22个版本 (破坏性更新)
| 0.17.0 | 2024年8月2日 |
|---|---|
| 0.16.0 | 2024年7月26日 |
| 0.15.0 | 2024年7月16日 |
| 0.8.1 | 2024年3月18日 |
#294 in 解析实现
每月324次下载
640KB
17K SLoC
xan,CSV魔术师
xan是一个命令行工具,可以直接从shell中处理CSV文件。
它是用Rust编写的,以实现尽可能高的性能,并且可以轻松处理非常大的CSV文件(千兆字节)。它还可以利用并行性(通过多线程)来尽可能快地完成某些任务。
它可以轻松预览、过滤、切片、聚合、排序、连接CSV文件,并公开了大量可组合的命令,可以将这些命令链式调用以执行各种典型任务。
xan还利用其自身的表达式语言,让您可以执行无法通过最简单命令完成的复杂任务。这种简约语言专门针对CSV数据,并且比评估典型的动态类型语言(如Python、Lua、JavaScript等)更快。
请注意,此工具最初是BurntSushi的xsv的分支(BurntSushi),但在此之后几乎完全重写了,以适应SciencesPo的médialab的使用案例,这些案例基于面向社会科学的网络数据收集和分析(你可能认为CSV现在已经过时了,但在快速判断之前,请阅读我们的情书)。
最后,xan可用于在终端中显示CSV文件,以便轻松探索,甚至可以用于绘制基本的数据可视化。
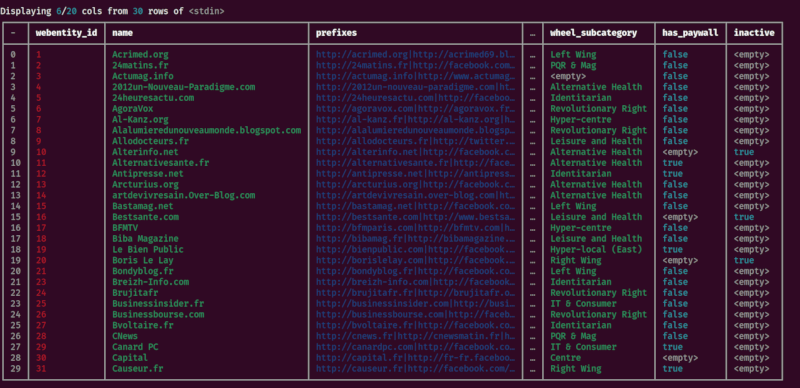
使用xan view在终端中显示CSV文件
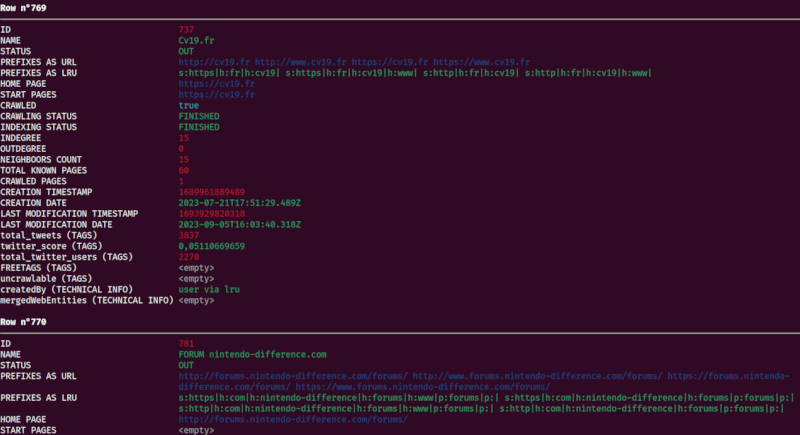
使用xan flatten显示CSV记录的扁平视图
使用xan hist绘制值的直方图

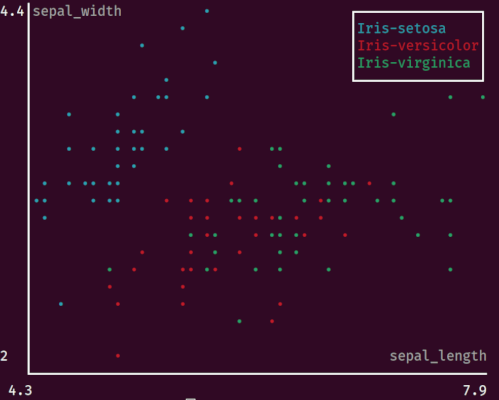
使用 xan plot 绘制散点图
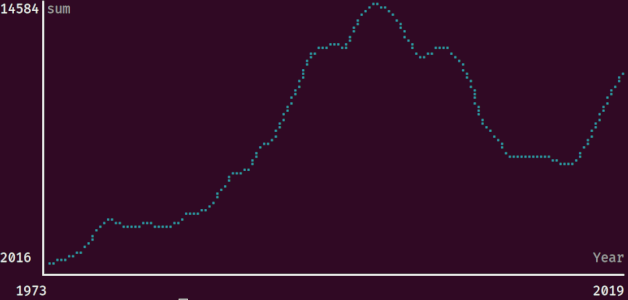
使用 xan plot 绘制时间序列
使用 xan progress 显示进度条
![]()
摘要
如何安装
xan 可以使用 cargo 安装(它通常与 Rust 一起提供)
cargo install xan
快速浏览
通过探索法国媒体的语料库,让我们了解最常用的 xan 命令
下载语料库
curl -LO https://github.com/medialab/corpora/raw/master/polarisation/medias.csv
显示文件的头部
xan headers medias.csv
0 webentity_id
1 name
2 prefixes
3 home_page
4 start_pages
5 indegree
6 hyphe_creation_timestamp
7 hyphe_last_modification_timestamp
8 outreach
9 foundation_year
10 batch
11 edito
12 parody
13 origin
14 digital_native
15 mediacloud_ids
16 wheel_category
17 wheel_subcategory
18 has_paywall
19 inactive
计算行数
xan count medias.csv
478
在终端中预览文件
xan view medias.csv
Displaying 5/20 cols from 10 first rows of medias.csv
┌───┬───────────────┬───────────────┬────────────┬───┬─────────────┬──────────┐
│ - │ name │ prefixes │ home_page │ … │ has_paywall │ inactive │
├───┼───────────────┼───────────────┼────────────┼───┼─────────────┼──────────┤
│ 0 │ Acrimed.org │ http://acrim… │ http://ww… │ … │ false │ <empty> │
│ 1 │ 24matins.fr │ http://24mat… │ https://w… │ … │ false │ <empty> │
│ 2 │ Actumag.info │ http://actum… │ https://a… │ … │ false │ <empty> │
│ 3 │ 2012un-Nouve… │ http://2012u… │ http://ww… │ … │ false │ <empty> │
│ 4 │ 24heuresactu… │ http://24heu… │ http://24… │ … │ false │ <empty> │
│ 5 │ AgoraVox │ http://agora… │ http://ww… │ … │ false │ <empty> │
│ 6 │ Al-Kanz.org │ http://al-ka… │ https://w… │ … │ false │ <empty> │
│ 7 │ Alalumieredu… │ http://alalu… │ http://al… │ … │ false │ <empty> │
│ 8 │ Allodocteurs… │ http://allod… │ https://w… │ … │ false │ <empty> │
│ 9 │ Alterinfo.net │ http://alter… │ http://ww… │ … │ <empty> │ true │
