1 个不稳定版本
| 0.1.0 | 2024年7月4日 |
|---|
#321 在 科学
730KB
2.5K SLoC
![]()
Seismic
Seismic 旨在有效地进行学习稀疏嵌入上的检索。设计巧妙地使用两种熟悉的数据结构:逆索引和正向索引。该方法将逆列表组织成几何上紧密相关的块。每个块都配备了一个草图,作为其中包含的向量的摘要。摘要允许我们在检索过程中跳过大量的块,从而节省大量的计算资源。当摘要指示必须检查某个块时,我们使用正向索引来检索其文档的精确嵌入并计算内积。
下图给出了整体设计的概述。
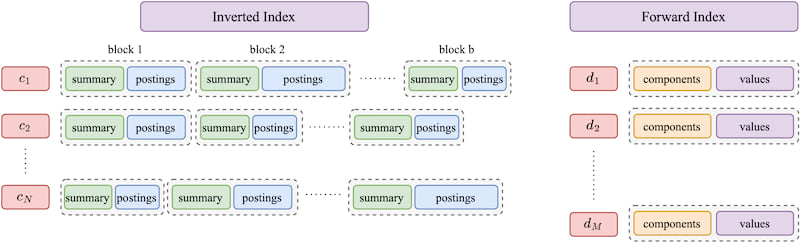
实验结果表明,使用 Seismic 进行的单线程查询处理,在 MSMarco 数据集的各种稀疏嵌入上实现了亚毫秒级的查询延迟,同时保持了高召回率。结果表明,Seismic 比现有的基于逆索引的解决方案快一个到两个数量级,并且在 BigANN 挑战赛(基于图)的获胜(图)提交中表现更为出色。
详见论文 [1] 以获取更多详细信息。
实验结果
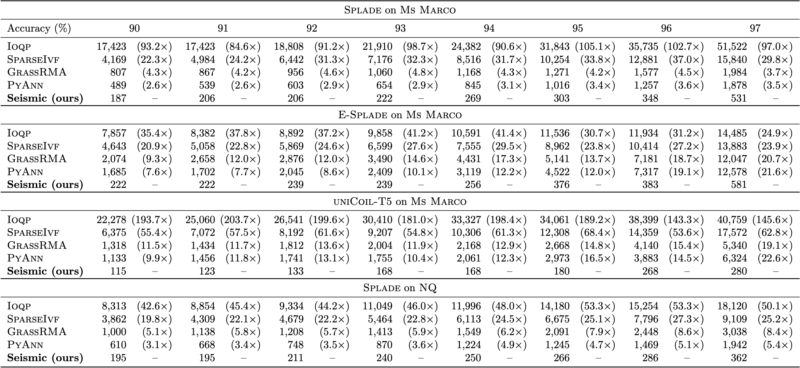
我们在此报告了与其他最先进索引的稀疏向量的比较。有关更详细的实验评估,请参阅论文 [1]。
如何复制实验
要使用 Seismic 运行实验,我们需要使用以下命令编译二进制可执行文件
RUSTFLAGS="-C target-cpu=native" cargo build --release
此命令在 /target/release/ 目录中生成三个可执行文件:build_inverted_index、perf_inverted_index 和 generate_groundtruth。
可执行文件 build_inverted_index 用于构建数据集的反向索引。数据集和查询文件都存储在内部二进制格式中。请参阅Python 脚本部分以获取将数据集从 JSON 格式转换为的脚本。此过程涉及多个参数,用于调节空间/时间权衡。
--n-postings:调节帖子列表的大小,表示每个帖子列表中存储的平均帖子数。--summary-energy:控制摘要的大小,为每个摘要保留整体能量的部分。--centroid-fraction:确定每个帖子列表构建的质心数量,上限为帖子列表长度的一个分数。
对于 MSMarco 上的 Splade,好的选择是 --n-postings 3500,--summary-energy 0.4 和 --centroid-fraction 0.1。
以下命令可以用于在文件 splade.bin.3500.seismic 中创建序列化的地震索引。
./target/release/build_inverted_index -i splade.bin -o splade.bin.3500_0.4_0.1 --centroid-fraction 0.1 --summary-energy 0.4 --n-postings 3500
要执行查询集,请使用可执行文件 perf_inverted_index。两个参数 query-cut 和 heap-factor 在效率与精度之间进行权衡。
--query-cut:搜索算法只考虑查询的前query_cut个成分。--heap-factor:搜索算法跳过估计的点积大于当前堆中前-k个结果的点积最小的块heap_factor倍的块。
以下命令示例说明了这一点
./target/release/perf_inverted_index -i splade.bin.3500_0.4_0.1c -q splade_queries.bin -o results.tsv --query-cut 5 --heap-factor 0.7
查询数据集以二进制内部格式存储。请再次参阅Python 脚本部分,以获取将数据集从 JSON 格式转换为的脚本。
可执行文件打印每个查询的平均运行时间。查询以单线程模式执行。要启用多线程,通过将 Rust 代码中的查询迭代从 queries.iter().take(n_queries).enumerate() 替换为 queries.par_iter().take(n_queries).enumerate() 来修改。
结果写入文件 results.tsv。对于每个查询,有 k 行,每行对应其一个结果。每行遵循以下格式
query_id\tdocument_id\tresult_rank\tdot_product
在这里,query_id 是查询的递增标识符,document_id 是索引数据集中文档的标识符,result_rank 表示它们按其与查询的点积排序的顺序。
要评估检索结果与已计算的真实结果集的准确性,请使用 Python 脚本 scripts/accuracy.py
python3 scripts/accuracy.py groundtruth.tsv results.tsv
这将输出召回率。
数据集的地面真实值可以通过以下方式使用 generate_groundtruth 计算得出:
./target/release/generate_groundtruth -i splade.bin -q splade_queries.bin -o groundtruth.tsv
