2个不稳定版本
| 0.2.0 | 2024年6月25日 |
|---|---|
| 0.1.11 | 2024年5月27日 |
#368 in 算法
270KB
131 行
CVM算法的Rust实现,用于计数不同元素
此库实现了以下算法:
Chakraborty, S., Vinodchandran, N. V., & Meel, K. S. (2022). Distinct Elements in Streams: An Algorithm for the (Text) Book. 6 pages, 727571 bytes. https://doi.org/10.4230/LIPIcs.ESA.2022.34
相关文章在Quanta上的地址: https://www.quantamagazine.org/computer-scientists-invent-an-efficient-new-way-to-count-20240516/
这是什么意思
计数不同元素问题或基数估计问题是指计算数据流中重复元素的数量。具体来说,如果你想计算一本书中的独特单词数量。如果你有足够的内存,你可以记录你遇到的所有独特元素。然而,由于资源限制,你可能没有足够的运行内存,或者潜在元素的数量可能非常庞大。这种限制在文献中被称为有限存储限制。
为了克服这种限制,已经开发出了流式算法:Flajolet-Martin,LogLog,HyperLogLog。此库实现的算法在这些算法中具有一个特定优势:它非常简单。它不使用哈希,而是使用采样方法计算基数的一个无偏估计。
什么是元素
在此实现中,元素是指实现了Eq + PartialEq + Hash特质的任何事物:各种整数类型、字符串、你实现了这些特质的任何结构体。但是不包括f32 / f64。
所有权
缓冲区必须保留其元素的所有权。在实际操作中,这并不是一个问题:与输入流的大小相比,缓冲区非常小。这也是算法的关键点:你的数据集非常大,而你的工作内存很小;你不想保留原始数据以存储对其的引用!因此,如果你有&str元素,你需要创建新的String来存储它们。如果你在处理文本数据,你可能想要去除标点符号并规范化大小写,因此你无论如何都需要新的String。如果你在处理包含数字值的字符串,首先将它们解析为适当的整数类型(实现了Copy)似乎是一种合理的方法。
更多细节
Don Knuth在其关于算法的论文中(他称之为算法D)中对此进行了描述(https://cs.stanford.edu/~knuth/papers/cvm-note.pdf),比我做得更好。你会注意到在第1页,他描述了他用作数据结构的缓冲区——称为treap——作为一个二叉树。
"它可以容纳至多s个有序对(a,u),其中a是流中的一个元素,u是一个实数,0 ≤ u < 1。"
其中s >= 1。我们的实现不使用treap作为缓冲区;它使用具有FxHash算法的快速HashSet:我们在插入时支付哈希成本,但在步骤D4中的搜索是O(1)。该库最终可能切换到treap实现。
这个库提供了什么
两件事:晶格/库,以及一个命令行实用工具(cvmcount),该实用工具将统计输入文本文件中的唯一字符串。
安装
为x64 Linux、Apple Silicon和Intel以及x64 Windows提供二进制文件和安装说明,可在发布中找到。
如果您已安装Rust,您也可以自己构建: cargo install cvmcount。
CLI示例
cvmcount -t file.txt -e 0.8 -d 0.1 -s 5000
-t --tokens:一个有效的文本文件路径
---epsilon:你希望你的估计值与实际唯一标记数的接近程度。ε越小,你要求的估计越精确。例如,ε = 0.05表示你希望估计值在实际值上下5%的范围内。对于大多数应用,ε = 0.8是一个好的起点。
---delta:算法估计将落在您希望精度范围内的置信水平。更高的置信度(例如,99.9%)意味着你非常确信估计将是准确的,而较低的置信度(例如,90%)意味着估计值可能超出您希望的范围内。对于大多数应用,delta = 0.1是一个好的起点。
----streamsize:用于确定缓冲区大小,可以是一个粗略的估计。越接近流大小,结果越准确。
提供了--help选项。
分析
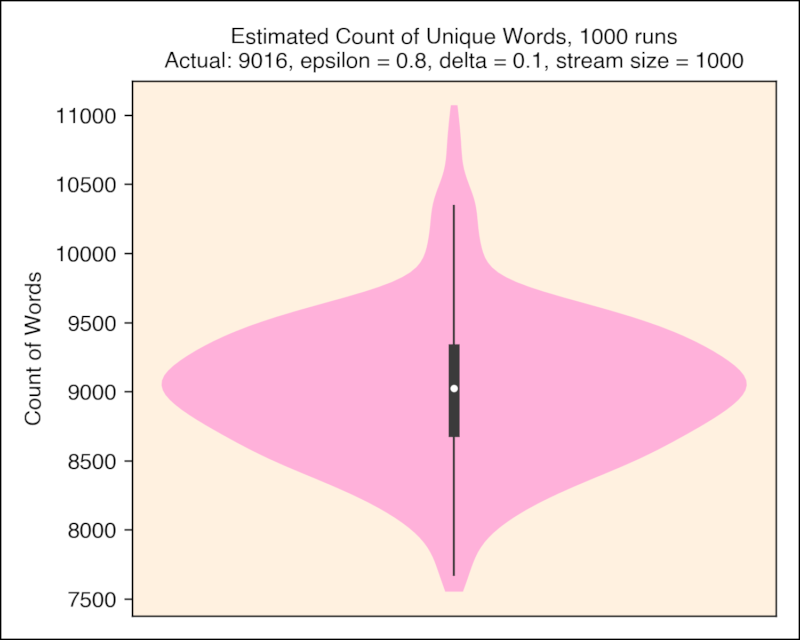
Mean: 9015.744000
Std: 534.076058
Min 7552.000000
25% 8672.000000
50% 9024.000000
75% 9344.000000
Max 11072.00000
注意
如果你在考虑使用这个库,你可能知道它只提供一个估计(在指定的范围内),类似于HyperLogLog。你是用速度换取准确性的!
性能
使用CLI计算418K UTF-8文本文件中的唯一标记需要7.2毫秒±0.3毫秒(在M2 Pro上)。计算10e6个7位整数需要大约13.5毫秒。使用相同的正则表达式和HashSet进行精确计数需要大约18毫秒。运行cargo bench获取更多信息。
实现细节
CLI应用程序使用正则表达式从输入标记中去除标点符号。我假设会有轻微的性能损失,但为了增加实用性,这似乎是一个微不足道的代价。
依赖项
~3.5–4.5MB
~75K SLoC