16 个版本
| 0.2.5 | 2022年2月23日 |
|---|---|
| 0.2.4 | 2022年2月22日 |
| 0.1.9 | 2022年2月21日 |
#17 in #列
每月下载量 35 次
510KB
13K SLoC
Static L.A. (线性代数)
一个快速的、最小化、超类型安全的线性代数库。
虽然 ndarray 提供了编译时维度检查,而 nalgebra 提供了一些微妙的检查,但这提供了最大可能的检查。
当执行编译时具有已知列数的 MatrixDxS (矩阵) 和编译时具有已知行数的 MatrixSxD (矩阵) 的加法时,您将得到一个编译时具有已知行数和列数的 MatrixSxS (矩阵),因为现在行数和列数都在编译时已知。这然后允许这些信息通过程序传播,提供出色的编译时检查。
类型如何在程序中传播的一个示例
#![allow(incomplete_features)]
#![feature(generic_const_exprs)]
use static_la::*;
// MatrixSxS<i32,2,3>
let a = MatrixSxS::from([[1,2,3],[4,5,6]]);
// MatrixDxS<i32,3>
let b = MatrixDxS::from(vec![[2,2,2],[3,3,3]]);
// MatrixSxS<i32,2,3>
let c = (a.clone() + b.clone()) - a.clone();
// MatrixDxS<i32,3>
let d = c.add_rows(b);