每个查询的精确前10个结果已写入文件 groundtruth.tsv,格式如上所述。
即使在这里启用了多线程,由于暴力搜索精确查询算法需要为每个查询扫描整个数据集,因此执行可能需要相当长的时间。
地震参数
下表报告了我们用于不同数据集的建筑物参数。
| 数据集 | --n-postings |
--centroid-fraction |
--summary-energy |
|---|---|---|---|
| MSMARCO-Splade | 4000 | 0.1 | 0.4 |
| MSMARCO-Effsplade | 4000 | 0.1 | 0.4 |
| MSMARCO-UniCOIL-T5 | 4000 | 0.1 | 0.4 |
| NQ-Splade | 3500 | 0.15 | 0.5 |
下表报告了用于不同数据集和不同精度级别的查询参数。
如果重新创建索引,由于地震质心的随机选择,结果可能会有所不同。
MSMARCO上的Splade
| $hf$ | $q_c$ | 时间 [ $\mu s$ ] | Accuracy@10 |
|---|---|---|---|
| 0.9 | 3 | 187 | 90.49 |
| 0.9 | 4 | 206 | 92.27 |
| 0.9 | 4 | 206 | 92.27 |
| 0.9 | 5 | 222 | 93.13 |
| 0.9 | 8 | 269 | 94.07 |
| 0.8 | 5 | 303 | 95.69 |
| 0.8 | 6 | 348 | 96.11 |
| 0.7 | 6 | 531 | 97.17 |
MSMARCO上的E-Splade
| $hf$ | $q_c$ | 时间 [ $\mu s $] | Accuracy@10 |
|---|---|---|---|
| 1 | 3 | 222 | 90.99 |
| 1 | 4 | 222 | 90.99 |
| 1 | 4 | 239 | 93.26 |
| 1 | 4 | 239 | 93.26 |
| 1 | 6 | 256 | 94.17 |
| 0.9 | 4 | 376 | 95.95 |
| 0.9 | 5 | 383 | 96.53 |
| 0.8 | 5 | 581 | 97.47 |
MSMARCO上的Unicoil-T5
| $hf$ | $q_c$ | 时间 [ $\mu s$ ] | Accuracy@10 |
|---|---|---|---|
| 1 | 3 | 115 | 90.04 |
| 1 | 4 | 123 | 91.33 |
| 1 | 6 | 133 | 92.07 |
| 0.9 | 3 | 168 | 94.03 |
| 0.9 | 3 | 168 | 94.03 |
| 0.9 | 4 | 180 | 95.13 |
| 0.8 | 4 | 268 | 96.76 |
| 0.8 | 5 | 280 | 97.19 |
MSMARCO上的NQ
| $hf$ | $q_c$ | 时间 [ $\mu s$ ] | Accuracy@10 |
|---|---|---|---|
| 1 | 3 | 195 | 91.25 |
| 1 | 4 | 195 | 91.25 |
| 1 | 6 | 211 | 92.23 |
| 0.9 | 3 | 240 | 93.24 |
| 0.9 | 3 | 266 | 95.17 |
| 0.9 | 4 | 266 | 95.17 |
| 0.8 | 4 | 286 | 96.26 |
| 0.8 | 5 | 362 | 97.18 |
我们提供了一个脚本,用于在训练好的索引上探索搜索参数;该脚本为 scripts/grid_search_only_accuracy.sh。您可以如下使用它:
index_path=""
results_file_path=""
queries_path=""
gt_path=""
bash scripts/grid_search_only_accuracy.sh $index_path $results_file_path $queries_path $gt_path
该脚本将网格搜索的结果写入 results_file_path。要获取每个精度切点的最快配置,只需运行
python scripts/extract_results.py --file-path $results_file_path
Python 脚本
下载数据集
我们实验中使用的 jsonl 格式的嵌入可以从这个 HuggingFace 仓库 下载,包括查询表示。
例如,可以运行以下命令下载并提取 MsMarco 的 Splade 嵌入。
wget https://hugging-face.cn/datasets/tuskanny/seismic-msmarco-splade/resolve/main/documents.tar.gz?download=true -O documents.tar.gz
tar -xvzf documents.tar.gz
或者使用 Huggingface 数据集下载 工具。
转换数据
文档和查询应具有以下格式。每行应是一个具有以下字段的 JSON 格式字符串:
