18个稳定版本 (3个主要版本)
| 4.4.1 | 2024年4月23日 |
|---|---|
| 4.3.1 | 2024年3月1日 |
| 4.0.0 | 2023年12月26日 |
| 3.1.2 | 2023年11月30日 |
| 1.0.0 | 2023年7月21日 |
#24 in 内存管理
4,222 每月下载量
在 10 个crates中使用 (直接使用3个)
255KB
1.5K SLoC
Talc分配器 


如果你觉得Talc很有用,请考虑通过 Paypal 捐赠
这是用来做什么的?
- 嵌入式系统、操作系统内核和其他
no_std环境 - WebAssembly应用程序,作为默认分配器的直接替代品
- 需要特别快速区域分配的正常程序子系统
为什么选择Talc?
- 性能是主要关注点,同时保持通用性
- 支持即时堆管理和恢复的自定义内存不足处理器
- 支持创建和调整任意数量的堆
- 可选的分配统计信息
- 启用调试断言时的部分验证
- 符合MIRI的堆栈借用检查器
为什么不选择Talc?
- 目前尚无法直接与操作系统的动态内存功能集成
- 在分配/释放密集的并发处理中扩展性不好
- 尽管它在并发重新分配方面特别出色。
目录
针对WebAssembly?您可以在这里找到WASM特定用法和基准测试。
设置
作为全局分配器
use talc::*;
static mut ARENA: [u8; 10000] = [0; 10000];
#[global_allocator]
static ALLOCATOR: Talck<spin::Mutex<()>, ClaimOnOom> = Talc::new(unsafe {
// if we're in a hosted environment, the Rust runtime may allocate before
// main() is called, so we need to initialize the arena automatically
ClaimOnOom::new(Span::from_const_array(core::ptr::addr_of!(ARENA)))
}).lock();
fn main() {
let mut vec = Vec::with_capacity(100);
vec.extend(0..300usize);
}
