21 个版本 (12 个重大更新)
| 新 0.13.1 | 2024 年 8 月 18 日 |
|---|---|
| 0.12.0 | 2024 年 3 月 25 日 |
| 0.10.0 | 2023 年 12 月 18 日 |
| 0.7.0 | 2023 年 11 月 6 日 |
#106 在 开发工具
每月 246 次下载
2.5MB
55K SLoC
SRGN - 一款代码外科医生
一个类似 grep 的工具,能理解源代码语法,除了搜索外还允许操作。
与 grep 类似,正则表达式是其核心原语。与 grep 不同,额外的功能允许实现更精确的操作,包括操作选项。这使得 SRGN 能够在正则表达式和 IDE 工具(如重命名所有、查找所有引用等)无法工作的维度上操作,从而补充它们。
SRGN 围绕要执行的操作(如果有)组织,仅在实际、可选的语言语法感知的范围内操作。从现有工具的角度来看,可以将其视为 tr、sed、ripgrep 和 tree-sitter 的混合体,设计目标是 简单:如果你了解正则表达式和你正在使用的语言的基础知识,你就可以开始使用了。
快速入门
[!TIP]
这里显示的所有代码片段都已作为单元测试的一部分通过实际的
srgn二进制文件进行验证。这里展示的内容都是保证可以工作的。
最简单的形式类似于 tr
$ echo 'Hello World!' | srgn '[wW]orld' 'there'
Hello there!
对于正则表达式模式 '[wW]orld'(作用域)的匹配进行替换(操作)由第二个位置参数指定。可以指定零个或多个操作
$ echo 'Hello World!' | srgn '[wW]orld' # zero actions: input returned unchanged
Hello World!
$ echo 'Hello World!' | srgn --upper '[wW]orld' 'you' # two actions
Hello YOU!
多个作用域
同样,可以指定多个范围:除了正则表达式模式外,还可以提供一个语言语法感知范围,它将作用于源代码的语法元素(例如,考虑“Python中所有class定义的主体”)。如果同时提供两者,那么正则表达式模式仅应用于第一个范围。这允许进行比使用普通正则表达式更精确的搜索和操作,并且提供了与IDE中的“重命名所有”等工具不同的维度。
例如,考虑这个(无意义的)Python源文件:
"""Module for watching birds and their age."""
from dataclasses import dataclass
@dataclass
class Bird:
"""A bird!"""
name: str
age: int
def celebrate_birthday(self):
print("🎉")
self.age += 1
@classmethod
def from_egg(egg):
"""Create a bird from an egg."""
pass # No bird here yet!
def register_bird(bird: Bird, db: Db) -> None:
"""Registers a bird."""
assert bird.age >= 0
with db.tx() as tx:
tx.insert(bird)
可以使用以下方式搜索:
$ cat birds.py | srgn --python 'class' 'age'
11: age: int
15: self.age += 1
寻找字符串age,并仅在Python class定义中找到(例如,不在函数体register_bird中)。默认情况下,此“搜索模式”也会打印行号。如果没有指定操作,则进入搜索模式,并且提供了--python之类的语言(类似于ripgrep,但具有语法语言元素)。
搜索也可以跨行进行,例如查找缺少文档字符串的方法(即def在class内)。
$ cat birds.py | srgn --python 'class' 'def .+:\n\s+[^"\s]{3}' # do not try this pattern at home
13: def celebrate_birthday(self):
14: print("🎉")
注意,这没有显示from_egg(有文档字符串)或register_bird(不是方法,def不在class内)。
多个语言范围
语言范围也可以指定多次。例如,在Rust代码片段中
pub enum Genre {
Rock(Subgenre),
Jazz,
}
const MOST_POPULAR_SUBGENRE: Subgenre = Subgenre::Something;
pub struct Musician {
name: String,
genres: Vec<Subgenre>,
}
可以按如下方式精确地钻取多个项目:
$ cat music.rs | srgn --rust 'pub-enum' --rust 'type-identifier' 'Subgenre' # AND'ed together
2: Rock(Subgenre),
只有匹配所有标准的行才会返回,这就像所有条件之间的逻辑与操作。请注意,条件是从左到右评估的,这排除了某些组合没有意义:例如,在文档字符串doc-strings内搜索class主体通常返回空结果。然而,相反的操作是预期的。
$ cat birds.py | srgn --python 'class' --python 'doc-strings' # From earlier example
8: """A bird!"""
