8 个稳定版本
| 2.2.0 | 2023年3月7日 |
|---|---|
| 2.1.0 | 2023年2月27日 |
| 2.0.0 | 2022年4月28日 |
| 1.2.2 | 2022年4月20日 |
| 1.2.0 | 2020年6月12日 |
563 在 命令行工具 中排名
每月41次 下载
130KB
2K SLoC
遮蔽胶带,帮助命令“做好一件事”
![]()
![]()
![]()
![]()
遮蔽

- 将 /var/log/secure 中的时间戳转换为 UNIX 时间
$ cat /var/log/secure | teip -c 1-15 -- date -f- +%s
- 在包含 'HELLO' 的行中将 'WORLD' 替换为 'EARTH'
$ cat file | teip -g HELLO -- sed 's/WORLD/EARTH/'
- 编辑 CSV 文件的第二字段
$ cat file.csv | teip --csv -f 2 -- tr a-z A-Z
- 编辑 TSV 文件的第二、第三和第四字段
$ cat file.tsv | teip -D '\t' -f 2-4 -- tr a-z A-Z
- 编辑包含 'hello' 及其前后三行的行
$ cat access.log | teip -e 'grep -n -C 3 hello' -- sed 's/./@/g'
性能提升
teip 允许命令专注于自己的任务。
以下是将约761,000个IP地址替换为虚拟地址在100 MiB文本文件中的处理时间比较。
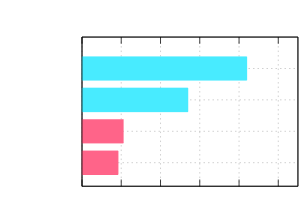
请参阅 Wiki > 基准测试 的详细信息。
功能
-
遮蔽:帮助命令“做好一件事”
- 绕过任何命令的标准输入的部分范围
- 目标命令只处理绕过的标准输入部分
- 灵活的方法选择范围(类似于 AWK、
cut或grep)
-
高性能
- 目标命令的标准输入/输出被多个
teip线程异步拦截。 - 如果您的环境中的通用 UNIX 命令可以在几秒钟内处理几百 MB 的文件,那么
teip可以做到同样的或更好的性能。
- 目标命令的标准输入/输出被多个
安装
Linux (x86_64, ARM64)
dpkg
wget https://github.com/greymd/teip/releases/download/v2.2.0/teip-2.2.0.$(uname -m)-unknown-linux-musl.deb
sudo dpkg -i ./teip*.deb
apt
wget https://github.com/greymd/teip/releases/download/v2.2.0/teip-2.2.0.$(uname -m)-unknown-linux-musl.deb
sudo apt install ./teip*.deb
dnf
sudo dnf install https://github.com/greymd/teip/releases/download/v2.2.0/teip-2.2.0.$(uname -m)-unknown-linux-musl.rpm
yum
sudo yum install https://github.com/greymd/teip/releases/download/v2.2.0/teip-2.2.0.$(uname -m)-unknown-linux-musl.rpm
如果需要,请从 最新发布页面 检查哈希值。以 sha256 结尾的文件列出了哈希值。
macOS (x86_64, ARM64)
使用 Homebrew
brew install greymd/tools/teip
Windows (x86_64)
从 这里 下载安装程序。
请参阅 Wiki > Windows 上的使用 以获取详细信息。
其他架构
请从 最新发布页面 检查您所使用的平台的可执行文件。
如果没有,请从源代码构建。
从源代码构建
使用 Rust 的包管理器 cargo
cargo install teip
要启用 Oniguruma 正则表达式(-G 选项),请使用 --features oniguruma 选项进行构建。请确保在构建前,您的环境中已存在 libclang 共享库。
### Ubuntu
$ sudo apt install cargo clang
$ cargo install teip --features oniguruma
### Red Hat base OS
$ sudo dnf install cargo clang
$ cargo install teip --features oniguruma
### Windows (PowerShell) and choco (chocolatey.org)
PS C:\> choco install llvm
PS C:\> cargo install teip --features oniguruma
使用方法
USAGE:
teip -g <pattern> [-Gosvz] [--] [<command>...]
teip -c <list> [-svz] [--] [<command>...]
teip -l <list> [-svz] [--] [<command>...]
teip -f <list> [-d <delimiter> | -D <pattern> | --csv] [-svz] [--] [<command>...]
teip -e <string> [-svz] [--] [<command>...]