│ … │ … │ … │ … │ … │ … │ … │
└───┴───────────────┴───────────────┴────────────┴───┴─────────────┴──────────┘
在 Unix 上,不要犹豫使用 -p 标志自动将完整输出转发到适当的分页器,并浏览所有列。
读取第一行的扁平表示形式
# NOTE: drop -c to avoid truncating the values
xan slice -l 1 medias.csv | xan flatten -c
Row n°0
───────────────────────────────────────────────────────────────────────────────
webentity_id 1
name Acrimed.org
prefixes http://acrimed.org|http://acrimed69.blogspot…
home_page http://www.acrimed.org
start_pages http://acrimed.org|http://acrimed69.blogspot…
indegree 61
hyphe_creation_timestamp 1560347020330
hyphe_last_modification_timestamp 1560526005389
outreach nationale
foundation_year 2002
batch 1
edito media
parody false
origin france
digital_native true
mediacloud_ids 258269
wheel_category Opinion Journalism
wheel_subcategory Left Wing
has_paywall false
inactive <empty>
搜索行
xan search -s outreach internationale medias.csv | xan view
Displaying 4/20 cols from 10 first rows of <stdin>
┌───┬──────────────┬────────────────────┬───┬─────────────┬──────────┐
│ - │ webentity_id │ name │ … │ has_paywall │ inactive │
├───┼──────────────┼────────────────────┼───┼─────────────┼──────────┤
│ 0 │ 25 │ Businessinsider.fr │ … │ false │ <empty> │
│ 1 │ 59 │ Europe-Israel.org │ … │ false │ <empty> │
│ 2 │ 66 │ France 24 │ … │ false │ <empty> │
│ 3 │ 220 │ RFI │ … │ false │ <empty> │
│ 4 │ 231 │ fr.Sott.net │ … │ false │ <empty> │
│ 5 │ 246 │ Voltairenet.org │ … │ true │ <empty> │
│ 6 │ 254 │ Afp.com /fr │ … │ false │ <empty> │
│ 7 │ 265 │ Euronews FR │ … │ false │ <empty> │
│ 8 │ 333 │ Arte.tv │ … │ false │ <empty> │
│ 9 │ 341 │ I24News.tv │ … │ false │ <empty> │
│ … │ … │ … │ … │ … │ … │
└───┴──────────────┴────────────────────┴───┴─────────────┴──────────┘
选择一些列
xan select foundation_year,name medias.csv | xan view
Displaying 2 cols from 10 first rows of <stdin>
┌───┬─────────────────┬───────────────────────────────────────┐
│ - │ foundation_year │ name │
├───┼─────────────────┼───────────────────────────────────────┤
│ 0 │ 2002 │ Acrimed.org │
│ 1 │ 2006 │ 24matins.fr │
│ 2 │ 2013 │ Actumag.info │
│ 3 │ 2012 │ 2012un-Nouveau-Paradigme.com │
│ 4 │ 2010 │ 24heuresactu.com │
│ 5 │ 2005 │ AgoraVox │
│ 6 │ 2008 │ Al-Kanz.org │
│ 7 │ 2012 │ Alalumieredunouveaumonde.blogspot.com │
│ 8 │ 2005 │ Allodocteurs.fr │
│ 9 │ 2005 │ Alterinfo.net │
│ … │ … │ … │
└───┴─────────────────┴───────────────────────────────────────┘
对文件进行排序
xan sort -s foundation_year medias.csv | xan select name,foundation_year | xan view -l 10
