3个版本
| 0.1.2 | 2024年7月4日 |
|---|---|
| 0.1.1 | 2024年7月4日 |
| 0.1.0 | 2024年7月4日 |
#204 在 科学
39KB
253 行
并行拓扑批量运行器
拓扑批量运行器是一个小巧的库,允许高效地并行执行拓扑排序的操作。简单的拓扑排序提供了一个线性列表,但并不容易并行化。
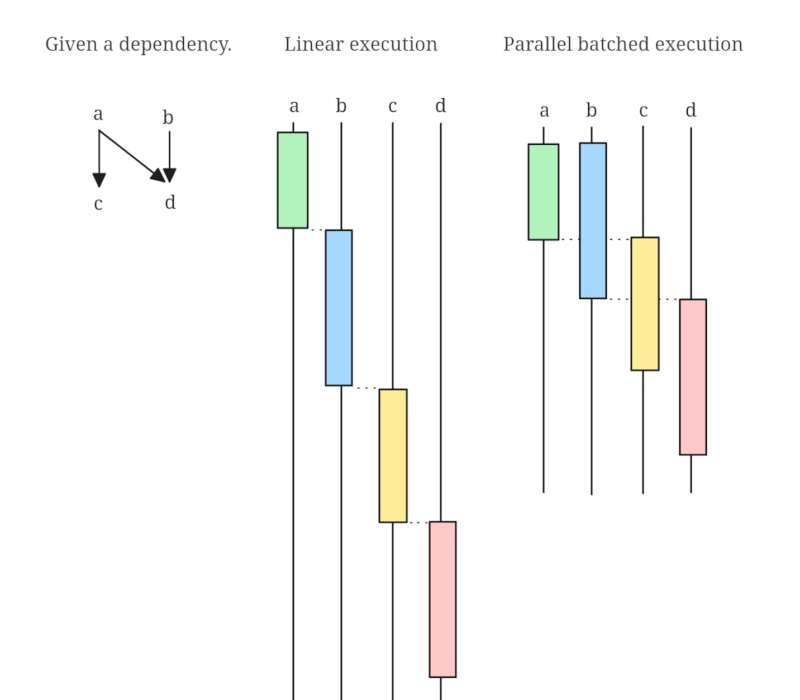
请看以下示例。
我们有3个操作,A、B和C,其中B和C依赖于A(意味着A需要先执行,然后B或C可以任意顺序执行)。线性执行顺序将是A然后B然后C或A然后C然后B。然而,一旦A被计算,B和C可以并行执行。这正是这个库的目的。
一个更实际的例子
/// The structure responsible running the dependent operations. Must be Send and Sync.
struct ExecutorExample {
/// Inner data.
}
/// The implementation of the execution. ID represents the link to the topological structure.
impl CallableByID<usize> for ExecutorExample {
fn call(&self, id: usize) {
/// Code to execute parallel - for an ID that came after all of its dependencies.
}
}
/// Next setup the dependency graph:
let mut dependency_graph: HashMap<usize, Vec<usize>> = HashMap::new();
dependency_graph.insert(0, vec![4, 2, 5]);
/// ...
/// Initialize executor and run:
let topological_batch_provider = TopologicalBatchProvider::new(dependency_graph.clone())?;
let runner = ThreadPoolRunner::new(8);
let executor = Arc::new(ExecutorExample {});
runner.run(topological_batch_provider, executor);
拓扑排序是通过ID定义的,这些ID作为计算单元的指针。ID应该尽可能轻(例如 usize),以便高效地处理。