12 个版本
| 新 0.2.0 | 2024 年 8 月 21 日 |
|---|---|
| 0.1.18 | 2024 年 7 月 22 日 |
| 0.1.15 | 2024 年 6 月 24 日 |
| 0.1.12 | 2024 年 3 月 25 日 |
#18 在 数据库实现
142 每月下载量
1MB
16K SLoC
SeekStorm




SeekStorm 是一个 开源、亚毫秒级全文搜索库 & 多租户服务器,使用 Rust 实现。
开发始于 2015 年,自 2020 年起投入生产,2023 年进行 Rust 版本移植,2024 年开源,仍在开发中。
SeekStorm 采用 Apache License 2.0 许可的开源许可。
博客文章: https://seekstorm.com/blog/sneak-peek-seekstorm-rust/
SeekStorm 高性能搜索库
- 全文搜索
- 真正的实时搜索,性能影响可忽略不计
- 增量索引
- 多线程索引 & 搜索
- 无限字段数量、字段长度 & 索引大小
- 压缩文档存储:ZStandard
- 布尔查询:AND,OR,PHRASE,NOT
- 字段过滤
- 字符串 & 数字范围分面:匹配结果的计数、过滤、排序
- BM25F 和 BM25F_Proximity 排名
- KWIC 片段,高亮显示
- 十亿规模索引
- 语言无关
- API 密钥
- CORS 的 RESTful API
- 索引在 RAM 或内存映射文件中
- 跨平台(Windows,Linux,MacOS)
- SIMD(单指令,多数据)硬件加速支持,
适用于 x86-64(AMD64 和 Intel 64)和 AArch64(ARM,Apple Silicon)。
查询类型
- OR 并集联合
- AND 交集交集
- "" 短语
- - NOT
结果类型
- TopK
- Count
- TopKCount
SeekStorm 多租户搜索服务器
- 带有 RESTful API
- 多租户索引管理
- API 密钥管理
- 嵌入式网络服务器和 UI
- 跨平台:在 Linux 和 Windows 上运行(其他操作系统未经测试)
为什么选择 SeekStorm?
性能
更低延迟,更高吞吐量,更低成本 & 能耗,尤其是对于多字段和并发查询。
低尾延迟确保流畅的用户体验,防止客户和收入的损失。
虽然一些系统依赖专有硬件加速器(FPGA/ASIC)以提高性能,但SeekStorm通过算法优化在通用硬件上实现了类似的性能提升。
一致性
在大型索引期间和之后,SeekStorm不需要资源密集型的段合并,因此查询延迟不可预测。
稳定的延迟 - 由于即时编译,无需担心冷启动成本,没有不可预测的垃圾回收延迟。
可扩展性
即使对于数十亿规模的索引,也能保持低延迟、高吞吐量和低RAM消耗。
无限制的字段数量、字段长度和索引大小。
相关性
与BM25相比,术语邻近度排名提供更相关的结果。
实时性
真正的实时搜索,与NRT相反:每个索引的文档都可以立即搜索,甚至在提交之前和期间。


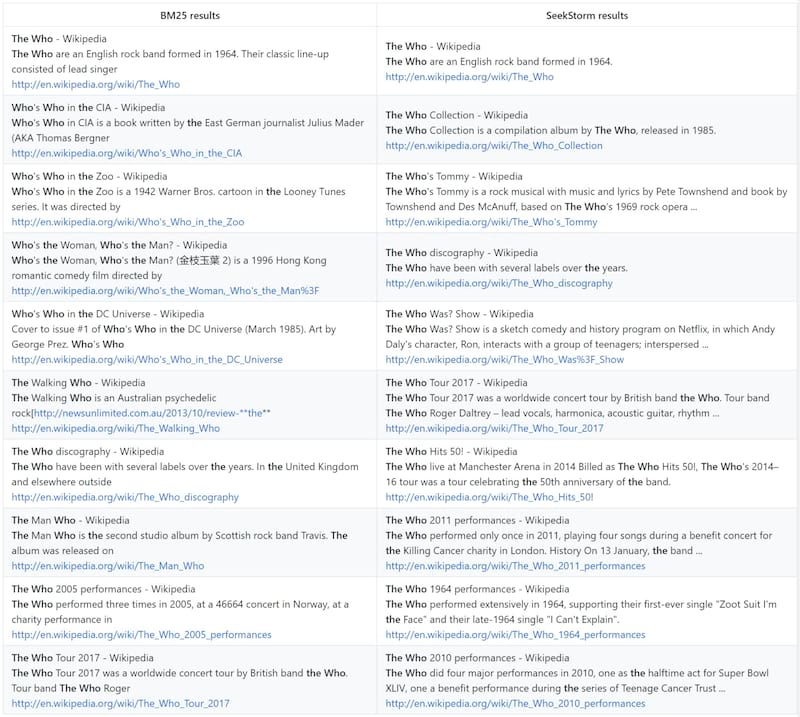
基准测试
使用Tantivy(https://github.com/quickwit-oss/search-benchmark-game/)和Jason Wolfe(https://github.com/jason-wolfe/search-index-benchmark-game/)开发的开源搜索基准游戏,将SeekStorm与其他开源搜索引擎库(BM25词汇搜索)进行比较。
好处
- 使用其他搜索库用于可比性的经过验证的开源基准
- 适配器主要由搜索库作者编写,以保证最大程度的真实性和忠实度
- 结果可以在自己的基础设施上由每个人复制
- 按查询、查询类型和结果类型提供详细的查询结果,以研究优化潜力
详细基准测试结果 https://seekstorm.github.io/search-benchmark-game/
基准代码存储库 https://github.com/SeekStorm/search-benchmark-game/
请参阅我们的博客文章获取更多信息 https://seekstorm.com/blog/sneak-peek-seekstorm-rust/
延迟为什么重要
- 对于单个搜索,搜索速度可能已经足够好。在10毫秒以下,人们无法再感知延迟。与互联网网络延迟相比,搜索延迟可能很小。