Displaying 2 cols from 10 first rows of <stdin>
┌───┬────────────────────────────────────┬─────────────────┐
│ - │ name │ foundation_year │
├───┼────────────────────────────────────┼─────────────────┤
│ 0 │ Le Monde Numérique (Ouest France) │ <empty> │
│ 1 │ Le Figaro │ 1826 │
│ 2 │ Le journal de Saône-et-Loire │ 1826 │
│ 3 │ L'Indépendant │ 1846 │
│ 4 │ Le Progrès │ 1859 │
│ 5 │ La Dépêche du Midi │ 1870 │
│ 6 │ Le Pélerin │ 1873 │
│ 7 │ Dernières Nouvelles d'Alsace (DNA) │ 1877 │
│ 8 │ La Croix │ 1883 │
│ 9 │ Le Chasseur Francais │ 1885 │
│ … │ … │ … │
└───┴────────────────────────────────────┴─────────────────┘
在某些列上去重
# Some medias of our corpus have the same ids on mediacloud.org
xan dedup -s mediacloud_ids medias.csv | xan count && xan count medias.csv
457
478
在排序时也可以进行去重
xan sort -s mediacloud_ids -u medias.csv
计算频率表
xan frequency -s edito medias.csv | xan view
Displaying 3 cols from 5 rows of <stdin>
┌───┬───────┬────────────┬───────┐
│ - │ field │ value │ count │
├───┼───────┼────────────┼───────┤
│ 0 │ edito │ media │ 423 │
│ 1 │ edito │ individu │ 30 │
│ 2 │ edito │ plateforme │ 14 │
│ 3 │ edito │ agrégateur │ 10 │
│ 4 │ edito │ agence │ 1 │
└───┴───────┴────────────┴───────┘
打印直方图
xan frequency -s edito medias.csv | xan hist
Histogram for edito (bars: 5, sum: 478, max: 423):
media |423 88.49%|━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━|
individu | 30 6.28%|━━━╸ |
plateforme | 14 2.93%|━╸ |
agrégateur | 10 2.09%|━╸ |
agence | 1 0.21%|╸ |
计算描述性统计
xan stats -s indegree,edito medias.csv | xan transpose | xan view -I
Displaying 2 cols from 14 rows of <stdin>
┌─────────────┬───────────────────┬────────────┐
│ field │ indegree │ edito │
├─────────────┼───────────────────┼────────────┤
│ count │ 463 │ 478 │
│ count_empty │ 15 │ 0 │
│ type │ int │ string │
│ types │ int|empty │ string │
│ sum │ 25987 │ <empty> │
│ mean │ 56.12742980561554 │ <empty> │
│ variance │ 4234.530197929737 │ <empty> │
│ stddev │ 65.07326792108829 │ <empty> │
│ min │ 0 │ <empty> │
│ max │ 424 │ <empty> │
│ lex_first │ 0 │ agence │
│ lex_last │ 99 │ plateforme │
│ min_length │ 0 │ 5 │
│ max_length │ 3 │ 11 │
└─────────────┴───────────────────┴────────────┘
评估表达式以过滤文件
xan filter 'batch > 1' medias.csv | xan count
130
要访问表达式语言的 速查表,运行 xan filter --cheatsheet。要显示所有可用的 函数 的完整列表,运行 xan filter --functions。
评估表达式以根据其他列创建新列
xan map 'fmt("{} ({})", name, foundation_year)' key medias.csv | xan select key | xan slice -l 10
key
Acrimed.org (2002)
24matins.fr (2006)
