1 个不稳定版本
| 0.1.0 | 2023 年 9 月 26 日 |
|---|
2623 在 命令行工具 中
34KB
483 行
csvdimreduce
基于 CSV 文件的简单降维算法。它读取一个 CSV 文件,根据你指定的列运行算法,并输出增加的坐标列的增强 CSV 文件。这些坐标应该具有从 0 到 1 的值。输入数据应该是预先归一化的。
具有你指定列中相似值的行应该彼此靠近。
注意,该算法在行数上的空间和时间复杂度为二次。
算法
- 对于每一对输入行,计算它们之间的排斥力。所选列中值之间的 L1 距离 加上一个小的常数。
- 添加指定数量(N)的附加列,列中的值为 0 到 1 的随机值。
- 将行解释为 N 维空间中的粒子,这些粒子被吸引到(0.5,0.5,...,0.5)点,但相互排斥。运行指定数量的迭代。
- 可选地,在增加某些维度的“向心”力以“挤压”点云到一个更扁平的形状的同时继续运行粒子模拟。如果你想将行分配为 1 或 2 维坐标,则建议这样做。被“挤压”的维度仍然会出现在输出中,但预期其值将具有
0.5。
我不知道这个算法的正式名称。
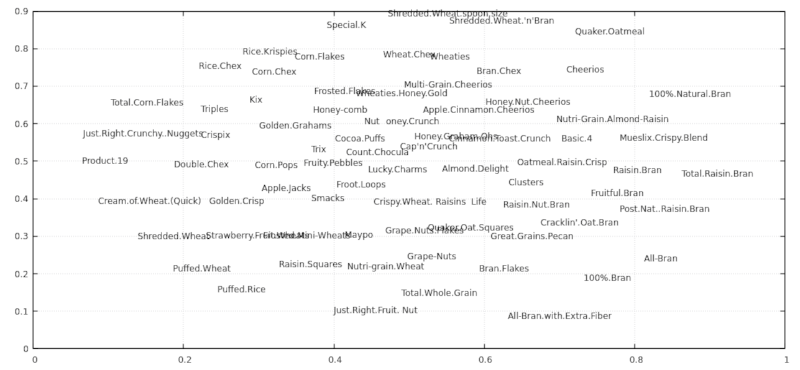
示例 1
使用 80 种谷物 数据集。
$ wget https://gist.github.com/kcoltenbradley/1e8672cb5dff4a4a5e8dbef27ac185f6/raw/9a311a88d5aabdfddd4c9f0d1316612ec33d3d5e/cereal.csv
$ csvdimreduce 4:13 4 -S 2 -N cereal.csv -o output.csv
$ xsv table output.csv | head -n5 | cut -c 1-70
coord1 coord2 coord3 coord4 Cereal Name Manufactu
0.7637 0.1889 0.5000 0.5000 100%_Bran Nabisco
0.8742 0.6806 0.5000 0.5000 100%_Natural_Bran Quaker Oa
0.8334 0.2408 0.5000 0.5000 All-Bran Kelloggs
0.7007 0.0888 0.5000 0.5000 All-Bran_with_Extra_Fiber Kelloggs
$ cat output.csv | tail -n +2 | tr ',_' ' .' | awk '{print $1, $2, $5}' | feedgnuplot --domain --style 0 'with labels' --rangesize 0 2
 .
.