19: """Create a bird from an egg."""
没有在class主体之外的文档字符串被显示出来!
-j标志改变了这种行为:从左到右交集,改为独立运行所有查询并合并它们的结果,允许你同时进行多种搜索
$ cat birds.py | srgn -j --python 'comments' --python 'doc-strings' 'bird[^s]'
8: """A bird!"""
19: """Create a bird from an egg."""
20: pass # No bird here yet!
24: """Registers a bird."""
递归工作
如果没有提供标准输入,srgn会自动找到相关的源文件,例如在这个存储库中
$ srgn --python 'class' 'age'
docs/samples/birds
11: age: int
15: self.age += 1
docs/samples/birds.py
9: age: int
13: self.age += 1
它会递归地遍历当前目录,根据文件扩展名和shebang行查找文件,以非常高的速度处理。例如,srgn --go strings '\d+'在约3秒内打印出约140,000个Go代码字面量中的数字,该Go代码库包含约3,000,000行Go代码。更多信息请参见以下内容。
组合操作和范围
几乎可以任意组合范围和操作。例如,考虑这个Python代码片段(支持更多语言示例)
"""GNU module."""
def GNU_says_moo():
"""The GNU function -> say moo -> ✅"""
GNU = """
GNU
""" # the GNU...
print(GNU + " says moo") # ...says moo
使用以下方式调用:
cat gnu.py | srgn --titlecase --python 'doc-strings' '(?<!The )GNU ([a-z]+)' '$1: GNU 🐂 is not Unix'
使用了多个作用域(语言和正则表达式模式)以及多个动作(替换和首字母大写)。结果如下所示:
"""Module: GNU 🐂 Is Not Unix."""
def GNU_says_moo():
"""The GNU function -> say moo -> ✅"""
GNU = """
GNU
""" # the GNU...
print(GNU + " says moo") # ...says moo
更改仅限于以下内容:
- """GNU module."""
+ """Module: GNU 🐂 Is Not Unix."""
def GNU_says_moo():
"""The GNU -> say moo -> ✅"""
此外还演示了...
[!警告]
由于
srgn处于测试版(主要版本 0),请确保只(递归地)处理您可以安全 恢复 的文件。搜索模式不会覆盖文件,因此总是安全的。
有关工具的完整帮助输出,请参阅 以下内容。
安装
预构建的二进制文件
从 发布版 下载预构建的二进制文件。
cargo-binstall
此crate提供与其兼容的格式 与 cargo-binstall
- 安装 Rust 工具链
- 运行
cargo install cargo-binstall(可能需要一些时间) - 运行
cargo binstall srgn(几秒钟,因为它从 GitHub 下载 预构建的二进制文件)
这些步骤保证可以正常工作™,因为它们已在 CI 中测试过。如果没有为您的平台提供预构建的二进制文件,这些步骤也适用,因为工具将回退到 从源编译。
Homebrew
通过以下方式提供 公式:
brew install srgn
Nix
通过 不稳定版 提供。
nix-shell -p srgn
Arch Linux
通过 AUR 提供。
MacPorts
提供 端口。
sudo port install srgn
CI(GitHub Actions)
所有 GitHub Actions 运行器镜像 都预装了 cargo,并且 cargo-binstall 提供了一个方便的 GitHub Action
jobs:
srgn:
name: Install srgn in CI
# All three major OSes work
runs-on: ubuntu-latest
steps:
- uses: cargo-bins/cargo-binstall@main