Actumag.info (2013)
2012un-Nouveau-Paradigme.com (2012)
24heuresactu.com (2010)
AgoraVox (2005)
Al-Kanz.org (2008)
Alalumieredunouveaumonde.blogspot.com (2012)
Allodocteurs.fr (2005)
Alterinfo.net (2005)
要访问表达式语言的 速查表,运行 xan map --cheatsheet。要显示所有可用的 函数 的完整列表,运行 xan map --functions。
通过评估表达式转换列
xan transform name 'split(name, ".") | first | upper' medias.csv | xan select name | xan slice -l 10
name
ACRIMED
24MATINS
ACTUMAG
2012UN-NOUVEAU-PARADIGME
24HEURESACTU
AGORAVOX
AL-KANZ
ALALUMIEREDUNOUVEAUMONDE
ALLODOCTEURS
ALTERINFO
要访问表达式语言的 速查表,运行 xan transform --cheatsheet。要显示所有可用的 函数 的完整列表,运行 xan transform --functions。
执行自定义聚合
xan agg 'sum(indegree) as total_indegree, mean(indegree) as mean_indegree' medias.csv | xan view -I
Displaying 1 col from 1 rows of <stdin>
┌────────────────┬───────────────────┐
│ total_indegree │ mean_indegree │
├────────────────┼───────────────────┤
│ 25987 │ 56.12742980561554 │
└────────────────┴───────────────────┘
要访问表达式语言的 速查表,运行 xan agg --cheatsheet。要显示所有可用的 函数 的完整列表,运行 xan agg --functions。最后,要显示所有可用的 聚合函数 的列表,运行 xan agg --aggs。
分组行并执行分组聚合
xan groupby edito 'sum(indegree) as indegree' medias.csv | xan view -I
Displaying 1 col from 5 rows of <stdin>
┌────────────┬──────────┐
│ edito │ indegree │
├────────────┼──────────┤
│ agence │ 50 │
│ agrégateur │ 459 │
│ plateforme │ 658 │
│ media │ 24161 │
│ individu │ 659 │
└────────────┴──────────┘
要访问表达式语言的速查表,运行xan groupby --cheatsheet。要显示可用的函数的完整列表,运行xan groupby --functions。最后,要显示可用的聚合函数列表,运行xan groupby --aggs。
可用命令
所有命令尚未在此README中完全文档化,但所有必要的信息都可以直接从命令行找到。只需运行xan command -h以获取帮助。
- agg - 从CSV文件聚合数据
- behead - 从CSV文件中删除标题
- bins - 将数值列分配到箱中
- cat - 按行或列连接
- count - 计数记录
- datefmt - 将可识别的日期列格式化为指定的格式和时区
- dedup - 删除CSV文件中的重复项
- enum - 通过在前面添加索引列来枚举CSV文件
- explode - 根据某些列分隔符展开行
- filter - 基于评估的表达式仅保留一些CSV行
- fixlengths - 使所有记录具有相同的长度
- flatmap - 对于每个CSV行评估的表达式产生的每个值,输出一行
- flatten - 每行显示一个字段
- fmt - 格式化CSV输出(更改字段分隔符)
- foreach - 遍历CSV文件以执行副作用
- frequency - 显示频率表
- from - 将各种格式转换为CSV
- glob - 创建匹配glob模式的路径的CSV文件
- groupby - 按CSV文件的组聚合数据
- headers - 显示标题名称
- hist - 使用CSV文件的行作为条形的直方图
- implode - 基于一个分叉列合并连续相同的行
- index - 为更快地访问创建CSV索引
- input - 使用特殊引号规则读取CSV数据
- join - 连接CSV文件
- map - 通过对每个CSV行评估表达式创建新列
- merge - 合并多个已排序的CSV文件
- partition - 根据列值对CSV数据进行分区
- plot - 绘制散点图或折线图
- progress - 读取CSV数据时显示进度条
- range - 从数值范围创建CSV文件
- rename - 重命名CSV文件的列
- reverse - 反转CSV数据的行
- sample - 随机抽样CSV数据
- search - 使用正则表达式搜索CSV数据
- select - 从CSV中选择列
- shuffle - 打乱CSV数据
- slice - 从CSV中切片记录
- sort - 对CSV数据进行排序