或者使用Allocator API通过spin作为区域分配器,如下所示
#![feature(allocator_api)]
use talc::*;
use core::alloc::{Allocator, Layout};
static mut ARENA: [u8; 10000] = [0; 10000];
fn main () {
let talck = Talc::new(ErrOnOom).lock::<spin::Mutex<()>>();
unsafe { talck.lock().claim(ARENA.as_mut().into()); }
talck.allocate(Layout::new::<[u32; 16]>());
}
请注意,虽然这里使用了 spin crate 的互斥锁,但任何实现 lock_api 的锁都可以工作。
基准测试
堆效率基准测试结果
随机分配/释放/重新分配时的第一次分配失败时的平均占用容量。
| 分配器 | 平均随机动作堆效率 |
|---|---|
| Dlmalloc | 99.14% |
| Rlsf | 99.06% |
| Talc | 98.97% |
| 链表 | 98.36% |
| 伙伴分配 | 63.14% |
随机动作基准测试
在指定时间内成功的分配、释放和重新分配的数量。
1 线程
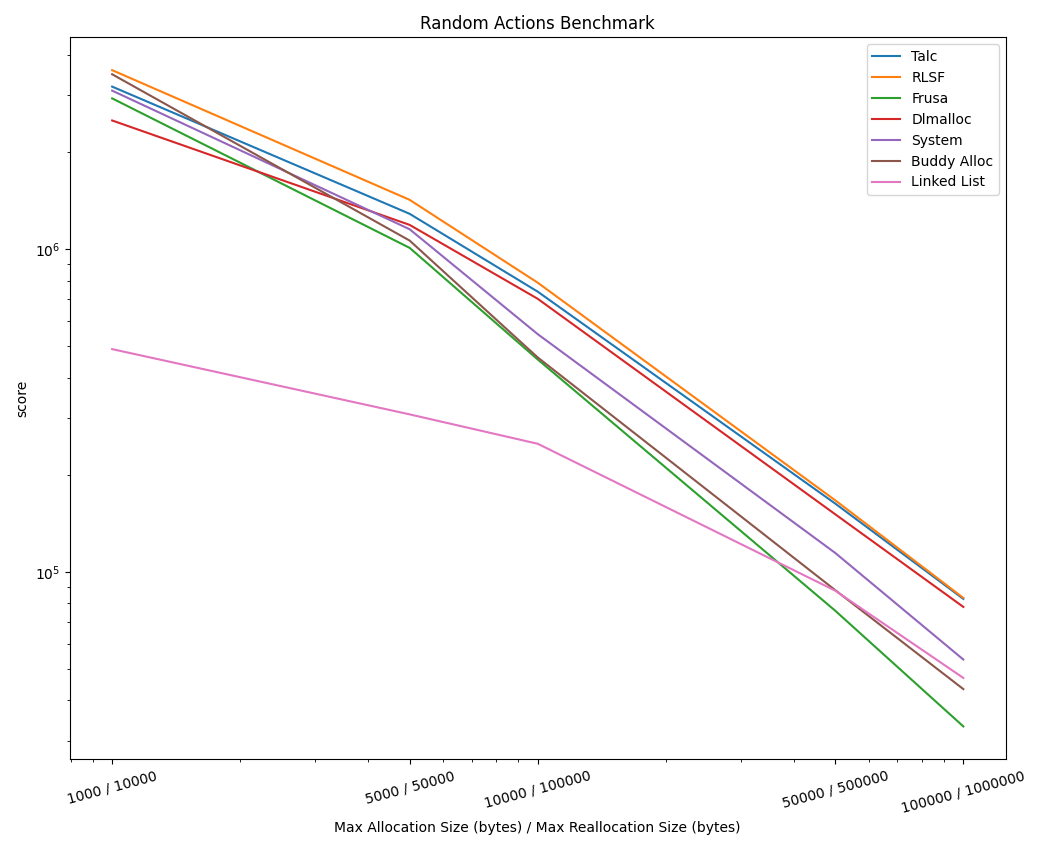
4 线程
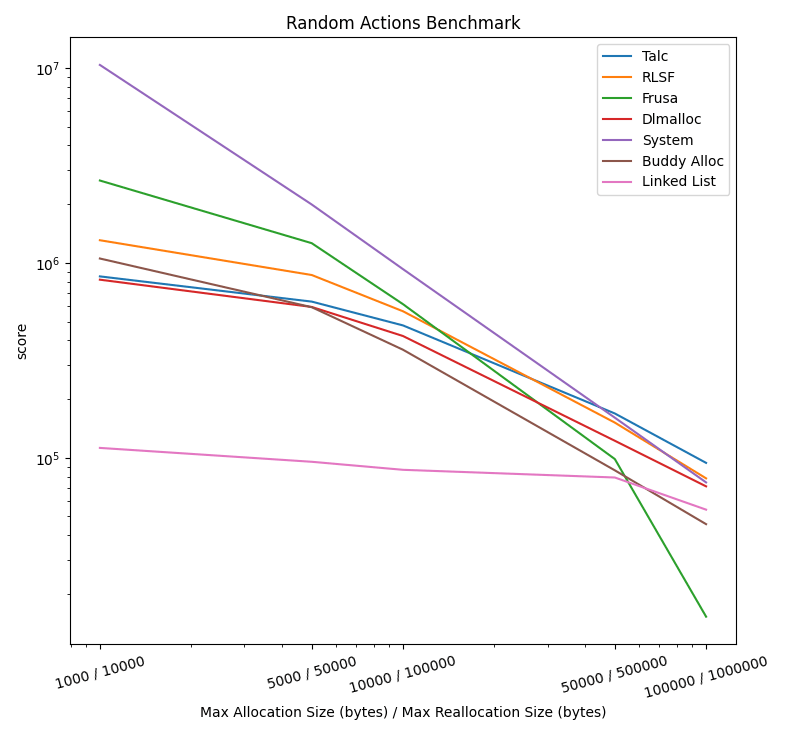
分配与释放微基准测试
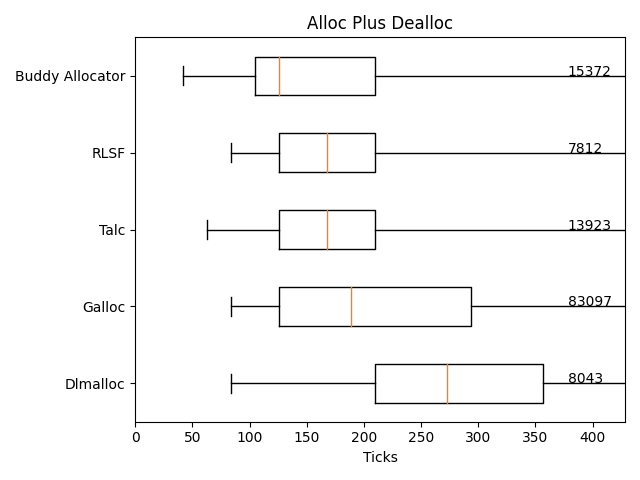
标签表示距离中位数 50 个标准差范围内的最大值。最大分配大小为 0x10000。
通用用法
以下是重要的 Talc 方法列表
- 构造函数
new
- 信息
get_allocated_span- 返回包含已建立堆中所有分配内存的最小堆跨度get_counters- 如果启用了功能"counters",则返回一个包含分配统计信息的结构体
- 管理
claim- 为建立新堆声明内存extend- 扩展已建立的堆truncate- 减少已建立堆的扩展范围lock- 将Talc包装在Talck中,该包装支持GlobalAlloc和AllocatorAPI
- 分配
mallocfreegrowgrow_in_placeshrink
阅读他们的文档以获取更多信息。