- 但当一个服务器或服务用于许多并发用户和请求时,以实现最大扩展、吞吐量和低处理器负载、成本时,搜索引擎性能仍然很重要。
- 使用性能良好的搜索技术,您可以用更少的服务器、更低的延迟、更低的成本和更低的能耗来服务许多并发用户,同时减少碳足迹。
- 它还确保了即使是复杂和具有挑战性的查询也能保持低延迟:即时搜索、模糊搜索、分面搜索以及非常常见术语的并集/交集/短语。
- 除了平均延迟之外,我们还需要减少尾部延迟,这些延迟往往被忽视,但可能导致客户流失、收入损失以及不良的用户体验。
- 始终建议在搜索基础设施中留有足够的性能余量,即使在高并发负载期间也要控制尾部延迟。
- 此外,即使人类用户可能没有注意到延迟,但在需要多次查询的自主股票市场、防御应用或RAG中,延迟仍然可能产生重大差异。
关键词搜索仍然是向量搜索和LLM出现时的核心构建块
尽管炒作周期 https://www.bitecode.dev/p/hype-cycles 可能让你相信,关键词搜索并没有死去,正如NoSQL并不是SQL的终结。
你应该保持一个工具箱,并选择最适合你当前任务的工具。 https://seekstorm.com/blog/vector-search-vs-keyword-search1/
关键词搜索只是对一组文档的过滤,返回包含特定关键词的文档,通常结合BM25等排名指标。这是一个非常基本和核心的功能,但在低延迟下大规模实现具有挑战性。由于功能非常基础,应用领域无限。它是一个组件,与其他组件一起使用。现在可以通过向量搜索和LLM更好地解决一些用例,但对于更多情况,关键词搜索仍然是最佳解决方案。关键词搜索是精确的、无损的,并且非常快,具有更好的扩展性、更低的延迟、更低的成本和能耗。向量搜索通过语义相似性工作,返回给定邻近度和概率的结果。
关键词搜索(词汇搜索)
如果您搜索确切的结果,如专有名词、数字、车牌号、域名和短语(例如,抄袭检测),那么关键词搜索将是您的朋友。另一方面,向量搜索将把您要找的确切结果淹没在众多仅在一定程度上语义相关的结果中。同时,如果您不知道确切的术语,或者您对更广泛的主题、含义或同义词感兴趣,无论使用什么确切的术语,关键词搜索都将失败。
- works with text data only
- unable to capture context, meaning and semantic similarity
- low recall for semantic meaning
+ perfect recall for exact keyword match
+ perfect precision (for exact keyword match)
+ high query speed and throughput (for large document numbers)
+ high indexing speed (for large document numbers)
+ incremental indexing fully supported
+ smaller index size
+ lower infrastructure cost per document and per query, lower energy consumption
+ good scalability (for large document numbers)
+ perfect for exact keyword and phrase search, no false positives
+ perfect explainability
+ efficient and lossless for exact keyword and phrase search
+ works with new vocabulary out of the box
+ works with any language out of the box
+ works perfect with long-tail vocabulary out of the box
+ works perfect with any rare language or domain-specific vocabulary out of the box
+ RAG (Retrieval-augmented generation) based on keyword search offers unrestricted real-time capabilities.