- split - 将CSV数据分割成多个文件
- stats - 计算基本统计量
- tokenize - 分词文本列
- transform - 通过对每个CSV行评估表达式转换列
- transpose - 转置CSV文件
- union-find - 在CSV边列表上应用并查集算法
- view - 以人类友好的方式预览CSV文件
- vocab - 在分词文档上构建词汇表
通用标志和IO模型
获取帮助
如果您感到困惑,每个命令都有一个 -h/--help 标志,可以打印相关文档。
有关输入和输出格式
所有 xan 命令都期望一个“标准”的CSV文件,例如逗号分隔,并且有适当的双引号转义。但话说回来,xan 也完全能够从常见的文件扩展名,如 .tsv 或 .tab,推断出分隔符。
如果您需要处理具有自定义分隔符的文件,您可以使用 xan input 命令,或者使用所有命令中都有的 -d/--delimiter 标志。
如果您需要输出自定义的CSV方言(例如使用 ; 分隔符),请随时使用 xan fmt 命令。
最后,即使大多数 xan 命令甚至不需要解码文件的字节,但有些可能仍然需要。在这种情况下,xan 将期望正确格式的UTF-8文本。如果您需要处理其他编码(如 latin1)并在 xan 之前进行处理,请使用 iconv 或其他实用工具。
处理无头CSV文件
尽管给列命名是良好的实践,但某些CSV文件根本不包含标题。大多数命令如果给出 -n/--no-headers 标志,就能够处理这些文件。
请注意,此标志始终与输入相关,而不是输出。如果您出于某种原因想删除CSV输出的标题行,请使用 xan behead 命令。
有关stdin
默认情况下,所有命令都会在未指定文件路径时尝试从stdin读取。这使得管道变得容易且舒适,因为它遵守典型的Unix标准。某些命令可能有多个输入(例如 xan join),在这种情况下,stdin通常可以使用 - 字符指定。
# First file given to join will be read from stdin
cat file1.csv | xan join col1 - col2 file2.csv
请注意,如果未指定文件路径,命令也会警告您stdin无法读取。
有关stdout
默认情况下,所有命令都会将其输出打印到stdout(请注意,出于性能原因,此输出通常被缓冲)。
此外,所有命令都公开了一个 -o/--output 标志,可以用来指定输出位置。这可能很有用,如果您不想使用 >(通常在某些Windows外壳中)。在这种情况下,- 作为输出路径意味着转发到stdout。这在编写脚本时可能很有用。
gzip文件
xan 能够直接读取gzip文件(具有 .gz 扩展名)。
表达式语言参考
语法
您可以在终端中执行 xan map --cheatsheet 来找到此帮助信息。
xan script language cheatsheet (use --functions for comprehensive list of
available functions & operators):
. Indexing a column by name:
'name'
. Indexing column with forbidden characters (e.g. spaces, commas etc.):
'col("Name of film")'
. Indexing column by index (0-based):
'col(2)'
. Indexing a column by name and 0-based nth (for duplicate headers):
'col("col", 1)'
. Applying functions:
'trim(name)'
'trim(concat(name, " ", surname))'
. Using operators (unary & binary):
'-nb1'
'nb1 + nb2'
'(nb1 > 1) || nb2'
. Integer literals:
'1'
. Float literals:
'0.5'
. Boolean literals:
'true'
'false'
. Null literals:
'null'
. String literals (can use single or double quotes):
'"hello"'
"'hello'"
. Regex literals:
'/john/'
'/john/i' (case-insensitive)
. Nesting function calls:
'add(sub(col1, col2), mul(col3, col4))'
函数 & 操作符
您可以在终端中执行 xan map --functions 来找到此帮助信息。
# Available functions & operators
(use --cheatsheet for a reminder of the expression language's basics)
## Operators
### Unary operators
!x - boolean negation
-x - numerical negation,
### Numerical comparison
Warning: those operators will always consider operands as numbers and will
try to cast them around as such. For string/sequence comparison, use the
operators in the next section.