OPTIONS:
-g <pattern> Bypassing lines that match the regular expression <pattern>
-o -g bypasses only matched parts
-G -g interprets Oniguruma regular expressions.
-c <list> Bypassing these characters
-l <list> Bypassing these lines
-f <list> Bypassing these white-space separated fields
-d <delimiter> Use <delimiter> for field delimiter of -f
-D <pattern> Use regular expression <pattern> for field delimiter of -f
--csv -f interprets <list> as field number of a CSV according to
RFC 4180, instead of white-space separated fields
-e <string> Execute <string> on another process that will receive identical
standard input as the teip, and numbers given by the result
are used as line numbers for bypassing
FLAGS:
-h, --help Prints help information
-V, --version Prints version information
-s Execute new command for each bypassed chunk
--chomp Command spawned by -s receives standard input without trailing
newlines
-v Invert the range of bypassing
-z Line delimiter is NUL instead of a newline
ALIASES:
-g <pattern>
-A <number> Alias of -e 'grep -n -A <number> <pattern>'
-B <number> Alias of -e 'grep -n -B <number> <pattern>'
-C <number> Alias of -e 'grep -n -C <number> <pattern>'
--sed <pattern> Alias of -e 'sed -n "<pattern>="'
--awk <pattern> Alias of -e 'awk "<pattern>{print NR}"'
入门指南
首先尝试这个。
$ echo "100 200 300 400" | teip -f 3
结果是几乎与输入相同,但 "300" 被突出显示,并包围在 [...] 中。因为 -f 3 指定了空格分隔输入的第三个字段。
100 200 [300] 400
理解到 [...] 包围的区域是一个遮蔽胶带的 孔。
接下来,将 sed 和其参数放在最后。
$ echo "100 200 300 400" | teip -f 3 sed 's/./@/g'
结果是下面的。突出显示和 [...] 已经消失了。
100 200 @@@ 400
如您所见,sed 只处理了 "孔" 中的输入,并忽略了被遮蔽的部分。技术上,teip 只将突出显示的部分传递给 sed,并用其结果替换。
当然,您可以选择任何命令。本文中称之为 目标命令。
让我们尝试将 cut 作为目标命令,仅提取第一个字符。
$ echo "100 200 300 400" | teip -f 3 cut -c 1
teip: Invalid arguments.
哎呀?为什么失败了?
这是因为 cut 使用了 -c 选项。同名选项也由 teip 提供,这可能会引起混淆。
当使用 teip 输入目标命令时,最好在 -- 后输入。然后,teip 将 -- 后的参数解释为目标命令及其参数。
$ echo "100 200 300 400" | teip -f 3 -- cut -c 1
100 200 3 400
太好了,从 300 中提取了第一个字符 3!
虽然 -- 不是总是必要的,但总是更好的选择。所以,从现在开始的所有示例中都将使用 --
现在让我们使用 awk 将这个数字翻倍。命令看起来如下(注意要翻倍的变量不是 $3)。
$ echo "100 200 300 400" | teip -f 3 -- awk '{print $1*2}'
100 200 600 400
好的,结果从 300 变成了 600。
现在,让我们将 -f 3 更改为 -f 3,4 并运行它。
$ echo "100 200 300 400" | teip -f 3,4 -- awk '{print $1*2}'
100 200 600 800
第 3 和第 4 个数字都被翻倍了!
