5个不稳定版本
| 新版本 0.4.0 |
|
|---|---|
| 0.3.0 | 2024年8月6日 |
| 0.2.1 | 2024年7月31日 |
| 0.2.0 | 2024年7月31日 |
| 0.1.0 | 2024年7月23日 |
#408 在 数据库接口
每月下载量622
99KB
2K SLoC
![]()
![]()
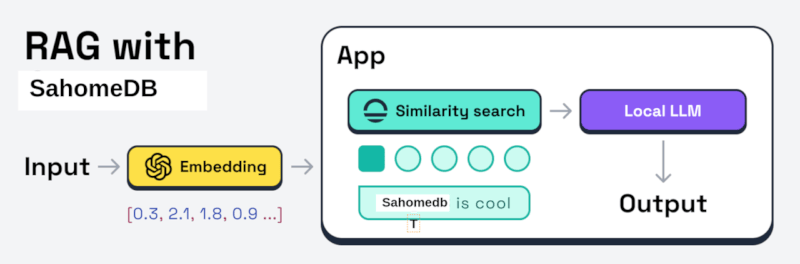
👋 了解萨霍姆DB
萨霍姆DB是一个受SQLite启发的轻量级且易于使用的嵌入式向量数据库。它旨在直接嵌入到您的AI应用程序中。它用Rust编写,并使用Sled作为其持久存储引擎,以将向量集合保存到磁盘。
萨霍姆DB实现了HNSW(分层可导航小世界)作为其索引算法。这是一个许多向量数据库使用的最先进算法。它速度快,可以很好地扩展到大型数据集。
为什么选择萨霍姆DB?
萨霍姆DB非常适合与向量搜索相关的用例,例如使用LLM(大型语言模型)的RAG(检索增强生成)方法来生成上下文感知的输出。以下是一些您可能希望使用萨霍姆DB的原因
⭐️ 嵌入式数据库:萨霍姆DB不需要您设置单独的服务器并进行管理。您可以直接将其嵌入到您的应用程序中,并像常规库一样使用其简单的API。
⭐️ 可选持久性:您可以选择将向量集合持久化到磁盘或将其保留在内存中。默认情况下,每次使用集合时,它都会被加载到内存中,以确保搜索性能。
⭐️ 增量操作:萨霍姆DB允许您在不重建索引的情况下向集合中添加、删除或修改向量。这允许您采取更灵活和高效的存储向量数据的方法。
⭐ 灵活的模式:除了向量之外,您还可以为每个向量存储额外的元数据。这对于存储有关向量的信息很有用,例如原始文本、图像URL或您希望与向量关联的任何其他数据。
⚙️ 使用Rust快速入门
要在Rust中使用萨霍姆DB,您需要在您的Cargo.toml中添加sahomedb。您可以通过运行以下命令实现,这将添加SahomeDB的最新版本到您的项目中。
cargo add sahomedb
之后,您可以将以下代码片段作为参考,开始使用SahomeDB。简而言之,使用Collection来存储您的矢量记录或搜索相似的矢量,并使用Database将矢量集合持久化到磁盘。
简而言之,使用Collection来存储您的矢量记录或搜索相似的矢量,并使用Database将矢量集合持久化到磁盘。
use sahomedb::prelude::*;
fn main() {
// Vector dimension must be uniform.
let dimension = 128;
// Replace with your own data.
let records = Record::many_random(dimension, 100);
let mut config = Config::default();
// Optionally set the distance function. Default to Euclidean.
config.distance = Distance::Cosine;
// Create a vector collection.
let collection = Collection::build(&config, &records).unwrap();
// Optionally save the collection to persist it.
let mut db = Database::new("data/test").unwrap();
db.save_collection("vectors", &collection).unwrap();
// Search for the nearest neighbors.
let query = Vector::random(dimension);
let result = collection.search(&query, 5).unwrap();
println!("Nearest ID: {}", result[0].id);
}
处理元数据
在SahomeDB中,您可以存储每个矢量的附加元数据,这对于将矢量与其他数据关联非常有用。以下代码片段展示了如何将Metadata插入到Record中或从中提取它。
use sahomedb::prelude::*;
fn main() {
// Inserting a metadata value into a record.
