20次发布
使用旧的Rust 2015
| 0.3.8 | 2016年8月8日 |
|---|---|
| 0.3.7 | 2016年6月24日 |
| 0.2.9 | 2016年5月29日 |
| 0.2.6 | 2016年2月27日 |
| 0.1.3 | 2015年7月17日 |
#279 in 地理空间
580KB
4K SLoC
![]()
![]()
![]()
![]()
![]()
简介
 这是一个Rust库,具有FFI绑定,用于快速在WGS84经纬度和英国国家网格 ([epsg:27700](http://spatialreference.org/ref/epsg/osgb-1936-british-national-grid/)) 坐标之间进行转换,使用Rust二进制文件。转换使用标准7元素Helmert变换,并添加了OSTN02校正以提高 [精度](#accuracy)。
这是一个Rust库,具有FFI绑定,用于快速在WGS84经纬度和英国国家网格 ([epsg:27700](http://spatialreference.org/ref/epsg/osgb-1936-british-national-grid/)) 坐标之间进行转换,使用Rust二进制文件。转换使用标准7元素Helmert变换,并添加了OSTN02校正以提高 [精度](#accuracy)。动机
Python(等)相对较慢;此类转换通常以批量方式进行,因此使用FFI进行数量级改进可以节省时间和精力。
精度
仅使用Helmert变换的转换精度约为5米, 不适用于 例如测量中使用的计算或转换。因此,我们使用OSTN02变换,该变换通过结合OSTN02数据对地球参考框架内的局部变化进行调整。有关更多信息,请参阅此处。
启用了OSTN02的功能包括
- convert_bng_threaded(convert_osgb36_threaded的别名)
- convert_bng_threaded_vec ← 上面的FFI版本
- convert_lonlat_threaded(convert_osgb36_to_ll的别名)
- convert_lonlat_threaded_vec ← 上面的FFI版本
- convert_osgb36
- convert_etrs89_to_osgb36
- convert_to_osgb36_threaded ← FFI
- convert_to_osgb36_threaded_vec
- convert_etrs89_to_osgb36_threaded ← FFI
- convert_etrs89_to_osgb36_threaded_vec
- convert_osgb36_to_ll_threaded ← FFI
- convert_osgb36_to_ll_threaded_vec
- convert_osgb36_to_etrs89_threaded ← FFI
- convert_osgb36_to_etrs89_threaded_vec

库使用
作为Rust库
将以下内容添加到您的 Cargo.toml(最新版本显示在此屏幕顶部的第四个徽章中)
lonlat_bng = "x.x.x"
完整的库文档可在此处获得 这里
请注意,lon, lat 坐标在 英国边界框 之外将转换为 (NAN, NAN),无法映射。
库公开的函数可在此处找到
作为FFI库
该库公开的与FFI C兼容的函数有:
convert_to_bng_threaded(数组,数组) ->数组
convert_to_lonlat_threaded(数组,数组) ->数组
convert_to_osgb36_threaded(数组,数组) ->数组
convert_to_etrs89_threaded(数组,数组) ->数组)
convert_osgb36_to_ll_threaded(数组,数组) ->数组
convert_etrs89_to_ll_threaded(数组,数组) ->数组