- name: Install binary
run: >
cargo binstall
--no-confirm
srgn
- name: Use binary
run: srgn --version
以上步骤总共只需 5 秒,因为无需编译。有关更多上下文,请参阅 cargo-binstall 在 CI 中的建议。
Cargo(从源编译)
- 安装 Rust 工具链
- 需要C编译器
-
在 Linux 上,
gcc可以工作。 -
在 macOS 上,使用
clang。 -
在 Windows 上,MSVC 可以工作。
在安装时选择“使用 C++ 的桌面开发”。
-
- 运行
cargo install srgn
Cargo(作为 Rust 库)
cargo add srgn
有关更多信息,请参阅 此处。
Shell 完整性
支持多种shell用于shell自动完成脚本。例如,将eval "$(srgn --completions zsh)"追加到~/.zshrc,以在ZSH中进行自动完成。
使用说明
该工具的设计基于作用域和动作。作用域缩小了要处理的输入部分。然后动作执行处理。通常,作用域和动作都是可组合的,所以每个可能传递多个。两者都是可选的(但不执行任何操作是没有意义的);指定无作用域表示整个输入都在作用域内。
同时,与普通的tr命令有相当大的重叠:该工具旨在在大多数常见用例中具有紧密的对应关系,仅在需要时超出。
动作
最简单的动作是替换。它专门用于与tr的兼容性(作为一个参数,而不是一个选项),以及一般的工程学。所有其他动作都作为标志提供,或者如果有值则作为选项。
替换
例如,简单、单字符的替换与tr类似。
$ echo 'Hello, World!' | srgn 'H' 'J'
Jello, World!
第一个参数是作用域(本例中为字面量H)。任何匹配它的内容都将受到处理(在这种情况下,由第二个参数,即J,进行替换)。然而,与tr中的字符类没有直接的概念。相反,默认情况下,作用域是一个正则表达式模式,因此可以使用其类达到类似的效果。
$ echo 'Hello, World!' | srgn '[a-z]' '_'
H____, W____!
默认情况下,替换在整个匹配项中贪婪地进行(注意UTS字符类,让人联想到tr's [:alnum:])
$ echo 'ghp_oHn0As3cr3T!!' | srgn 'ghp_[[:alnum:]]+' '*' # A GitHub token
*!!
支持高级正则表达式功能,例如前瞻
$ echo 'ghp_oHn0As3cr3T' | srgn '(?<=ghp_)[[:alnum:]]+' '*'
ghp_*
请小心使用这些功能,因为高级模式没有某些安全和性能保证。如果不使用它们,性能不会受到影响。
替换不仅限于单个字符。它可以是一个任何字符串,例如修复这个引用
$ echo '"Using regex, I now have no issues."' | srgn 'no issues' '2 problems'
"Using regex, I now have 2 problems."
该工具完全支持Unicode,并提供对某些高级字符类的有用支持
$ echo 'Mood: 🙂' | srgn '🙂' '😀'
Mood: 😀
$ echo 'Mood: 🤮🤒🤧🦠 :(' | srgn '\p{Emoji_Presentation}' '😷'
Mood: 😷😷😷😷 :(
变量
替换意识到了变量,这些变量可以通过正则表达式捕获组来访问。捕获组可以编号,也可以可选地命名。第零个捕获组对应于整个匹配项。
$ echo 'Swap It' | srgn '(\w+) (\w+)' '$2 $1' # Regular, numbered
It Swap
$ echo 'Swap It' | srgn '(\w+) (\w+)' '$2 $1$1$1' # Use as many times as you'd like
It SwapSwapSwap
$ echo 'Call +1-206-555-0100!' | srgn 'Call (\+?\d\-\d{3}\-\d{3}\-\d{4}).+' 'The phone number in "$0" is: $1.' # Variable `0` is the entire match
The phone number in "Call +1-206-555-0100!" is: +1-206-555-0100.
更高级的使用案例是,例如,使用命名捕获组进行代码重构(也许你可以想出一个更有用的例子...)