Span 是一个描述内存区域的便捷小型类型,因为它尝试操作 Range<*mut u8> 或 *mut [u8] 或 base_ptr-size 对通常不方便或令人烦恼。
高级用法
分配器的最强大功能是它具有模块化的 OOM 处理系统,允许您轻松地从分配失败中退出或恢复。
提供的 OomHandler 实现包括
ErrOnOom:在 OOM 时分配失败ClaimOnOom:在第一次 OOM 时声明堆,对于初始化很有用WasmHandler:与 WebAssembly 的memory模块集成以自动管理内存堆
以下是一个自定义实现的示例,通过扩展堆进行恢复。
use talc::*;
struct MyOomHandler {
heap: Span,
}
impl OomHandler for MyOomHandler {
fn handle_oom(talc: &mut Talc<Self>, layout: core::alloc::Layout) -> Result<(), ()> {
// Talc doesn't have enough memory, and we just got called!
// We'll go through an example of how to handle this situation.
// We can inspect `layout` to estimate how much we should free up for this allocation
// or we can extend by any amount (increasing powers of two has good time complexity).
// (Creating another heap with `claim` will also work.)
// This function will be repeatedly called until we free up enough memory or
// we return Err(()) causing allocation failure. Be careful to avoid conditions where
// the heap isn't sufficiently extended indefinitely, causing an infinite loop.