正如一些人可能已经注意到的,-f 的参数与 cut 的 列表 兼容。
让我们看看它与 cut --help 一起是如何工作的。
$ echo "100 200 300 400" | teip -f -3 -- sed 's/./@/g'
@@@ @@@ @@@ 400
$ echo "100 200 300 400" | teip -f 2-4 -- sed 's/./@/g'
100 @@@ @@@ @@@
$ echo "100 200 300 400" | teip -f 1- -- sed 's/./@/g'
@@@ @@@ @@@ @@@
按字符选择范围
- 选项允许您通过字符基础指定范围。以下示例指定了第 1、3、5、7 个字符,并将 sed 命令应用于它们。
$ echo ABCDEFG | teip -c 1,3,5,7
[A]B[C]D[E]F[G]
$ echo ABCDEFG | teip -c 1,3,5,7 -- sed 's/./@/'
@B@D@F@
与 -f 相同,-c 的参数与 cut 的 列表 兼容。
处理定界文本,如 CSV、TSV
默认情况下,-f 选项识别与 awk 类似的定界字段。
连续的空白字符(由 Unicode 分类为各种空白形式)被解释为单个定界符。
$ printf "A B \t\t\t\ C \t D" | teip -f 3 -- sed s/./@@@@/
A B @@@@ C D
这种行为可能不方便处理 CSV 和 TSV。
但是,可以与 -f 一起使用 -d 选项来指定定界符。现在您可以像这样处理 CSV 文件。
$ echo "100,200,300,400" | teip -f 3 -d , -- sed 's/./@/g'
100,200,@@@,400
为了处理 TSV,需要输入制表符。如果您使用 Bash,请输入 $'\t',这是 ANSI-C 引用 之一。
$ printf "100\t200\t300\t400\n" | teip -f 3 -d $'\t' -- sed 's/./@/g'
100 200 @@@ 400
teip 还提供了 -D 选项,可以指定扩展正则表达式作为定界符。当您想忽略连续的定界符或存在多种类型的定界符时,这很有用。
$ echo 'A,,,,,B,,,,C' | teip -f 2 -D ',+'
A,,,,,[B],,,,C
$ echo "1970-01-02 03:04:05" | teip -f 2-5 -D '[-: ]'
1970-[01]-[02] [03]:[04]:05
也可以使用 -D 选项指定制表符(\t)的正则表达式。
$ printf "100\t200\t300\t400\n" | teip -f 3 -D '\t' -- sed 's/./@/g'
100 200 @@@ 400
有关正则表达式的可用表示法,请参阅 Rust 的正则表达式。
复杂的 CSV 处理
如果您想处理复杂的 CSV 文件,例如下面这样的文件,其中列被双引号包围,请同时使用 -f 和 --csv 选项。
Name,Address,zipcode
Sola Harewatar,"Doreami Road 123
Sorashido city",12877
Yui Nagomi,"Nagomi Street 456, Nagomitei, Oishina town",26930-0312
"Conectol Motimotit Hooklala Glycogen Comex II a.k.a ""Kome kome""","Cooking dam",513123
使用 --csv,teip 将输入解析为根据 RFC4180 的 CSV 文件。因此,您可以使用 -f 为结构复杂的 CSV 文件指定列号。
例如,前面提到的 CSV 将如下所示有“空隙”。
$ cat tests/sample.csv | teip --csv -f2
Name,[Address],zipcode
Sola Harewatar,["Doreami Road 123]
[Sorashido city"],12877
Yui Nagomi,["Nagomi Street 456, Nagomitei, Oishina town"],26930-0312
"Conectol Motimotit Hooklala Glycogen Comex II a.k.a ""Kome kome""",["Cooking dam"],513123
因为指定了 -f2,所以每行的第二列都有一个空隙。以下命令是重写第二列所有字符为 "@ " 的示例。
$ cat tests/sample.csv | teip --csv -f2 -- sed 's/[^"]/@/g'
Name,@@@@@@@,zipcode
Sola Harewatar,"@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@",12877
Yui Nagomi,"@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@",26930-0312
"Conectol Motimotit Hooklala Glycogen Comex II a.k.a ""Kome kome""","@@@@@@@@@@@",513123
--csv 选项说明
- 字段周围的双引号(
")也包含在空隙中。 - 转义的双引号(
"")按原样处理;两个双引号("")被作为输入传递给目标命令。 - 包含换行符的字段将具有多个空隙,由换行符分隔,而不是单个空隙。
- 但是,如果使用了
-s或-z选项,它将被视为单个空隙,包括行中断。
- 但是,如果使用了
与正则表达式匹配
您还可以使用 -g 选择匹配正则表达式的特定行作为空隙位置。
$ echo -e "ABC1\nEFG2\nHIJ3" | teip -g '[GJ]\d'
ABC1
[EFG2]
[HIJ3]
默认情况下,包含模式的整个行是空隙的范围。使用 -o 选项,空隙范围将仅限于匹配范围。
$ echo -e "ABC1\nEFG2\nHIJ3" | teip -og '[GJ]\d'
ABC1
EF[G2]
HI[J3]
请注意,-og 是一个有用的惯用表达式,在本文档中经常使用。
以下是一个使用 \d 匹配数字的例子。
$ echo ABC100EFG200 | teip -og '\d+'
ABC[100]EFG[200]
$ echo ABC100EFG200 | teip -og '\d+' -- sed 's/.*/@@@/g'
ABC@@@EFG@@@
这个功能非常灵活,可以用于处理没有固定格式的文件,例如日志、Markdown 等。
哪些命令是合适的?