向量搜索
如果您不知道确切的查询术语,或者您对更广泛的主题、含义或同义词感兴趣,无论使用什么确切的查询术语,向量搜索都是完美的。但如果您正在寻找确切的术语,例如专有名词、数字、车牌号、域名和短语(例如,抄袭检测),那么您应该始终使用关键词搜索。向量搜索将把您要找的确切结果淹没在众多仅在一定程度上相关的结果中。它有良好的召回率,但精度较低,延迟较高。它容易产生误报,例如在抄袭检测中,由于确切的单词和词序丢失。
向量搜索使您能够搜索不仅相似文本,还能将任何可以转换为向量的事物:文本、图像(人脸识别、指纹)、音频,并使您能够进行像“queen - woman + man = king”这样的魔法操作。
+ works with any data that can be transformed to a vector: text, image, audio ...
+ able to capture context, meaning, and semantic similarity
+ high recall for semantic meaning (90%)
- lower recall for exact keyword match (for Approximate Similarity Search)
- lower precision (for exact keyword match)
- lower query speed and throughput (for large document numbers)
- lower indexing speed (for large document numbers)
- incremental indexing is expensive and requires rebuilding the entire index periodically, which is extremely time-consuming and resource intensive.
- larger index size
- higher infrastructure cost per document and per query, higher energy consumption
- limited scalability (for large document numbers)
- unsuitable for exact keyword and phrase search, many false positives
- low explainability makes it difficult to spot manipulations, bias and root cause of retrieval/ranking problems
- inefficient and lossy for exact keyword and phrase search
- Additional effort and cost to create embeddings and keep them updated for every language and domain. Even if the number of indexed documents is small, the embeddings have to created from a large corpus before nevertheless.
- Limited real-time capability due to limited recency of embeddings
- works only with vocabulary known at the time of embedding creation
- works only with the languages of the corpus from which the embeddings have been derived
- works only with long-tail vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- works only with rare language or domain-specific vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- RAG (Retrieval-augmented generation) based on vector search offers only limited real-time capabilities, as it can't process new vocabulary that arrived after the embedding generation
向量搜索不是关键词搜索的替代品,而是一种补充 - 最佳用法是在混合解决方案中,结合两种方法的优点。 关键词搜索并未过时,而是经时间考验的。
为什么选择Rust
我们将SeekStorm代码库从C#(部分)迁移到了Rust
- 与C#相比,性能提升2..4倍(延迟和吞吐量)
- 没有慢速启动(没有即时编译的冷启动成本)
- 稳定的延迟(没有垃圾回收延迟)
- 更少的内存消耗(不需要在下次垃圾回收之前增加)
- 没有框架依赖(CLR或JVM虚拟机)
- 预编译而不是即时编译
- 内存安全语言 https://www.whitehouse.gov/oncd/briefing-room/2024/02/26/press-release-technical-report/
Rust非常适合处理大数据和/或许多并发用户的关键性能应用程序 🚀。在性能意识编程语言的支持下,快速算法将更加出色 🙂
架构
请参阅 ARCHITECTURE.md
构建
cargo build --release
⚠ 警告:务必将MASTER_KEY_SECRET环境变量设置为一个秘密,否则您的生成的API密钥将受到威胁。
文档
构建文档
cargo doc --no-deps
本地访问文档
SeekStorm\target\doc\seekstorm\index.html
SeekStorm\target\doc\seekstorm_server\index.html
库的使用
将所需的crate添加到您的项目中
cargo add seekstorm
cargo add tokio
cargo add serde_json
use std::{collections::HashSet, error::Error, path::Path, sync::Arc};
use seekstorm::{index::*,search::*,highlighter::*,commit::Commit};
use tokio::sync::RwLock;
使用异步Rust运行时
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error + Send + Sync>> {
创建索引
let index_path=Path::new("C:/index/");
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":false,"indexed":false}]"#;
let schema=serde_json::from_str(schema_json).unwrap();
let meta = IndexMetaObject {
id: 0,
name: "test_index".to_string(),
similarity:SimilarityType::Bm25f,
tokenizer:TokenizerType::AsciiAlphabetic,