x == y - numerical equality
x != y - numerical inequality
x < y - numerical less than
x <= y - numerical less than or equal
x > y - numerical greater than
x >= y - numerical greater than or equal
### String/sequence comparison
Warning: those operators will always consider operands as strings or
sequences and will try to cast them around as such. For numerical comparison,
use the operators in the previous section.
x eq y - string equality
x ne y - string inequality
x lt y - string less than
x le y - string less than or equal
x gt y - string greater than
x ge y - string greater than or equal
### Arithmetic operators
x + y - numerical addition
x - y - numerical subtraction
x * y - numerical multiplication
x / y - numerical division
x % y - numerical remainder
x // y - numerical integer division
x ** y - numerical exponentiation
## String operators
x . y - string concatenation
## Logical operators
x && y - logical and
x and y
x || y - logical or
x or y
x in y
x not in y
## Pipeline operator (using "_" for left-hand size substitution)
'trim(name) | len(_)' - Same as len(trim(name))
'trim(name) | len' - Supports elision for unary functions
'trim(name) | add(1, len(_))' - Can be nested
'add(trim(name) | len, 2)' - Can be used anywhere
## Arithmetics
- abs(x) -> number
Return absolute value of number.
- add(x, y, *n) -> number
Add two or more numbers.
- argmax(numbers, labels?) -> any
Return the index or label of the largest number in the list.
- argmin(numbers, labels?) -> any
Return the index or label of the smallest number in the list.
- ceil(x) -> number
Return the smallest integer greater than or equal to x.
- div(x, y, *n) -> number
Divide two or more numbers.
- floor(x) -> number
Return the smallest integer lower than or equal to x.
- idiv(x, y) -> number
Integer division of two numbers.
- log(x) -> number
Return the natural logarithm of x.
- max(x, y, *n) -> number
- max(list_of_numbers) -> number
Return the maximum number.
- min(x, y, *n) -> number
- min(list_of_numbers) -> number
Return the minimum number.
- mod(x, y) -> number
Return the remainder of x divided by y.
- mul(x, y, *n) -> number
Multiply two or more numbers.
- neg(x) -> number
Return -x.
- pow(x, y) -> number
Raise x to the power of y.
- round(x) -> number
Return x rounded to the nearest integer.
- sqrt(x) -> number
Return the square root of x.
- sub(x, y, *n) -> number
Subtract two or more numbers.
- trunc(x) -> number
Truncate the number by removing its decimal part.
## Boolean operations & branching
- and(a, b, *x) -> T
Perform boolean AND operation on two or more values.
- if(cond, then, else?) -> T
Evaluate condition and switch to correct branch.
- unless(cond, then, else?) -> T
Shorthand for `if(not(cond), then, else?)`.
- not(a) -> bool
Perform boolean NOT operation.
- or(a, b, *x) -> T
Perform boolean OR operation on two or more values.
## Comparison
- eq(s1, s2) -> bool
Test string or sequence equality.
- ne(s1, s2) -> bool
Test string or sequence inequality.
- gt(s1, s2) -> bool
Test that string or sequence s1 > s2.