id:必须代表文档 ID 的整数。content:文档的原始内容,作为字符串。此字段为可选。vector:一个字典,其中每个键代表一个标记,其对应的值是分数,例如,{"dog": 2.45}。
这是几个库的标准输出格式,用于训练稀疏模型,如 learned-sparse-retrieval。
脚本 convert_json_to_inner_format.py 允许将相应格式的文件转换为 seismic 内部格式。
python scripts/convert_json_to_inner_format.py --document-path /path/to/document.jsonl --queries-path /path/to/queries.jsonl --output-dir /path/to/output
这将在 /path/to/output 路径生成一个 data 目录,其中包含 documents.bin 和 queries.bin 二进制文件。
如果您从 HuggingFace 仓库下载 NQ 数据集,则需要指定 --input-format nq,因为它使用稍有不同的格式。
使用 Rust 代码
要将 Seismic 库集成到您的 Rust 项目中,请导航到您的项目目录并运行以下 Cargo 命令:
cargo add seismic
此命令将地震库添加到您的项目中。
创建一个玩具数据集
让我们创建一个由具有 f32 值的向量组成的数据集。接下来,我们将此数据集转换为使用半精度浮点数 (half::f16)。最后,我们将检查数据集的向量数量、维度和零元素的数量。
use seismic::SparseDataset;
use half::f16;
let data = vec![
(vec![0, 2, 4], vec![1.0, 2.0, 3.0]),
(vec![1, 3], vec![4.0, 5.0]),
(vec![0, 1, 2, 3], vec![1.0, 2.0, 3.0, 4.0])
];
let dataset: SparseDataset<f16> = data.into_iter().collect::<SparseDataset<f32>>().into();;
assert_eq!(dataset.len(), 3); // Number of vectors
assert_eq!(dataset.dim(), 5); // Number of components
assert_eq!(dataset.nnz(), 9); // Number of non zero components
以下代码展示了如何使用 f32 值读取数据集,并将其量化为 f16。
let dataset = SparseDataset::<f32>::read_bin_file(&input_filename).unwrap().quantize_f16();
构建和查询索引
让我们使用上述玩具数据集构建索引并搜索查询。
use seismic::inverted_index::{Configuration,InvertedIndex};
use seismic::SparseDataset;
use half::f16;
let data = vec![
(vec![0, 2, 4], vec![1.0, 2.0, 3.0]),
(vec![1, 3], vec![4.0, 5.0]),
(vec![0, 1, 2, 3], vec![1.0, 2.0, 3.0, 4.0])
];
let dataset: SparseDataset<f16> = data.into_iter().collect::<SparseDataset<f32>>().into();;
let inverted_index = InvertedIndex::build(dataset, Configuration::default());
let result = inverted_index.search(&vec![0, 1], &vec![1.0, 2.0], 1, 5, 0.7);
assert_eq!(result[0].0, 8.0);
assert_eq!(result[0].1, 1);
有一些构建配置参数可以实验。请参阅 build_inverted_index.rs 代码示例。
其中最重要的是
- 在
PruningStrategy::GlobalThreshold中n_postings:调节倒排列表的大小,表示每个倒排列表存储的帖子平均数量。 - 在
SummarizationStrategy::EnergyPerserving中summary_energy:控制摘要的大小,为每个摘要保留整体能量的部分。 - 在
BlockingStrategy::RandomKmeans中centroid_fraction:确定为每个倒排列表构建的中心点数量,上限为倒排列表长度的分数。
请参阅 Seismic参数 了解不同数据集的推荐值。
请参阅 build_inverted_index.rs 和 perf_inverted_index.rs 代码示例,了解如何在文件上序列化/反序列化索引。