$ echo 'let x = 3;' | srgn 'let (?<var>[a-z]+) = (?<expr>.+);' 'const $var$var = $expr + $expr;'
const xx = 3 + 3;
与bash一样,使用花括号来区分变量和其相邻内容
$ echo '12' | srgn '(\d)(\d)' '$2${1}1'
211
$ echo '12' | srgn '(\d)(\d)' '$2$11' # will fail (`11` is unknown)
$ echo '12' | srgn '(\d)(\d)' '$2${11' # will fail (brace was not closed)
替换之外
由于替换只是一个静态字符串,它的用途有限。这就是tr的秘密配方通常起作用的地方:使用它的字符类,这些类在第二个位置也是有效的,可以巧妙地将第一个位置的成员翻译到第二个位置。在这里,这些类变成了正则表达式,并且只在第一个位置(作用域)有效。正则表达式作为一个状态机,无法匹配到“字符列表”,在tr中这是第二个(可选)参数。这个概念已经不存在了,其灵活性也丧失了。
相反,提供的所有固定操作都被使用。看一下tr最常见用例,可以发现提供的操作集几乎涵盖了所有这些!如果您的情况未被涵盖,请随时提交问题。
接下来是下一个操作。
删除
从输入中删除找到的内容。与tr中的标志名称相同。
$ echo 'Hello, World!' | srgn -d '(H|W|!)'
ello, orld
[!注意] 默认作用域是匹配整个输入,因此指定删除操作而没有指定作用域是错误的。
压缩
将匹配作用域的字符重复项压缩成单个出现。与tr中的标志名称相同。
$ echo 'Helloooo Woooorld!!!' | srgn -s '(o|!)'
Hello World!
如果传递了字符类,该类的所有成员都会被压缩到遇到的第一个类成员
$ echo 'The number is: 3490834' | srgn -s '\d'
The number is: 3
匹配贪婪性没有修改,所以请注意
$ echo 'Winter is coming... 🌞🌞🌞' | srgn -s '🌞+'
Winter is coming... 🌞🌞🌞
[!注意] 匹配到的整个序列,所以没有东西可以压缩。夏天占主导地位。
如果用例需要,可以反转贪婪性
$ echo 'Winter is coming... 🌞🌞🌞' | srgn -s '🌞+?' '☃️'
Winter is coming... ☃️
[!注意] 同样,与删除一样,如果没有指定明确的作用域就指定压缩是错误的。否则,整个输入将被压缩。
字符大小写
tr的大部分使用属于这一类别。它非常简单直接。
$ echo 'Hello, World!' | srgn --lower
hello, world!
$ echo 'Hello, World!' | srgn --upper
HELLO, WORLD!
$ echo 'hello, world!' | srgn --titlecase
Hello, World!
规范化
根据规范化形式D分解输入,然后丢弃标记类别(见示例)中的代码点。这大致意味着:取花哨的字符,撕掉悬垂部分,扔掉。
$ echo 'Naïve jalapeño ärgert mgła' | srgn -d '\P{ASCII}' # Naive approach
Nave jalapeo rgert mga
$ echo 'Naïve jalapeño ärgert mgła' | srgn --normalize # Normalize is smarter
Naive jalapeno argert mgła
注意mgła在NFD的作用域之外,因为它“原子”且因此不可分解(至少这是ChatGPT在我耳边低语的内容)。
符号
这个操作用适当的单代码点、原生的Unicode对应物替换多字符ASCII符号。
$ echo '(A --> B) != C --- obviously' | srgn --symbols
(A ⟶ B) ≠ C — obviously
或者,如果您只对数学感兴趣,请使用作用域
$ echo 'A <= B --- More is--obviously--possible' | srgn --symbols '<='
A ≤ B --- More is--obviously--possible
由于ASCII符号及其替换之间有一个1:1对应关系,因此效果是可逆的[^1]。
$ echo 'A ⇒ B' | srgn --symbols --invert
A => B
目前支持的符号集有限,但可以添加更多。
德语
这个操作将德语特殊字符(ae、oe、ue、ss)的变体替换为它们的原生版本(ä、ö、ü、ß)[^2]。
$ echo 'Gruess Gott, Neueroeffnungen, Poeten und Abenteuergruetze!' | srgn --german
Grüß Gott, Neueröffnungen, Poeten und Abenteuergrütze!