示例 2
让我们将某种规则的单维数据“降低”到二维(使用两个临时的维度进行处理)并可视化算法步骤。
代码
$ seq 0 100 > q.txt
$ seq 50 150 >> q.txt
$ seq 300 350 >> q.txt
$ csvdimreduce --save-each-n-iters 1 --delimiter ' ' --no-header 1 4 -S 2 -F 0.28 ../q.txt -o ../w.txt -n 1000 -r 0.001 -c 10 -C 200 --squeeze-rampup-iters 500
$ mkdir beta
$ render2d_a() { awk '{print $1,$2,$5}' "$1" | feedgnuplot --xmin 0 --xmax 1 --ymin 0 --ymax 1 --domain --style 0 'with labels' --rangesize 0 2 --hardcopy beta/a."$1".png --terminal 'png size 960,1080' &> /dev/null; }
$ render2d_b() { awk '{print $3,$4,$5}' "$1" | feedgnuplot --xmin 0 --xmax 1 --ymin 0 --ymax 1 --domain --style 0 'with labels' --rangesize 0 2 --hardcopy beta/b."$1".png --terminal 'png size 960,1080' &> /dev/null; }
$ export -f render2d_a render2d_b
$ parallel -j12 -i bash -c 'render2d_a {}' -- debug0*csv
$ parallel -j12 -i bash -c 'render2d_b {}' -- debug0*csv
$ ffmpeg -i beta/a.debug'%05d'.csv.png -i beta/b.debug'%05d'.csv.png -filter_complex '[0]pad=1920:1080[a]; [a][1]overlay=960' -g 500 -pix_fmt yuv420p -c librav1e -qp 182 -speed 1 -y seq.webm
待插入视频
安装
从 GitHub 发布 下载预构建的可执行文件或使用 cargo install --path . 或 cargo install csvdimreduce 从源代码安装。
命令行选项
csvdimreduce --help 输出
csvdimreduce
ARGS:
<columns>
List of columns to use as coordinates. First column is number 1. Parsing support ranges with steps like 3,4,10:5:100.
See `number_range` Rust crate for details.
Use `xsv headers your_file.csv` to find out column numbers.
<n_out_coords>
Number of output coordinates (new fields in CSV containing computed values)
This includes temporary coordinates used for squeezing (-S).
[path]
Input csv file. Use stdin if absent.
OPTIONS:
--save-each-n-iters <n>
--no-header
First line of the CSV is not headers
--no-output-header
Do not output CSV header even though input has headers
--delimiter <delimiter>
Field delimiter in CSV files. Comma by default.
--record-delimiter <delimiter>
Override line delimiter in CSV files.
-o, --output <path>
Save file there instead of stdout
--random-seed <seed>
Initial particle positions
-w, --weight <column_number>
Use this column as weights
-n, --n-iters <n>
Basic number of iterations. Default is 100.
Note that complexity of each iteration is quadratic of number of lines in CSV.
-r, --rate <rate>
Initial rate of change i.e. distance the fastest particle travels per iteration.
Default is 0.01.
--inertia-multiplier <x>
Apply each movement multiplpe times, decaying it by this factor. Default is 0.9.
-R, --final-rate <final_decay>
Ramp down rate of change to this value at the end.
-c, --central-force <f>
Attract particles' coordinates to 0.5 with this strenght (relative to average inter-particle forces).
-F, --same-particle-force <f>
Additional repelling force between particles (even those with the same parameters). Default is 0.2
-S, --retain_coords_from_squeezing <n>
After doing usual iterations, perform additional steps to \"flatten\" the shape into fewer dimension count (squeeze phase).
Specified number of coodinaes are retained. For others, the `-c` central force is crancked up to `-C`, so they
(should) become flat \"0.5\" in the end.
This produces better results compared to just having that number of coordinates from the beginning.
--squeeze-rampup-rate <rate>
Use this `-r` rate when doing the squeeze phase.
--squeeze-rampup-iters <n>
User this number of iterations of the first phase of squeezing phase.
This applies to each squeezed dimension sequentially.
-C, --squeeze-final-force <f>
This this central force for the squeezed dimensions.
The force is gradually increased from `-C` to this value during the rampup phase.
--squeeze-final-initial-rate <rate>
Override `-r` rate for the second phase of squeezing. It decays with `-d` each iteration.
--squeeze-final-iters <n>
Number of iterations of the second phase of squeezeing (where central force no longer changes, just to increase precision)
--warmup-iterations <n>
Gradually increase rate from zero during this number of iterations. Defaults to 10.
--debug
Print various values, including algorithm parameter values
-N, --normalize
Automatically normalize the data
-h, --help
Prints help information.
依赖项
~4MB
~67K SLoC