- ge(s1, s2) -> bool
Test that string or sequence s1 >= s2.
- lt(s1, s2) -> bool
Test that string or sequence s1 < s2.
- ge(s1, s2) -> bool
Test that string or sequence s1 <= s2.
## String & sequence helpers
- compact(list) -> list
Drop all falsey values from given list.
- concat(string, *strings) -> string
Concatenate given strings into a single one.
- contains(seq, subseq) -> bool
Find if subseq can be found in seq. Subseq can
be a regular expression.
- count(seq, pattern) -> int
Count number of times pattern appear in seq. Pattern
can be a regular expression.
- endswith(string, pattern) -> bool
Test if string ends with pattern.
- escape_regex(string) -> string
Escape a string so it can be used safely in a regular expression.
- first(seq) -> T
Get first element of sequence.
- fmt(string, *replacements):
Format a string by replacing "{}" occurrences by subsequent
arguments.
Example: `fmt("Hello {} {}", name, surname)` will replace
the first "{}" by the value of the name column, then the
second one by the value of the surname column.
- get(target, index_or_key, default?) -> T
Get nth element of sequence (can use negative indexing), or key of mapping.
Returns nothing if index or key is not found or alternatively the provided
default value.
- join(seq, sep) -> string
Join sequence by separator.
- last(seq) -> T
Get last element of sequence.
- len(seq) -> int
Get length of sequence.
- ltrim(string, pattern?) -> string
Trim string of leading whitespace or
provided characters.
- lower(string) -> string
Lowercase string.
- replace(string, pattern, replacement) -> string
Replace pattern in string. Can use a regex.
- rtrim(string, pattern?) -> string
Trim string of trailing whitespace or
provided characters.
- slice(seq, start, end?) -> seq
Return slice of sequence.
- split(string, sep, max?) -> list
Split a string by separator.
- startswith(string, pattern) -> bool
Test if string starts with pattern.
- trim(string, pattern?) -> string
Trim string of leading & trailing whitespace or
provided characters.
- unidecode(string) -> string
Convert string to ascii as well as possible.
- upper(string) -> string
Uppercase string.
## Utils
- coalesce(*args) -> T
Return first truthy value.
- col(name_or_pos, nth?) -> string
Return value of cell for given column, by name, by position or by
name & nth, in case of duplicate header names.
- cols(from_name_or_pos?, to_name_or_pos?) -> list
Return list of cell values from the given colum by name or position
to another given column by name or position, inclusive.
Can also be called with a single argument to take a slice from the
given column to the end, or no argument at all to take all columns.
- err(msg) -> error
Make the expression return a custom error.
- headers(from_name_or_pos?, to_name_or_pos?) -> list
Return list of header names from the given colum by name or position
to another given column by name or position, inclusive.
Can also be called with a single argument to take a slice from the
given column to the end, or no argument at all to return all headers.
- index() -> integer?
Return the row's index, if applicable.
- json_parse(string) -> T
Parse the given string as JSON.
- typeof(value) -> string
Return type of value.
- val(value) -> T
Return a value as-is. Useful to return constants.
## IO & path wrangling
- abspath(string) -> string
Return absolute & canonicalized path.
- bytesize(integer) -> string
Return a number of bytes in human-readable format (KB, MB, GB, etc.).
- ext(path) -> string?
Return the path's extension, if any.
- filesize(string) -> int
Return the size of given file in bytes.
- isfile(string) -> bool
Return whether the given path is an existing file on disk.
- pathjoin(string, *strings) -> string
Join multiple paths correctly.
- read(path, encoding?, errors?) -> string
Read file at path. Default encoding is "utf-8".
Default error handling policy is "replace", and can be
one of "replace", "ignore" or "strict".
- write(string, path) -> string
Write string to path as utf-8 text. Will create necessary
directories recursively before actually writing the file.
Return the path that was written.
## Random
- md5(string) -> string
Return the md5 hash of string in hexadecimal representation.
- uuid() -> string
Return a uuid v4.
聚合函数
您可以在终端中执行 xan agg --aggs 来找到此帮助信息。
# Available aggregation functions
(use --cheatsheet for a reminder of how the scripting language works)
Note that most functions ignore null values (empty strings), but that functions
operating on numbers will yield an error if encountering a string that cannot
be safely parsed as a number.