这个操作基于一个单词列表(如果这使您的二进制文件过于庞大,请不要编译带有german功能的版本)。注意以下关于上述示例的功能
- 空作用域和替换:将处理整个输入,不执行任何替换
Poeten保持原样,而不是被天真地错误地转换为Pöten- 作为一个(复合)词,
Abenteuergrütze在任何合理的词表中都找不到,但仍然得到了妥善处理 - 在作为复合词的一部分时,
Abenteuer也保持原样,而没有错误地转换为Abenteür - 最后,
Neueroeffnungen悄悄地形成了一个没有构成词(neu,Eröffnungen)拥有的ue元素,但仍然被正确处理(即使大小写不匹配也是如此)
应要求,可以进行替换,这对于名称可能是有用的
$ echo 'Frau Loetter steht ueber der Mauer.' | srgn --german-naive '(?<=Frau )\w+'
Frau Lötter steht ueber der Mauer.
通过正向前瞻,只有问候语被限定范围并因此被更改。 Mauer正确地保持原样,但ueber没有被处理。第二次遍历解决这个问题
$ echo 'Frau Loetter steht ueber der Mauer.' | srgn --german-naive '(?<=Frau )\w+' | srgn --german
Frau Lötter steht über der Mauer.
[!注意]
与某些“父级”相关的选项和标志以它们父级的名称作为前缀,并且当给出时将隐含其父级,这样后者就不需要显式传递。这就是为什么
--german-naive被命名为这样,并且--german不需要传递。一旦
clap支持子命令链,这种行为可能会改变。
由于没有语言上下文,这个工具对于某些分支来说是不可决定的。例如,Busse(公共汽车)和Buße(忏悔)都是合法的词。默认情况下,如果合法,会贪婪地进行替换(这就是srgn的根本目的),但有一个标志可以切换这种行为
$ echo 'Busse und Geluebte 🙏' | srgn --german
Buße und Gelübte 🙏
$ echo 'Busse 🚌 und Fussgaenger 🚶♀️' | srgn --german-prefer-original
Busse 🚌 und Fußgänger 🚶♀️
组合动作
大多数动作都是可组合的,除非这样做没有意义(例如,对于删除)。它们的应用顺序是固定的,因此给定的标志的顺序没有影响(如果需要,管道化多次运行是另一种选择)。替换总是首先发生。一般来说,CLI被设计为防止误用和意外:它更喜欢崩溃而不是做意想不到的事情(这当然是主观的)。请注意,许多组合在技术上都是可能的,但可能产生不合理的结果。
组合动作可能看起来像
$ echo 'Koeffizienten != Bruecken...' | srgn -Sgu
KOEFFIZIENTEN ≠ BRÜCKEN...
可以指定一个更窄的范围,并将适用于所有动作
$ echo 'Koeffizienten != Bruecken...' | srgn -Sgu '\b\w{1,8}\b'
Koeffizienten != BRÜCKEN...
需要使用单词边界,否则Koeffizienten会被匹配为Koeffizi和enten。注意,尾随句点不能被挤压。所需的.范围会干扰给定的范围。正则管道可以解决这个问题
$ echo 'Koeffizienten != Bruecken...' | srgn -Sgu '\b\w{1,8}\b' | srgn -s '\.'
Koeffizienten != BRÜCKEN.
注意:可以通过字面范围绕过正则表达式转义(.)。特别处理的替换动作也是可组合的
$ echo 'Mooood: 🤮🤒🤧🦠!!!' | srgn -s '\p{Emoji}' '😷'
Mooood: 😷!!!