convert_etrs89_to_osgb36_threaded(数组,数组) ->数组
convert_osgb36_to_etrs89_threaded(数组,数组) ->数组
convert_epsg3857_to_wgs84_threaded(数组,数组) ->数组
FFI和内存管理
如果你的库、模块或脚本使用了FFI函数,它必须实现drop_float_array。未能这样做可能会导致内存泄漏。它具有以下签名:drop_float_array(ar1: 数组, ar2: 数组)
传递给drop_float_array的数组结构必须是你从FFI函数接收的。例如,请参阅数组结构和ffi.rs中的测试,以及convertbng中的_FFIArray类。
构建共享库
运行cargo build --release将在OSX上构建一个名为liblonlat_bng.dylib的工件,在*nix系统上为liblonlat_bng.a。请注意,您必须使用以下步骤为*nix宿主生成liblonlat_bng.so:
ar-x target/release/liblonlat_bng.agcc -shared *.o -otarget/release/liblonlat_bng.so -lrt
作为Python包
convert_bng可在PyPI上获得,适用于OSX和*nix。
pip install convertbng
更多信息可在其仓库中找到。
基准测试
运行了一个CProfile基准测试,比较了在NumPy数组中将1m个随机经纬度对转换的50次运行。
方法论
- 测试了4个Amazon EC2 C4(计算优化)系统。
- 首先通过取五个校准运行的均值来校准系统,每个校准运行包含10万个重复项。
- 然后针对三种配置分别运行基准测试程序。有关详细信息,请参阅benches目录。
- 然后显示每个基准测试的最慢五个函数调用。
结果
| EC2实例类型 | 处理器(vCPU) | Rust Ctypes(s) | Rust Cython(s) | Pyproj(s) | Ctypes与Pyproj的变化百分比 | Pyproj与Cython的变化百分比 |
|---|---|---|---|---|---|---|
| c4.xlarge | 4 | 42.075 | 27.964 | 18.73 | 124.64% | -33.02% |
| c4.2xlarge | 8 | 28.743 | 14.094 | 19.055 | 50.84% | 35.20% |
| c4.4xlarge | 16 | 22.108 | 7.554 | 18.797 | 17.61% | 148.84% |
| c4.8xlarge | 36 | 18.288 | 4.42 | 18.285 | 0.02% | 313.69% |
结论
使用多线程可以获得出色的性能;Pyproj(这是一个编译的Cython二进制文件)在16-CPU系统上比Rust + Ctypes快不到20%,在36-CPU系统上提供相同性能。
编译的Cython二进制文件+Rust在8-CPU系统上比Pyproj快,并且随着CPU数量的增加而超越Pyproj:在36-CPU系统上,它快了超过300%。
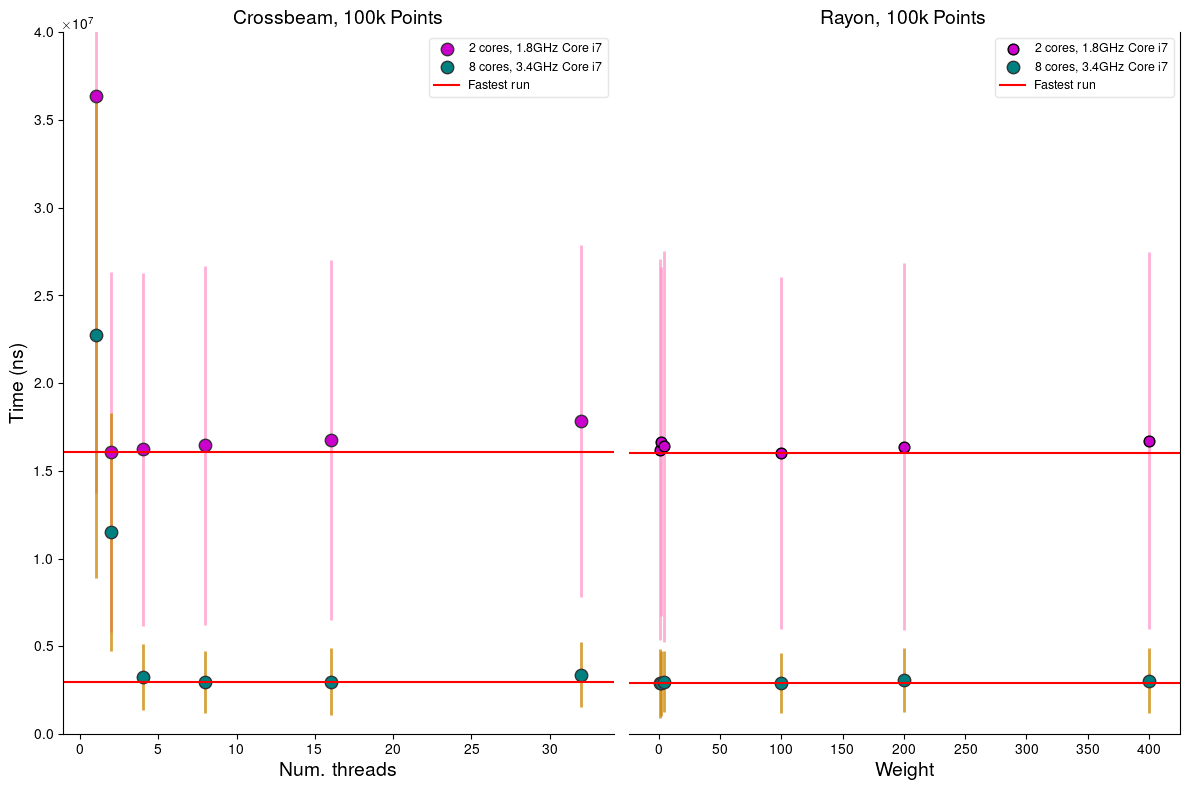
比较Crossbeam和Rayon
比较不同线程和权重对整体速度的影响,使用cargo bench
在2核和8核的i7机器上,使用每个核心一个线程来运行convert_bng_threaded_vec可以获得最佳性能,而Rayon则在选择自己的最佳权重方面做得很好。
许可证
本软件使用了OSTN02数据,版权所有 © Crown版权,Ordnance Survey和英国国防部(MOD)2002。版权所有。在BSD 2-clause 许可证下提供。
† 真的,pyproj?

依赖
~17MB
~423K SLoC