let data: &str = "This is an example.";
let vector = Vector::random(128);
let record = Record::new(&vector, &data.into());
// Extracting the metadata value.
let metadata = record.data.clone();
let data = match metadata {
Metadata::Text(value) => value,
_ => panic!("Data is not a text."),
};
println!("{}", data);
}
🐍 使用Python快速入门
SahomeDB还提供了一个Python绑定,允许您将其直接添加到项目中。您可以通过运行以下命令安装SahomeDB的Python库
pip install sahomedb
from sahomedb.prelude import *
if __name__ == "__main__":
# Open the database.
db = Database("data/example")
# Replace with your own records.
records = Record.many_random(dimension=128, len=100)
# Create a vector collection.
config = Config.create_default()
collection = Collection.from_records(config, records)
# Optionally, persist the collection to the database.
db.save_collection("my_collection", collection)
# Replace with your own query.
query = Vector.random(128)
# Search for the nearest neighbors.
result = collection.search(query, n=5)
# Print the result.
print("Nearest neighbors ID: {}".format(result[0].id))
如果您想了解更多关于在实际应用中使用SahomeDB的信息,您可以查看这个Google Colab笔记本,该笔记本演示了如何使用SahomeDB构建一个简单的图像相似度搜索引擎:使用SahomeDB的图像搜索引擎
🎯 基准测试
SahomeDB使用内置的基准测试套件,该套件使用Rust的Criterion crate,我们用它来衡量矢量数据库的性能。
目前,基准测试主要集中在集合的矢量搜索功能性能上。我们正在努力添加更多基准测试来衡量其他操作的性能。
如果您想运行基准测试,可以使用以下命令,该命令将下载基准测试数据集并运行基准测试
cargo bench
内存使用
SahomeDB使用HNSW,与其他索引算法相比,它以内存消耗大而闻名。我们决定使用它,因为它在存储高维矢量的大型数据集时性能良好。
将来,我们可能会考虑添加更多索引算法,使SahomeDB更加灵活,以满足不同的使用场景。如果您有任何关于我们应该添加哪些索引算法的建议,请告诉我们。
无论如何,如果您对SahomeDB的内存使用感兴趣,可以使用以下命令运行内存使用测量脚本。您可以在examples/measure-memory.rs文件中调整参数,以查看内存使用如何变化。
cargo run --example measure-memory
快速结果
尽管结果可能因硬件和数据集而异,但我们想给您一个关于SahomeDB性能的快速印象。以下是一些基准测试的快速结果
10,000个具有128维的矢量
- 搜索时间:0.15毫秒
- 内存使用:6 MB
1,000,000个具有128维的矢量
- 搜索时间:1.5毫秒
- 内存使用:600 MB
这些结果来自一台配备Apple M2 CPU和16 GB RAM的机器。用于基准测试的数据集是由Record::many_random函数或带有附加随机usize作为其元数据的SIFT数据集生成的随机数据集。
🤝 贡献
为该项目做出贡献的最简单方法是将其星标并分享给您的朋友。这将帮助我们扩大社区,并使项目对其他人更加可见。
如果您想进一步贡献您的专业知识,我们非常欢迎您的代码贡献。有关更多信息和建议,请参阅contributing.md。
如果您在该领域有丰富的经验但无法抽出时间贡献代码,我们也欢迎建议、意见或功能请求。我们还在寻找顾问,以帮助指导项目方向和路线图。
此项目仍处于开发初期。我们正在积极工作,并预计API和功能会发生变化。我们不建议在生产环境中使用此项目。
如果您以任何方式对项目感兴趣,请加入我们的Discord。帮助我们一起壮大社区,使SahomeDB变得更好 😁
行为准则
我们致力于创建一个欢迎的社区。任何参与我们项目的人都应表现出尊重,并遵循行为准则。
免责声明
此项目仍处于开发初期。我们正在积极工作,并预计API和功能会发生变化。我们不建议在生产环境中使用此项目。
依赖项
~6–12MB
~143K SLoC