teip 逐行绕过整个字符串,因此每个孔是一行输入。因此,目标命令必须遵循以下规则。
- 目标命令必须为每一行输入打印一行结果。
在最简单的例子中,cat 命令总是成功。因为 cat 打印与输入相同的行数。
$ echo ABCDEF | teip -og . -- cat
ABCDEF
如果上述规则不满足,结果将不一致。例如,grep 可能会失败。以下是一个例子。
$ echo ABCDEF | teip -og .
[A][B][C][D][E][F]
$ echo ABCDEF | teip -og . -- grep '[ABC]'
ABC
teip: Output of given command is exhausted
$ echo $?
1
teip 无法获取与 D、E 和 F 孔相对应的结果。这就是为什么上述示例失败的原因。
如果发生不一致,teip 将以错误消息退出。此外,退出状态将为 1。
要了解有关 teip 行为的更多信息,请参阅 Wiki > Chunking。
高级用法
固态模式(-s)
如果您想使用不满足条件(“目标命令必须为每一行输入打印一行结果”)的命令,请启用“固态模式”,该模式可以通过 -s 选项使用。
固态模式为每个孔启动目标命令并执行它。
$ echo ABCDEF | teip -s -og . -- grep '[ABC]'
在上面的例子中,了解以下命令是在 teip 的内部过程执行的。
$ echo A | grep '[ABC]' # => A
$ echo B | grep '[ABC]' # => B
$ echo C | grep '[ABC]' # => C
$ echo D | grep '[ABC]' # => Empty
$ echo E | grep '[ABC]' # => Empty
$ echo F | grep '[ABC]' # => Empty
空结果被替换为空字符串。因此,D、E 和 F 如预期的那样被替换为空。
$ echo ABCDEF | teip -s -og . -- grep '[ABC]'
ABC
$ echo $?
0
然而,由于其高处理开销,这个选项不适合处理大文件,这可能会显着降低性能。
带有 --chomp 的固态模式
如果 -s 选项没有按预期工作,--chomp 可能会有所帮助。
固态模式下的目标命令始终接受带有行字段(\x0A)的输入。这是因为 teip 假设使用命令,这些命令对单行输入返回单行结果。因此,即使孔中没有换行符,也会添加换行符,将其视为单行输入。
但是,有时这种行为不方便。例如,当使用其行为取决于行字段存在与否的命令时。
$ echo AAABBBCCC | teip -og BBB -s
AAA[BBB]CCC
$ echo AAABBBCCC | teip -og BBB -s -- tr '\n' '@'
AAABBB@CCC
以上是一个目标命令是“将行字段(\x0A)转换为 @”的“tr”命令的例子。“BBB”不包含换行符,但结果为“BBB@”,因为隐式添加的换行符已被处理。为了防止这种行为,请使用 --chomp 选项。此选项为目标命令提供不带换行符的纯输入。
$ echo AAABBBCCC | teip -og BBB -s --chomp -- tr '\n' '@'
AAABBBCCC
例如,当使用像 tr 这样的命令,将其解释和处理为二进制时,这很有用。以下是从包含换行符的 CSV 的第二列中删除换行符的例子。
$ cat tests/sample.csv
Name,Address,zipcode
Sola Harewatar,"Doreami Road 123
Sorashido city",12877
结果是。
$ cat tests/sample.csv | teip --csv -f 2 -s --chomp -- tr '\n' '@'
Name,Address,zipcode
Sola Harewatar,"Doreami Road 123@Sorashido city",12877