You can always use `coalesce` to nudge values around and force aggregation functions to
consider null values or make them avoid non-numerical values altogether.
Example: considering null values when computing a mean => 'mean(coalesce(number, 0))'
- all(<expr>) -> bool
Returns true if all elements returned by given expression are truthy.
- any(<expr>) -> bool
Returns true if one of the elements returned by given expression is truthy.
- argmin(<expr>, <expr>?) -> any
Return the index of the row where the first expression is minimized, or
the result of the second expression where the first expression is minimized.
- argmax(<expr>, <expr>?) -> any
Return the index of the row where the first expression is maximized, or
the result of the second expression where the first expression is maximized.
- avg(<expr>) -> number
Average of numerical values. Same as `mean`.
- cardinality(<expr>) -> number
Number of distinct values returned by given expression.
- count(<expr>?) -> number
Count the number of row. Works like in SQL in that `count(<expr>)`
will count all non-empy values returned by given expression, while
`count()` without any expression will count every matching row.
- count_empty(<expr>) -> number
Count the number of empty values returned by given expression.
- distinct_values(<expr>, separator?) -> string
List of sorted distinct values joined by a pipe character ('|') by default or by
the provided separator.
- first(<expr>) -> string
Return first seen non empty element of the values returned by the given expression.
- last(<expr>) -> string
Return last seen non empty element of the values returned by the given expression.
- lex_first(<expr>) -> string
Return first string in lexicographical order.
- lex_last(<expr>) -> string
Return last string in lexicographical order.
- min(<expr>) -> number | string
Minimum numerical value.
- max(<expr>) -> number | string
Maximum numerical value.
- mean(<expr>) -> number
Mean of numerical values. Same as `avg`.
- median(<expr>) -> number
Median of numerical values, interpolating on even counts.
- median_high(<expr>) -> number
Median of numerical values, returning higher value on even counts.
- median_low(<expr>) -> number
Median of numerical values, returning lower value on even counts.
- mode(<expr>) -> string
Value appearing the most, breaking ties arbitrarily in favor of the
first value in lexicographical order.
- quantile(<expr>, p) -> number
Return the desired quantile of numerical values.
- q1(<expr>) -> number
Return the first quartile of numerical values.
- q2(<expr>) -> number
Return the second quartile of numerical values. Alias for median.
- q3(<expr>) -> number
Return the third quartile of numerical values.
- stddev(<expr>) -> number
Population standard deviation. Same as `stddev_pop`.
- stddev_pop(<expr>) -> number
Population standard deviation. Same as `stddev`.
- stddev_sample(<expr>) -> number
Sample standard deviation (i.e. using Bessel's correction).
- sum(<expr>) -> number
Sum of numerical values.
- type(<expr>) -> string
Best type description for seen values.
- types(<expr>) -> string
Sorted list, pipe-separated, of all the types seen in the values.
- values(<expr>, separator?) -> string
List of values joined by a pipe character ('|') by default or by
the provided separator.
- var(<expr>) -> number
Population variance. Same as `var_pop`.
- var_pop(<expr>) -> number
Population variance. Same as `var`.
- var_sample(<expr>) -> number
Sample variance (i.e. using Bessel's correction).
高级用例
并行读取文件
假设您的CSV文件中的一列包含文件路径,相对于某个downloaded文件夹,并且您想要确保所有这些路径都包含某个字符串(也许您爬取了某个网站,并想通过搜索您的用户名的出现来确保您已正确登录)
xan progress files.csv | \
xan filter -p 'pathjoin("downloaded", path) | read | !contains(_, /yomguithereal/i)' > not-logged.csv
生成分页URL的CSV文件
假设您想使用我们另一个名为minet的工具从Hacker News下载最新的50页。
您可以将xan range传递给xan select -e,然后传递给minet fetch
xan range -s 1 50 -i | \
xan select -e '"https://news.ycombinator.com/?p=".n as url' | \
minet fetch url -i -
传递给xargs
假设您想删除所有路径在CSV文件某列中的文件。您可以选择该列,并用xan格式化后再传递给xargs
xan select path files.csv | \
xan behead | \
xan fmt --quote-never | \
xargs -I {} rm {};
常见问题解答
如何显示垂直条形图?
旋转您的屏幕 ;)
依赖关系
~36–49MB
~787K SLoC