access_type: AccessType::Mmap,
};
let serialize_schema=true;
let segment_number_bits1=11;
let index=create_index(index_path,meta,&schema,serialize_schema,segment_number_bits1,false).unwrap();
let _index_arc = Arc::new(RwLock::new(index));
打开索引(或创建索引的替代方案)
let index_path=Path::new("C:/index/");
let mut index_arc=open_index(index_path,false).await.unwrap();
索引文档
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1"},
{"title":"title2","body":"body2 test","url":"url2"},
{"title":"title3 test","body":"body3 test","url":"url3"}]"#;
let documents_vec=serde_json::from_str(documents_json).unwrap();
index_arc.index_documents(documents_vec).await;
提交文档
index_arc.commit().await;
搜索索引
let query="test".to_string();
let offset=0;
let length=10;
let query_type=QueryType::Intersection;
let result_type=ResultType::TopkCount;
let include_uncommitted=false;
let field_filter=Vec::new();
let result_object = index_arc.search(query, query_type, offset, length, result_type,include_uncommitted,field_filter).await;
显示结果
let highlights:Vec<Highlight>= vec![
Highlight {
field: "body".to_string(),
name:String::new(),
fragment_number: 2,
fragment_size: 160,
highlight_markup: true,
},
];
let highlighter=Some(highlighter(highlights, result_object.query_term_strings));
let return_fields_filter= HashSet::new();
let mut index=index_arc.write().await;
for result in result_object.results.iter() {
let doc=index.get_document(result.doc_id,false,&highlighter,&return_fields_filter).unwrap();
println!("result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get("body"));
}
多线程搜索
let query_vec=vec!["house".to_string(),"car".to_string(),"bird".to_string(),"sky".to_string()];
let offset=0;
let length=10;
let query_type=QueryType::Union;
let result_type=ResultType::TopkCount;
let thread_number = 4;
let permits = Arc::new(Semaphore::new(thread_number));
for query in query_vec {
let permit_thread = permits.clone().acquire_owned().await.unwrap();
let query_clone = query.clone();
let index_arc_clone = index_arc.clone();
let query_type_clone = query_type.clone();
let result_type_clone = result_type.clone();
let offset_clone = offset;
let length_clone = length;
tokio::spawn(async move {
let rlo = index_arc_clone
.search(
query_clone,
query_type_clone,
offset_clone,
length_clone,
result_type_clone,
false,
Vec::new(),
)
.await;
println!("result count {}", rlo.result_count);
drop(permit_thread);
});
}
清除索引
index.clear_index();
删除索引
index.delete_index();
关闭索引
index.close_index();
SeekStorm库版本字符串
let version=version();
println!("version {}",version);
分面搜索 - 快速入门
分面在三个不同的地方定义
- 分面字段在创建索引时的模式中定义
- 分面字段值在索引文档时设置
- 查询分面/分面过滤参数在查询时指定。
分面随后在搜索结果对象中返回。
一个最小的工作示例只需要60行代码。但仅从文档中整理所有内容可能很繁琐。这就是为什么我们在这里提供了一个快速入门示例
将所需的crate添加到您的项目中
cargo add seekstorm
cargo add tokio
cargo add serde_json
添加使用声明
use std::{collections::HashSet, error::Error, path::Path, sync::Arc};
use seekstorm::{index::*,search::*,highlighter::*,commit::Commit};
use tokio::sync::RwLock;
使用异步Rust运行时
#[tokio::main]
async fn main() -> Result<(), Box<dyn Error + Send + Sync>> {
创建索引
let index_path=Path::new("C:/index/");//x
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":true,"indexed":false},
{"field":"town","field_type":"String","stored":false,"indexed":false,"facet":true}]"#;
let schema=serde_json::from_str(schema_json).unwrap();
let meta = IndexMetaObject {
id: 0,
name: "test_index".to_string(),
