11 个版本
| 0.4.2 | 2021 年 4 月 1 日 |
|---|---|
| 0.4.1 | 2021 年 4 月 1 日 |
| 0.4.0 | 2020 年 8 月 4 日 |
| 0.3.0 | 2020 年 5 月 28 日 |
| 0.1.4 | 2020 年 1 月 8 日 |
#823 在 算法 中
962 每月下载量
用于 textspan
27KB
270 行
适用于 Rust 和 Python 的强大且快速的分词对齐库
![]()
![]()
![]()
演示: demo
Rust 文档: docs.rs
博客文章: 如何有效地和鲁棒地计算 BERT 和 spaCy 分词之间的对齐
使用 (Python)
- 安装
$ pip install -U pip # update pip
$ pip install pytokenizations
- 从源码安装
此库使用 maturin 构建 wheel。
$ git clone https://github.com/tamuhey/tokenizations
$ cd tokenizations/python
$ pip install maturin
$ maturin build
现在 wheel 已创建在 python/target/wheels 目录中,您可以使用 pip install *whl 安装它。
get_alignments
def get_alignments(a: Sequence[str], b: Sequence[str]) -> Tuple[List[List[int]], List[List[int]]]: ...
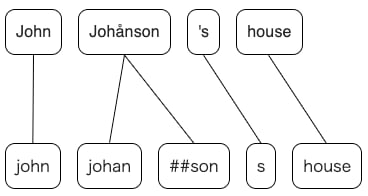
返回两种不同分词的对应映射
>>> tokens_a = ["å", "BC"]
>>> tokens_b = ["abc"] # the accent is dropped (å -> a) and the letters are lowercased(BC -> bc)
>>> a2b, b2a = tokenizations.get_alignments(tokens_a, tokens_b)
>>> print(a2b)
[[0], [0]]
>>> print(b2a)
[[0, 1]]
a2b[i] 是表示从 tokens_a 到 tokens_b 对齐的列表。
使用 (Rust)
查看这里: docs.rs
相关
- 算法概述
- 博客文章
- seqdiff 用于差异处理。
- textspan
- explosion/spacy-alignments: 💫 Yohei Tamura 的 Rust 分词库的 spaCy 包
- 此库的 Python 绑定由 Explosion 维护,作者是 spaCy。如果您觉得安装 pytokenizations 困难,请尝试这个。
依赖关系
~1MB
~40K SLoC