search 方法的签名是
pub fn search(
&self,
query_components: &[u16],
query_values: &[f32],
k: usize,
query_cut: usize,
heap_factor: f32,
) -> Vec<(f32, usize)>
它接受一个查询的稀疏向量 (query_components 和 query_values),k 为 top-k 结果,以及参数 query_cut 和 heap_factor 以在精度和查询时间之间进行权衡。
query_cut:搜索算法只考虑查询的前query_cut个组件。heap_factor:搜索算法跳过一个估计点积大于当前堆中 top-k 结果中最小点积的heap_factor倍的块。
请参阅 Seismic参数 了解它们对不同数据集上的召回率和查询时间的影响。
使用Python接口
我们还提供了一个方便的Python接口。使用 maturin 建立Python接口相对简单
pip install maturin
RUSTFLAGS="-C target-cpu=native" maturin build -r
for whl in target/wheels/*.whl; do pip3 install $whl; done
通过导入 seismic,构建索引并查询它来确认安装成功
from seismic import PySeismicIndex
# We assume that the sparse dataset is in the internal format.
index = PySeismicIndex.build(
input_file,
n_postings=3500,
centroid_fraction=0.1,
truncated_kmeans_training=False,
truncation_size=16,
min_cluster_size=2,
summary_energy=0.4)
# You can serialize and store the index in a file.
index.save(index_path)
# You may later load the index to query it.
index = PySeismicIndex.load(index_path)
# Search can be done either for a single query.
results: List[Tuple[float, int]] = index.search(
query_components=np.array([...], dtype=np.int32),
query_values=np.array([...], dtype=np.float32),
k, query_cut, heap_factor)
# You may also (concurrently) search the index with a batch of
# queries. Assuming the queries are stored in the internal format,
# you can invoke the following function:
results: List[List[Tuple[float, int]]] = index.batch_search(
query_path, k, query_cut, heap_factor, num_threads)
参考文献
- Sebastian Bruch, Franco Maria Nardini, Cosimo Rulli, Rossano Venturini. "Efficient Inverted Indexes for Approximate Retrieval over Learned Sparse Representations." In ACM SIGIR. 2024.
引用许可
本存储库中的源代码受以下引用许可约束
通过下载和使用本软件,您同意在任何使用本软件进行搜索或实验产生的材料中引用以下论文,无论这些材料是研究论文、学位论文、文章、海报、演示文稿还是文档。使用本软件即表示您已同意引用许可。
@inproceedings{Seismic,
author = {Sebastian Bruch and Franco Maria Nardini and Cosimo Rulli and Rossano Venturini},
title = {Efficient Inverted Indexes for Approximate Retrieval over Learned Sparse Representations},
booktitle = {The 47th International ACM SIGIR Conference on Research and Development in Information Retrieval ({SIGIR})},
publisher = {ACM},
year = {2024}
}
依赖项
~10–19MB
~252K SLoC