similarity:SimilarityType::Bm25f,
tokenizer:TokenizerType::AsciiAlphabetic,
access_type: AccessType::Mmap,
};
let serialize_schema=true;
let segment_number_bits1=11;
let index=create_index(index_path,meta,&schema,serialize_schema,segment_number_bits1,false).unwrap();
let mut index_arc = Arc::new(RwLock::new(index));
索引文档
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1","town":"Berlin"},
{"title":"title2","body":"body2 test","url":"url2","town":"Warsaw"},
{"title":"title3 test","body":"body3 test","url":"url3","town":"New York"}]"#;
let documents_vec=serde_json::from_str(documents_json).unwrap();
index_arc.index_documents(documents_vec).await;
提交文档
index_arc.commit().await;
搜索索引
let query="test".to_string();
let offset=0;
let length=10;
let query_type=QueryType::Intersection;
let result_type=ResultType::TopkCount;
let include_uncommitted=false;
let field_filter=Vec::new();
let query_facets = vec![QueryFacet::String {field: "age".to_string(),prefix: "".to_string(),length:u16::MAX}];
let facet_filter=Vec::new();
//let facet_filter = vec![FacetFilter::String { field: "town".to_string(),filter: vec!["Berlin".to_string()],}];
let facet_result_sort=Vec::new();
let result_object = index_arc.search(query, query_type, offset, length, result_type,include_uncommitted,field_filter,query_facets,facet_filter).await;
显示结果
let highlights:Vec<Highlight>= vec![
Highlight {
field: "body".to_owned(),
name:String::new(),
fragment_number: 2,
fragment_size: 160,
highlight_markup: true,
},
];
let highlighter2=Some(highlighter(highlights, result_object.query_terms));
let return_fields_filter= HashSet::new();
let index=index_arc.write().await;
for result in result_object.results.iter() {
let doc=index.get_document(result.doc_id,false,&highlighter2,&return_fields_filter).unwrap();
println!("result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get("body"));
}
显示分面
println!("{}", serde_json::to_string_pretty(&result_object.facets).unwrap());
主函数结束
Ok(())
}
演示时间
使用SeekStorm服务器构建维基百科搜索引擎
一个简单的分步教程,教您如何使用SeekStorm服务器在5个简单步骤中从维基百科语料库构建维基百科搜索引擎。

下载SeekStorm
从GitHub仓库下载SeekStorm
解压到您选择的目录,在Visual Studio code中打开。
或
git clone https://github.com/SeekStorm/SeekStorm.git
构建SeekStorm
安装Rust(如果尚未安装):https://rust-lang.net.cn/tools/install
在Visual Studio Code的终端中输入
cargo build --release
获取维基百科语料库
预处理的英语维基百科语料库(5032105个文档,828 GB解压)。尽管wiki-articles.json有.json扩展名,但它不是一个有效的JSON文件。它是一个文本文件,其中每行都包含一个具有url、标题和body属性的JSON对象。该格式称为ndjson,也称为“换行符分隔的JSON”。
解压缩维基百科语料库。
https://gnuwin32.sourceforge.net/packages/bzip2.htm
bunzip2 wiki-articles.json.bz2
将解压缩的wiki-articles.json移动到发布目录
启动SeekStorm服务器
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
索引
在运行的SeekStorm服务器的命令行中输入'ingest'。
ingest
这创建了演示索引并索引了本地的维基百科文件。
在嵌入式WebUI中开始搜索
在浏览器中打开嵌入式Web UI:http://127.0.0.1
在搜索框中输入查询
测试REST API端点
在VSC中打开src/seekstorm_server/test_api.rest,同时使用VSC扩展“Rest客户端”来执行API调用并检查响应
在test_api.rest中将'individual API key'设置为在您输入'index'时在服务器控制台上显示的API密钥。
删除演示索引
在运行的SeekStorm服务器的命令行中输入'delete'。
delete
关闭服务器
在运行的SeekStorm服务器的命令行中输入'quit'。
在线演示:DeepHN Hacker News搜索
全文搜索3000万Hacker News帖子以及链接的网页

DeepHN演示仍然基于SeekStorm C#代码库。
我们目前正在移植所有缺失的功能。
请参阅下面的路线图。
路线图
Rust端口尚未功能齐全。以下功能目前已移植。
移植
- ✅ 删除文档
- ✅ 分面搜索
- 按任何数值字段排序结果(分数成为一个特殊字段)
- 自动建议,拼写纠正,即时搜索
- 模糊搜索
- 更多分词器类型(词干提取,变音符号,撇号,CJK)
- 查询内并发
改进
- 更快地索引
- 相关性基准:BeIR,MS MARCO
新功能
- 本地向量搜索(目前为PoC)
- 分布式搜索集群(目前为PoC)
依赖关系
~19–31MB
~495K SLoC