15个版本 (5个破坏性更新)
| 新版本 0.6.5 | 2024年8月10日 |
|---|---|
| 0.6.4 | 2024年7月24日 |
| 0.6.3 | 2024年1月17日 |
| 0.5.1 | 2023年12月14日 |
| 0.1.1 | 2023年12月12日 |
#115 在 并发
每月 1,126 次下载
100KB
751 行
批量处理不是问题
我有99个问题,但批量处理不是其中一个...
将多个项目批量处理为一个单独的单位。
为什么
有时一次处理多个项目比逐个处理更有效率。尤其是当处理步骤有多个项目可以共享的开销时。
示例:向数据库插入多行
例如,每次数据库操作——例如INSERT——都需要往返数据库的开销。
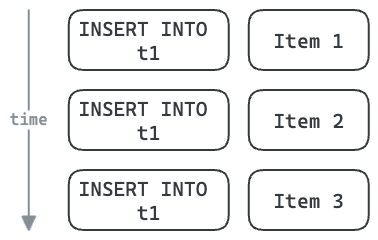
多行插入可以在许多项目之间共享这个开销。这也允许我们使用单个数据库连接来插入这些三个项目,如果连接池高度利用,则可能减少竞争。

示例:使用事务和锁定
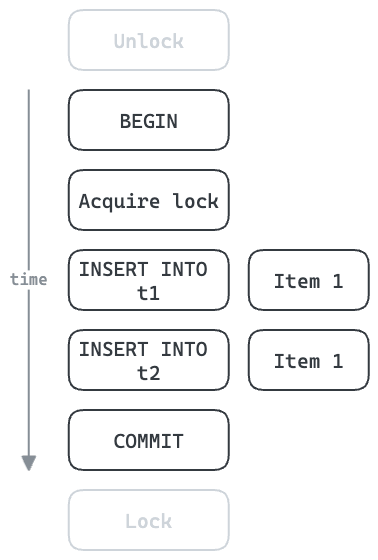
数据库表的插入通常可以并发进行。在某些情况下,这些操作必须按顺序进行,并使用锁定强制执行。这可能导致显著的吞吐量瓶颈。
在下面的示例中,每个项目需要五次往返数据库。所有后续项目必须等待此操作完成。如果每次往返需要1ms,那么每个项目至少需要5ms,或每秒最多处理200个项目。
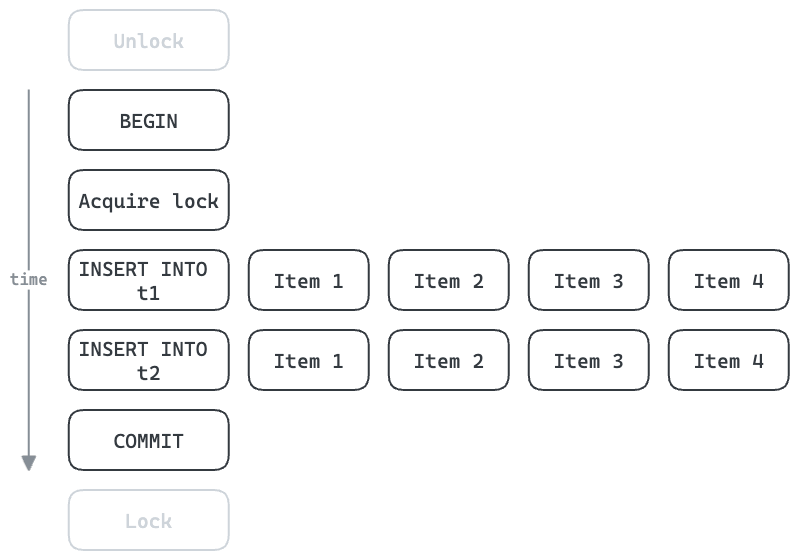
使用批量处理,我们可以提高吞吐量。获取/释放锁和开始/提交事务可以用于整个批次。如果每个批次有四个项目,则可以将理论上的最大吞吐量提高到每秒800个项目。在现实中,每个INSERT处理的行越多,所花费的时间就越长,但多行插入可以非常高效。
如何
在后台运行一个工作任务,并将项目提交给它进行批量处理。批次在它们自己的任务中并发处理。
示例
use std::{time::Duration, marker::Send, sync::Arc};
use async_trait::async_trait;
use batch_aint_one::{Batcher, BatchingPolicy, Limits, Processor};
/// A simple processor which just sleeps then returns a mapped version
/// of the inputs.
#[derive(Debug, Clone)]
struct SleepyBatchProcessor;
#[async_trait]
impl Processor<String, String, String> for SleepyBatchProcessor {
async fn process(
&self,
key: String,
inputs: impl Iterator<Item = String> + Send,
) -> Result<Vec<String>, String> {
tokio::time::sleep(Duration::from_millis(10)).await;
// In this example:
// - `key`: "Key A"
// - `inputs`: ["Item 1", "Item 2"]
Ok(inputs.map(|s| s + " processed for " + &key).collect())
}
}
tokio_test::block_on(async {
// Create a new batcher.
// Put it in an Arc so we can share it between handlers.
let batcher = Arc::new(Batcher::new(
// This will process items in a background worker task.
SleepyBatchProcessor,
// Set some limits.
Limits::default()
.max_batch_size(2)
.max_key_concurrency(1),
// Process a batch when it reaches the max_batch_size.
BatchingPolicy::Size,
));
// Request handler 1
let batcher1 = batcher.clone();
tokio::spawn(async move {
// Add an item to be processed and wait for the result.
let output = batcher1.add("Key A".to_string(), "Item 1".to_string()).await.unwrap();
assert_eq!("Item 1 processed for Key A".to_string(), output);
});
// Request handler 2
let batcher2 = batcher.clone();
tokio::spawn(async move {
// Add an item to be processed and wait for the result.
let output = batcher2.add("Key A".to_string(), "Item 2".to_string()).await.unwrap();
assert_eq!("Item 2 processed for Key A".to_string(), output);
});
});
路线图
- 测试
- 更好的错误处理
- 文档
- 为什么——激励示例
- 代码示例
- 跟踪/记录
- 指标?
进一步阅读
依赖关系
~2.5–4MB
~69K SLoC