行号(-l)
您可以指定行号,并且仅在该行钻洞。
$ echo -e "ABC\nDEF\nGHI" | teip -l 2
ABC
[DEF]
GHI
$ echo -e "ABC\nDEF\nGHI" | teip -l 1,3
[ABC]
DEF
[GHI]
重叠 teip
任何命令都可以与 teip 一起使用,令人惊讶的是,甚至是 teip 本身。
$ echo "AAA@@@@@AAA@@@@@AAA" | teip -og '@.*@'
AAA[@@@@@AAA@@@@@]AAA
$ echo "AAA@@@@@AAA@@@@@AAA" | teip -og '@.*@' -- teip -og 'A+'
AAA@@@@@[AAA]@@@@@AAA
$ echo "AAA@@@@@AAA@@@@@AAA" | teip -og '@.*@' -- teip -og 'A+' -- tr A _
AAA@@@@@___@@@@@AAA
换句话说,通过将多个teip功能与AND条件连接,可以在更复杂的范围内打孔。此外,它以异步和多进程方式工作,类似于shell管道。除非机器面临并行性的极限,否则几乎不会降低性能。
Oniguruma正则表达式(-G)
如果同时给出了-G和-g选项,则正则表达式被解释为Oniguruma正则表达式。例如,可以使用“保留”和“前瞻”语法。
$ echo 'ABC123DEF456' | teip -G -og 'DEF\K\d+'
ABC123DEF[456]
$ echo 'ABC123DEF456' | teip -G -og '\d+(?=D)'
ABC[123]DEF456
空孔
当使用-f选项时,如果存在空白字段,则空白不会忽略并被视为一个空孔。
$ echo ',,,' | teip -d , -f 1-
[],[],[],[]
因此,以下命令可以正常工作(注意,*也匹配空值)。
$ echo ',,,' | teip -f 1- -d, sed 's/.*/@@@/'
@@@,@@@,@@@,@@@
在上面的例子中,sed加载四个换行符并打印四次@@@。
反转匹配(-)
-选项允许您反转孔的范围。当与-或-选项一起使用时,将在指定字段的补集中制作孔。
$ echo 1 2 3 4 5 | teip -v -f 1,3,5 -- sed 's/./_/'
1 _ 3 _ 5
当然,它也可以用于-选项。
$ printf 'AAA\n123\nBBB\n' | teip -vg '\d+' -- sed 's/./@/g'
@@@
123
@@@
零终止模式(-)
如果您想以更灵活的方式处理数据,则-选项可能很有用。此选项允许您使用NUL字符(ASCII NUL字符)而不是换行符。它类似于GNU sed或GNU grep提供的-或xargs提供的0选项。
$ printf '111,\n222,33\n3\0\n444,55\n5,666\n' | teip -z -f3 -d,
111,
222,[33
3]
444,55
5,[666]
使用此选项,标准输入根据NUL字符而不是换行符进行解释。您还应注意,在teip的过程中,孔中的字符串是用NUL字符而不是换行符连接的。
换句话说,如果您使用了一个不能处理NUL字符(且不能打印以NUL分隔的结果)的特定命令,则最终结果可能不是预期的。
$ printf '111,\n222,33\n3\0\n444,55\n5,666\n' | teip -z -f3 -d, -- sed -z 's/.*/@@@/g'
111,
222,@@@
444,55
5,@@@
$ printf '111,\n222,33\n3\0\n444,55\n5,666\n' | teip -z -f3 -d, -- sed 's/.*/@@@/g'
111,
222,@@@
@@@
444,55
5,teip: Output of given command is exhausted
指定从一行到另一行是该选项的典型用法。