// an arbitrary address limit for the sake of example
const HEAP_TOP_LIMIT: *mut u8 = 0x80000000 as *mut u8;
let old_heap: Span = talc.oom_handler.heap;
// we're going to extend the heap upward, doubling its size
// but we'll be sure not to extend past the limit
let new_heap: Span = old_heap.extend(0, old_heap.size()).below(HEAP_TOP_LIMIT);
if new_heap == old_heap {
// we won't be extending the heap, so we should return Err
return Err(());
}
unsafe {
// we're assuming the new memory up to HEAP_TOP_LIMIT is unused and allocatable
talc.oom_handler.heap = talc.extend(old_heap, new_heap);
}
Ok(())
}
}
条件特性
"lock_api"(默认):提供实现了GlobalAlloc的Talck锁定包装类型。"allocator"(默认,需要 nightly):通过Talck提供Allocatortrait 实现。"nightly_api"(默认,需要夜间版本):提供Span::from(*mut [T])和Span::from_slice函数。"counters":Talc 将跟踪堆和分配指标。使用Talc::get_counters来访问它们。"allocator-api2":如果"allocator"未激活,则 Talck 将实现allocator_api2::alloc::Allocator。
稳定Rust和MSRV
Talc 可以在稳定的 Rust 上构建,通过禁用 "allocator" 和 "nightly_api"。最低稳定 Rust 版本是 1.67.1。
禁用 "nightly_api" 将禁用 Span::from(*mut [T])、Span::from(*const [T])、Span::from_const_slice 和 Span::from_slice。
算法
这是一个带有边界标记和分桶的 dlmalloc 风格的链表分配器,旨在用于通用场景。分配的最坏情况是 O(n)(但在实践中接近常数时间,请参见微基准测试),而就地realloc和释放是 O(1)。
此外,重新排列了块元数据的布局,以允许更小的最小块大小,从而减少小型分配的内存开销。最小块大小为 3 * usize,每个分配保留一个 usize。这比 dlmalloc 和 galloc 更高效,尽管使用了类似的算法。
未来开发
- 支持更好的并发性,因为这是分配器的主要缺陷。
- 将默认功能更改为默认为稳定。
- 添加对更多系统的即插即用支持。
- 允许与后端分配器集成并(延迟)释放未使用内存(例如,与 mmap/分页的更好集成)。
变更日志
v4.4.1
- 向
Span添加了实用函数except,该函数执行集合差集,可能会拆分Span。感谢 bjorn3 提出建议!
v4.4.0
- 添加了功能
allocator-api2,允许通过allocator-api2crate 在稳定版本中使用Allocatortrait。感谢 jess-sol!
v4.3.1
- 稍微更新了 README。
v4.3.0
-
为计数器添加了
Display实现的代码。希望这会使您的日志更美观。- 如果您对当前布局有意见,请提出,我很乐意做出更改。
-
将Frusa和RLSF添加到基准测试中。
- RLSF在各方面表现良好,Frusa在特定工作负载方面表现尤为出色。
-
将随机操作基准测试改为测量各种分配大小。
v4.2.0
-
优化了就地重新分配,允许在就地重新分配失败时执行其他分配操作。
- 作为副作用,Talc现在有一个返回
Err的grow_in_place函数,如果就地扩展内存不可行。 - 已将受益于这种工作负载的随机操作基准测试的图表包含在基准测试部分。
- 作为副作用,Talc现在有一个返回
-
添加了用于常量指针和共享引用的
Span::from_*和From<>函数。- 这使得在稳定版上静态上下文中创建span变得更加容易:
Span::from_const_array(addr_of!(MEMORY))
- 这使得在稳定版上静态上下文中创建span变得更加容易:
-
修复:再次使
Talck派生自Debug。 -
由Ken Hoover贡献:添加Talc竞技场式分配大小和性能WASM基准测试
- 如果您有已知的动态内存需求,并希望进一步减小WASM大小,这可能是一个不错的选择。
-
wasm-size现在使用wasm-opt,为wasm-pack用户提供了更真实的大小差异 -
改进了shell脚本
-
彻底更新了微基准测试
- 不再模拟高堆栈压力,因为容忍分配失败的情况很少
- 现在使用箱线图显示数据
v4.1.1
- 修复:将MSRV重置为1.67.1,并在
test.sh中添加了对它的检查
v4.1.0(已撤回,使用4.1.1)
- 添加了对分配指标的跟踪(可选)。感谢Ken Hoover的建议!