// MatrixSxS<i32,4,3>
let e = MatrixSxS::from([[1,2,3],[4,5,6],[7,8,9],[10,11,12]]);
// MatrixSxS<i32,4,6>
let f = d.add_columns(e);
在这个例子中,唯一不能在编译时完全检查的操作是
a.clone() +b.clone()d.add_columns(e)
使用此库时必须包含 #![feature(generic_const_exprs)],否则您将收到编译器错误。
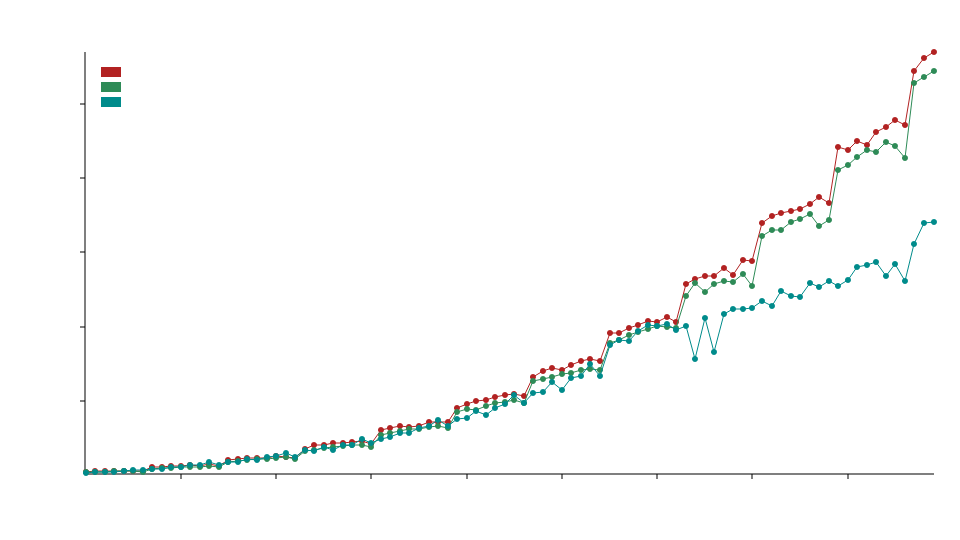
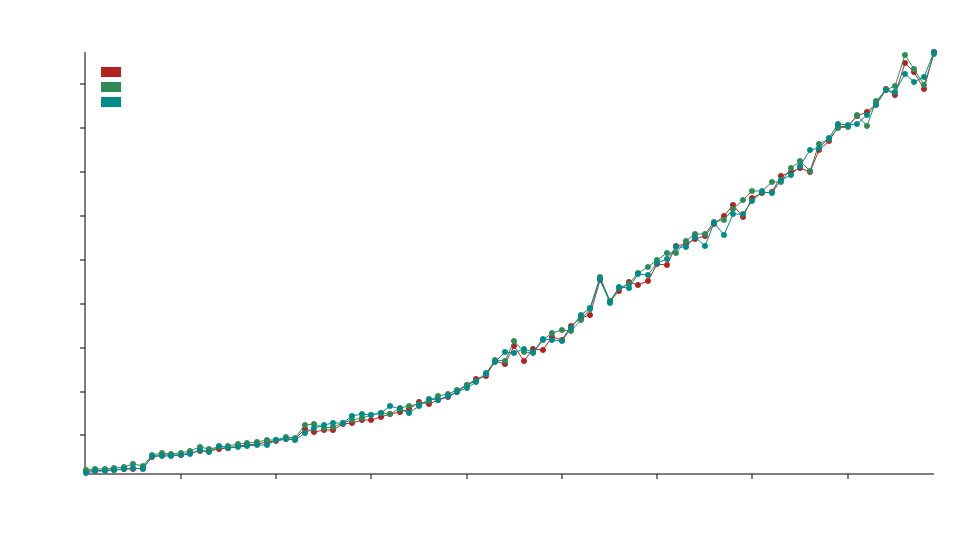
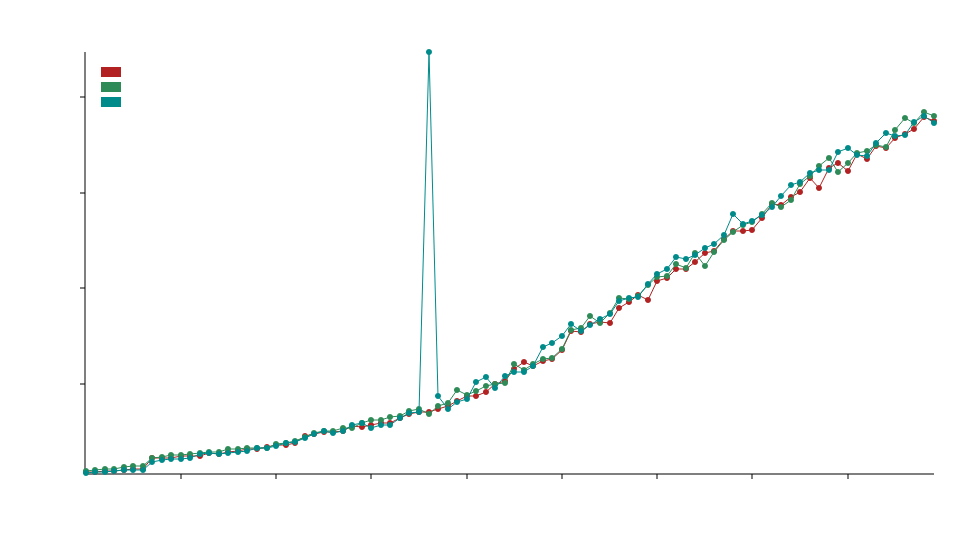
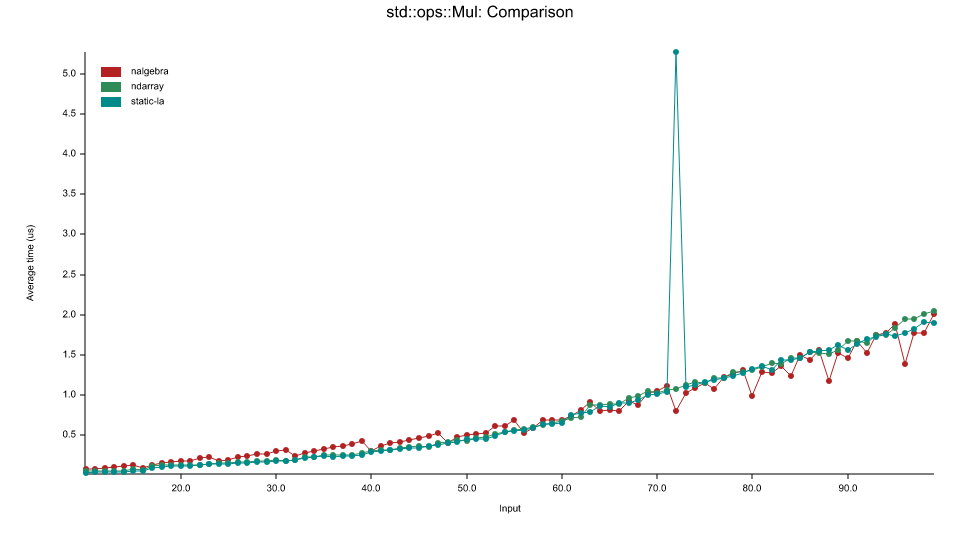
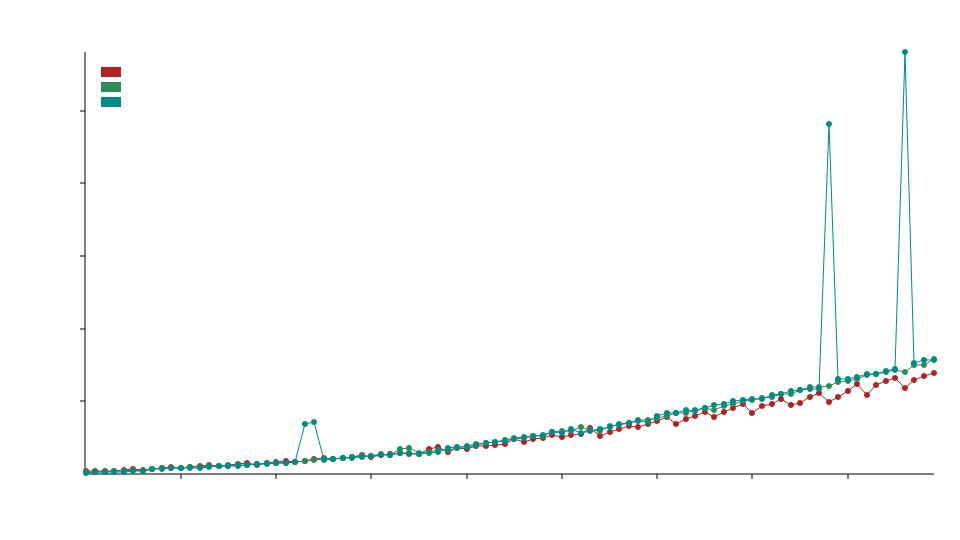
比较
在比较基准测试中,我们使用了 static_la::MatrixDxD<f32>、ndarray::Array2<f32> 和 naglebra::DMatrix<f32>。
我们使用专门化来调用针对浮点类型优化的BLAS函数,这意味着这个库通常在f32和f64操作中会比标准的ndarray和nalgebra表现更好,但在整数操作(例如u32、i32等)中可能表现不佳。
x轴表示矩阵的大小,例如50表示50x50的矩阵。
 |
 |
 |
 |
依赖关系
~0.3–2MB
~34K SLoC