$ cat test.html | teip -z -og '<body>.*</body>'
<html>
<head>
<title>AAA</title>
</head>
[<body>
<div>AAA</div>
<div>BBB</div>
<div>CCC</div>
</body>]
</html>
$ cat test.html | teip -z -og '<body>.*</body>' -- grep -a BBB
<html>
<head>
<title>AAA</title>
</head>
<div>BBB</div>
</html>
匹配卸载的外部执行(-)
-是用于模式匹配的外部命令的选项。直到上述内容,您必须使用teip自己的功能,如-或-,来控制掩码带上的孔的位置。然而,使用-,您可以使用您熟悉的命令来指定孔的范围。
-允许您将shell管道作为字符串指定。在UNIX-like操作系统上,此管道在/bin/sh中执行,在Windows上在cmd.exe中执行。
例如,对于一个输出 3 的管道 echo 3,则只有第三行会被跳过。
$ echo -e 'AAA\nBBB\nCCC' | teip -e 'echo 3'
AAA
BBB
[CCC]
即使输出有些“杂乱”,它也能正常工作。例如,如果一行开头包含空格或制表符字符,它们会被忽略。此外,一旦给出了一个数字,无论其右边是否有非数字字符,都不会影响。
$ echo -e 'AAA\nBBB\nCCC' | teip -e 'echo " 3"'
AAA
BBB
[CCC]
$ echo -e 'AAA\nBBB\nCCC' | teip -e 'echo " 3:testtest"'
AAA
BBB
[CCC]
在技术上,正则表达式 ^\s*([0-9]+) 的第一个捕获组被解释为行号。
如果管道提供了多行数字,-e 也会识别多个数字。例如,使用 seq 命令显示从 1 到 10 的奇数。
$ seq 1 2 10
1
3
5
7
9
这意味着可以通过指定以下内容来仅跳过奇数行。
$ echo -e 'AAA\nBBB\nCCC\nDDD\nEEE\nFFF' | teip -e 'seq 1 2 10' -- sed 's/. /@/g'
@@@
BBB
@@@
DDD
@@@
FFF
请注意,数字的顺序必须是升序的。现在,这看起来像是一个对 -l 选项的微小扩展。
然而,这个特性的突破在于 管道获得与 teip 相同的标准输入。因此,不仅可以使用 seq 和 echo 输出任何数字,还可以使用处理标准输入的命令,如 grep、sed 和 awk。
让我们看看一个更具体的例子。以下是一个 grep 命令,它打印包含字符串 "CCC" 的行号及其后的两行。
$ echo -e 'AAA\nBBB\nCCC\nDDD\nEEE\nFFF' | grep -n -A 2 CCC
3:CCC
4-DDD
5-EEE
如果你将此命令给 -e,你可以在包含字符串 "CCC" 的行及其后的两行中打孔!
$ echo -e 'AAA\nBBB\nCCC\nDDD\nEEE\nFFF' | teip -e 'grep -n -A 2 CCC'
AAA
BBB
[CCC]
[DDD]
[EEE]
FFF
grep 并非唯一。GNU sed 有 =,它会打印正在处理的行号。以下是从包含 "BBB" 的行钻到包含 "EEE" 的行的示例。
$ echo -e 'AAA\nBBB\nCCC\nDDD\nEEE\nFFF' | teip -e 'sed -n "/BBB/,/EEE/="'
AAA
[BBB]
[CCC]
[DDD]
[EEE]
FFF
当然,类似的操作也可以用 awk 完成。
$ echo -e 'AAA\nBBB\nCCC\nDDD\nEEE\nFFF' | teip -e 'awk "/BBB/,/EEE/{print NR}"'
以下是将 nl 和 tail 命令结合的示例。你只能对输入的最后三行打孔!
