47 个版本
| 0.4.8 | 2024 年 5 月 9 日 |
|---|---|
| 0.4.6 | 2024 年 3 月 23 日 |
| 0.4.5 | 2023 年 12 月 17 日 |
| 0.4.2 | 2023 年 10 月 20 日 |
| 0.1.5 | 2022 年 7 月 31 日 |
#16 in 机器学习
2,143 每月下载量
745KB
5.5K SLoC

Forust
轻量级梯度提升包
Forust 是一个用于构建梯度提升决策树集的轻量级包。所有算法代码均使用 Rust 编写,并带有 Python 包装器。可以直接使用 Rust 包,但这里的大部分示例将针对 Python 包装器。它实现了与 XGBoost 包相同的算法,并且在许多情况下将给出几乎相同的结果。
我开发这个包有几个原因,主要是为了更好地理解 XGBoost 算法,另外也是为了有一个有趣的 Rust 项目可以工作,因为我希望能够在更小、更简单的代码库中尝试向算法添加新功能。
包的所有 Rust 代码都可以在 src 目录中找到,而所有 Python 包装器代码都在 py-forust 目录中。
文档
Python API 的文档可以在 这里 找到。
安装
可以从 pypi 直接安装此包。
pip install forust
要在 Rust 项目中使用,请在您的 Cargo.toml 文件中添加以下内容。
forust-ml = "0.4.8"
用法
有关所有方法和相应参数的详细信息,请参阅 python api 文档。
当前包中唯一的公共类是 GradientBooster,它可以用作具有多个目标函数的梯度提升决策树集的训练。
训练和预测
一旦初始化了增强器,就可以将其拟合到提供的数据集和性能字段中。拟合后,可以使用该模型在数据集上进行预测。在本例中,预测结果是给定记录为1的对数几率。
# Small example dataset
from seaborn import load_dataset
df = load_dataset("titanic")
X = df.select_dtypes("number").drop(columns=["survived"])
y = df["survived"]
# Initialize a booster with defaults.
from forust import GradientBooster
model = GradientBooster(objective_type="LogLoss")
model.fit(X, y)
# Predict on data
model.predict(X.head())
# array([-1.94919663, 2.25863229, 0.32963671, 2.48732194, -3.00371813])
# predict contributions
model.predict_contributions(X.head())
# array([[-0.63014213, 0.33880048, -0.16520798, -0.07798772, -0.85083578,
# -1.07720813],
# [ 1.05406709, 0.08825999, 0.21662544, -0.12083538, 0.35209258,
# -1.07720813],
在预测数据时,可以使用 set_prediction_iteration 方法设置预测时使用的最大迭代次数。如果已设置了 early_stopping_rounds,则默认为最佳迭代次数,否则将使用所有树。
如果使用了早期停止,可以使用 get_evaluation_history 方法检索评估历史。
model = GradientBooster(objective_type="LogLoss")
model.fit(X, y, evaluation_data=[(X, y)])
model.get_evaluation_history()[0:3]
# array([[588.9158873 ],
# [532.01055803],
# [496.76933646]])
检查模型
一旦增强器拟合完成,可以使用 text_dump 方法以文本形式检索每个单独的树结构。此方法返回一个列表,长度与模型中树的数目相同。
model.text_dump()[0]
# 0:[0 < 3] yes=1,no=2,missing=2,gain=91.50833,cover=209.388307
# 1:[4 < 13.7917] yes=3,no=4,missing=4,gain=28.185467,cover=94.00148
# 3:[1 < 18] yes=7,no=8,missing=8,gain=1.4576768,cover=22.090348
# 7:[1 < 17] yes=15,no=16,missing=16,gain=0.691266,cover=0.705011
# 15:leaf=-0.15120,cover=0.23500
# 16:leaf=0.154097,cover=0.470007
json_dump 方法执行相同的操作,但返回的是模型的json表示而不是文本字符串。
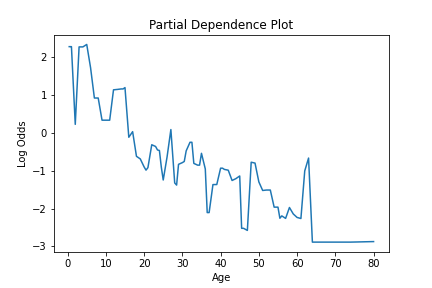
要查看给定特征在模型中的使用估计,可以使用 partial_dependence 方法。此方法计算特征的偏依赖值。对于特征的每个唯一值,这给出了该特征的预测值的估计,所有特征的平均效果被平均。此信息给出了一个给定特征如何影响模型的估计。
可以将此信息绘制出来,以可视化特征在模型中的使用,如下所示。
from seaborn import lineplot
import matplotlib.pyplot as plt
pd_values = model.partial_dependence(X=X, feature="age", samples=None)
fig = lineplot(x=pd_values[:,0], y=pd_values[:,1],)
plt.title("Partial Dependence Plot")
plt.xlabel("Age")
plt.ylabel("Log Odds")
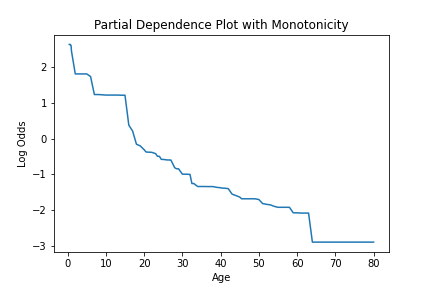
如果创建了一个模型,其中使用 monotone_constraint 参数对特征应用了特定约束,我们可以看到这是如何受影响的。
model = GradientBooster(
objective_type="LogLoss",
monotone_constraints={"age": -1},
)
model.fit(X, y)
pd_values = model.partial_dependence(X=X, feature="age")
fig = lineplot(
x=pd_values[:, 0],
y=pd_values[:, 1],
)
plt.title("Partial Dependence Plot with Monotonicity")
plt.xlabel("Age")
plt.ylabel("Log Odds")
可以使用 calculate_feature_importance 方法计算特征重要性值。此函数将返回一个包含特征及其重要性的字典。请注意,如果特征从未用于分裂,则不会在重要性字典中返回。此函数接受以下参数。
model.calculate_feature_importance("Gain")
# {
# 'parch': 0.0713072270154953,
# 'age': 0.11609109491109848,
# 'sibsp': 0.1486879289150238,
# 'fare': 0.14309120178222656,
# 'pclass': 0.5208225250244141
# }
保存模型
要保存和随后加载训练好的增强器,可以使用 save_booster 和 load_booster 方法。每个方法都接受一个路径,用于将模型写入。模型以json对象的形式保存和加载。
trained_model.save_booster("model_path.json")
# To load a model from a json path.
loaded_model = GradientBooster.load_booster("model_path.json")
依赖关系
~2.2–3.5MB
~69K SLoC