijder voor heb te procederen tot alsulke peenen"
您还可以使用stam export --alignments(或stam query --alignments)输出变位和其他对齐。这将输出与上面相同的内容,但多了一个额外的第一列,包含注释(变位)ID,以及一个额外的最后一列,包含变位下所有的注释ID(用管道符分隔)。
stam batch
当您想连续执行多个子命令时,可以使用stam batch工具。
子命令从标准输入读取,可以是交互式的,也可以通过管道输入。子命令的语法与从命令行调用它们的语法相同,但有以下区别
- 没有
stam命令,直接从子命令开始 - 您不能再通过单个子命令将输入/输出参数传递给从/保存到注释存储的加载/保存操作,相反,这些应该在批处理级别作为整体传递。
注释存储在开始时加载一次,如果有任何更改(您没有设置--dry-run),则在结束时保存。这使得stam batch优于仅按顺序运行stam命令;数据不必在每一步后加载和存储。
stam fromxml
stam fromxml工具可以将包含内联注释的XML文件映射到STAM。它将有效地解开内联注释,在一方产生纯文本,在另一方产生纯文本上的STAM注释。
由于可以想象出无数种XML格式,此工具接受一个额外的外部配置文件作为输入,该文件定义了如何将特定的XML格式(例如xHTML、TEI或PageXML)映射到STAM。例如,请参阅此配置文件,其中包含一些内联文档,以帮助您开始。
示例
$ stam fromxml --inputfile tests/test.html --config config/fromxml/html.toml --force-new output.stam.json
一些注意事项
- 如果您想将HTML映射到STAM,请确保您的文档是有效的XHTML并使用正确的XML命名空间。不支持纯HTML。
- 此工具不支持将XML中表述的stand-off注释(例如,在FoLiA中存在)进行转换。对于该格式,作为foliatools的一部分,提供了一个专门的
stam2folia转换器。
依赖关系
~12–23MB
~335K SLoC