$ echo -e 'AAA\nBBB\nCCC\nDDD\nEEE\nFFF' | teip -e 'nl -ba | tail -n 3'
AAA
BBB
CCC
[DDD]
[EEE]
[FFF]
- 参数是单个字符串。因此,管道 | 和其他符号可以按原样使用。
别名选项(-A、-B、-C、--awk、--sed)
有几个 实验性选项 是 - 和特定字符串的别名。这些选项可能在未来被取消,因为它们只是实验性的。不要在脚本或一次性之外使用它们。
-A<数字>
这是一个别名为 -e 'grep -n -A <number> <pattern>' 的命令。如果与 -g <pattern> 选项一起使用,它会在与 <pattern> 和 <number> 行匹配的行之后留下空隙。
$ cat AtoG.txt | teip -g B -A 2
A
[B]
[C]
[D]
E
F
G
-B<数字>
这是一个别名为 -'grep -n -B <number> <pattern>' 的命令。如果与 -<pattern> 选项一起使用,它会在与 <pattern> 和 <number> 行匹配的行之前留下空隙。
$ cat AtoG.txt | teip -g E -B 2
A
B
[C]
[D]
[E]
F
G
-C<数字>
这是一个别名为 -'grep -n -<number> <pattern>' 的命令。如果与 -<pattern> 选项一起使用,它会在与 <pattern> 和 <number> 行匹配的行之前和之后留下空隙。
$ cat AtoG.txt | teip -g E -C 2
A
B
[C]
[D]
[E]
[F]
[G]
--sed<pattern>
这是一个别名为 -'sed -"<pattern>=" 的命令。
$ cat AtoG.txt | teip --sed '/B/,/E/'
A
[B]
[C]
[D]
[E]
F
G
$ cat AtoG.txt | teip --sed '1~3'
[A]
B
C
[D]
E
F
[G]
--awk<pattern>
这是一个别名为 -'awk "<pattern>{print NR}" 的命令。
$ cat AtoG.txt | teip --awk '/B/,/E/'
A
[B]
[C]
[D]
[E]
F
G
$ cat AtoG.txt | teip --awk 'NR%3==0'
A
B
[C]
D
E
[F]
G
环境变量
teip 指的是以下环境变量。将以下语句添加到默认shell的启动文件(例如 .bashrc,.zshrc)中,以按您的喜好进行更改。
TEIP_HIGHLIGHT
默认值: \x1b[36m[\x1b[0m\x1b[01;31m{}\x1b[0m\x1b[36m]\x1b[0m
突出显示空隙的默认格式。它必须至少包含一个 {} 作为占位符。
示例
$ export TEIP_HIGHLIGHT="<<<{}>>>"
$ echo ABAB | teip -og A
<<<A>>>B<<<A>>>B
$ export TEIP_HIGHLIGHT=$'\x1b[01;31m{}\x1b[0m'
$ echo ABAB | teip -og A
ABAB ### Same color as grep
ANSI转义序列 和 ANSI-C 引用 可用于自定义此值。
TEIP_GREP_PATH
默认值: grep
grep 命令的路径,用于 -A、-、- 选项。例如,如果您想使用 ggrep 而不是 grep,则将此变量设置为 ggrep。
$ export TEIP_GREP_PATH=/opt/homebrew/bin/ggrep
$ echo -e 'AAA\nBBB\nCCC\nDDD\nEEE\nFFF' | teip -g CCC -A 2
AAA
BBB
[CCC]
[DDD]
[EEE]
FFF
TEIP_SED_PATH
默认值: sed
sed 命令的路径,用于 --sed 选项。例如,如果您想使用 gsed 而不是 sed,则将此变量设置为 gsed。
TEIP_AWK_PATH
默认值: awk
awk 命令的路径,用于 --awk 选项。例如,如果您想使用 gawk 而不是 awk,则将此变量设置为 gawk。
背景
为什么制作它?
参见这篇帖子。
为什么叫“teip”?
- tee + in-place。
- 听起来和“Masking-”tape”相似。
许可
从其他存储库导入/引用的模块
非常感谢这些有用的模块!
-
./src/list/ranges.rs
cut命令中使用的模块之一,来自 uutils/coreutils- 原始源代码在 MIT 许可下分发
- 许可文件位于同一目录下
-
./src/csv/parser.rs
- 源代码的许多部分参考自 BurntSushi/rust-csv。
- 原始源代码在 MIT 和 Unlicense 双许可下分发
源代码
脚本在 MIT 许可 的条款下作为开源代码提供。
标志
![]()
teip 的标志在 Creative Commons Attribution-NonCommercial 4.0 International License 许可下。
依赖项
~4–13MB
~150K SLoC