- 启用
"counters"功能。通过talc.get_counters()访问数据 - 指标包括分配计数、可用字节数、碎片、开销等。
- 启用
- 改进了文档
- 改进并更新了基准测试
- 将WASM性能基准测试集成到项目中。使用
wasm-bench.sh运行(需要wasm-pack和deno) - 改进了
wasm-size和wasm-size.sh
v4.0.0
- 将
Talck的API更改得更符合Rust规范。Talck现在隐藏了其内部结构(不再有.0)。Talck::talc()已被替换为Talck::lock()。Talck::new()和Talck::into_inner(self)已被添加。- 删除了
TalckRef并在Talck上直接实现了Allocator特性。不再需要调用talck.allocator()。
- 更改了提供的锁定机制的 API
- 将
AssumeUnlockable移动到talc::locking::AssumeUnlockable - 删除了
Talc::lock_assume_single_threaded,如果需要,使用.lock::<talc::locking::AssumeUnlockable>()。
- 将
- 对文档进行了多处改进。感谢 polarathene 的贡献!
v3.1.2
- 对文档进行了一些改进。
v3.1.1
- 将 WASM OOM 处理器的行为更改得更健壮,如果其他代码在分配器使用期间调用
memory.grow,则更健壮。
v3.1.0
- 减少了对夜间仅有的功能的依赖,并将剩余的功能(
Span::from(*mut [T])和Span::from_slice)置于nightly_api之下。 nightly_api功能默认启用- 警告:如果使用
default-features = false,则可能在使用受控函数时出现意外错误。考虑添加nightly_api或使用另一个函数。
- 警告:如果使用
v3.0.1
- 改进了文档
- 改进并更新了基准测试
- 增加了随机动作的分配大小范围。(对不起 Buddy Allocator!)
- Heap Efficiency 基准测试的迭代次数增加,以产生更准确和稳定的数据。
v3.0.0
- 添加了对多个不连续堆的支持!这需要一些主要的 API 变更
new_arena已不再存在(使用new然后使用claim)init已被替换为claimclaim、extend和truncate现在返回新的堆范围InitOnOom现在是ClaimOnOom。- 以上所有内容现在都有不同的行为和文档。
- 每个堆现在在底部都有固定的开销一个
usize。
要从 v2 迁移到 v3,请注意,如果您想调整它们的大小,您必须跟踪堆,通过存储返回的 Span。阅读 claim、extend 和 truncate 的文档以获取所有详细信息。
v2.2.1
- 重新编写了分配器的内部结构,将分配元数据放置在分配之上。
- 这将最大限度地减少假共享,在之前,一个分配的分配元数据会侵犯它之前分配的缓存行,即使需要足够高的对齐。单线程性能也略有提高。
- 删除了heap_exhaustion并替换为heap_efficiency基准测试。
- 改进了文档和其他资源。
- 将WASM大小测量更改为包含略少的开销。
v2.2.0
- 将
dlmalloc添加到基准测试中。 - 现在WASM应该通过
TalckWasm完全支持。告诉我什么出问题了 ;)- 更多详细信息请点击这里。
v2.1.0
- 现在在32位目标上测试通过了。
- 对各种项目进行了文档修复和改进。
- 修复了在不使用
allocator的情况下使用lock_api的问题。 - 通过
TalckWasm在WASM目标上添加了实验性的WASM支持。
v2.0.0
- 删除了对
spin的依赖,并改为使用lock_api(感谢Stefan Lankes)- 您可以使用
talc.lock::<spin::Mutex<()>>()来指定您想要使用的锁。
- 您可以使用
- 删除了
Talc结构体不能移动的要求,并删除了mov函数。- 现在使用竞技场来存储元数据,因此极小的竞技场会导致分配失败。
- 使OOM处理系统使用泛型和特质而不是函数指针。
- 使用
ErrOnOom执行它所说的内容。InitOnOom与此类似,但如果完全未初始化,则初始化为给定的范围。在任何结构体上实现OomHandler以实现自己的行为(可以通过handle_oom通过talc.oom_handler访问OOM处理程序状态)。
- 使用
- 更改了
Span的API和内部结构以及其他更改,以通过miri的Stacked Borrows检查。- 现在Span仅使用指针并携带来源。
- 以多种方式更新了基准测试,特别是添加了
buddy_alloc并删除了simple_chunk_allocator。