首先替换所有表情符号,然后挤压。注意,没有其他东西被挤压。
范围
范围是srgn的第二个驱动概念。在默认情况下,主要范围是一个正则表达式。在动作部分详细展示了这个用例,因此这里不再重复。它作为第一个位置参数给出。
语言语法感知范围
srgn 通过预准备、语法感知的作用域扩展此功能,这是通过出色的 tree-sitter 库实现的。它提供了一个 查询 功能,它的工作方式类似于与 树数据结构 进行模式匹配。
srgn 随带了一些最有用的这些查询。通过其可发现的 API(要么作为库,要么通过 CLI,srgn --help),可以了解支持的语言和可用的预准备查询。每种支持的语言都附带一个逃生舱口,允许您运行自己的、定制的 ad-hoc 查询。逃生舱口的形式为 --lang-query <S EXPRESSION>,其中 lang 是一种语言,例如 python。有关更多关于这个高级主题的信息,请参见 下面。
[!注意]
语言作用域是首先应用的,因此您传递的任何正则表达式(即主要作用域)都将针对每个匹配的语言结构单独操作。
预准备查询(示例展示)
本节展示了部分预准备查询的示例。
批量导入(模块)重命名(Python,Rust)
作为大型重构(比如,在收购之后)的一部分,假设需要重命名特定包的所有导入
import math
from pathlib import Path
import good_company.infra
import good_company.aws.auth as aws_auth
from good_company.util.iter import dedupe
from good_company.shopping.cart import * # Ok but don't do this at home!
good_company = "good_company" # good_company
同时,希望转向 src/ 布局。可以通过以下方式实现这一迁移:
cat imports.py | srgn --python 'imports' '^good_company' 'src.better_company'
这将产生
import math
from pathlib import Path
import src.better_company.infra
import src.better_company.aws.auth as aws_auth
from src.better_company.util.iter import dedupe
from src.better_company.shopping.cart import * # Ok but don't do this at home!
good_company = "good_company" # good_company
注意最后一行没有被这个特定的操作修改。要运行多个文件,请参见 的 files 选项。
还支持其他语言的类似导入相关编辑,例如 Rust
use std::collections::HashMap;
use good_company::infra;
use good_company::aws::auth as aws_auth;
use good_company::util::iter::dedupe;
use good_company::shopping::cart::*;
good_company = "good_company"; // good_company
使用
cat imports.rs | srgn --rust 'uses' '^good_company' 'better_company'
变成
use std::collections::HashMap;
use better_company::infra;
use better_company::aws::auth as aws_auth;
use better_company::util::iter::dedupe;
use better_company::shopping::cart::*;
good_company = "good_company"; // good_company
分配 TODO(TypeScript)
也许您正在使用注释中的 TODO 笔记系统
class TODOApp {
// TODO app for writing TODO lists
addTodo(todo: TODO): void {
// TODO: everything, actually 🤷♀️
}
}
并且通常为每个笔记分配人员。使用以下方法可以自动将您分配到每个未分配的笔记(幸运的您!):
cat todo.ts | srgn --typescript 'comments' 'TODO(?=:)' 'TODO(@poorguy)'
在这种情况下给出
class TODOApp {
// TODO app for writing TODO lists
addTodo(todo: TODO): void {
// TODO(@poorguy): everything, actually 🤷♀️
}
}
注意 正向先行断言 的 (?=:),确保实际触发了 TODO 笔记(TODO:)。否则,评论中提到的其他 TODO 也会被匹配。
将 print 调用转换为适当的 logging(Python)
假设有一些代码大量使用 print
def print_money():
"""Let's print money 💸."""
amount = 32
print("Got here.")
print_more = lambda s: print(f"Printed {s}")
print_more(23) # print the stuff
print_money()
print("Done.")
并希望转向 logging。这可以通过调用完全自动化:
cat money.py | srgn --python 'function-calls' '^print$' 'logging.info'
产生
def print_money():
"""Let's print money 💸."""
amount = 32
logging.info("Got here.")
print_more = lambda s: logging.info(f"Printed {s}")
print_more(23) # print the stuff
print_money()
logging.info("Done.")
[!NOTE] 注意 锚点:
print_more也是一个函数调用,但^print$确保它不会匹配。正则表达式在语法作用域之后应用,因此完全在已经作用域的上下文中操作。
删除所有注释(C#)
过度使用注释可能会变成 坏味道。如果不加注意,它们可能会开始说谎
using System.Linq;
public class UserService
{
private readonly AppDbContext _dbContext;
/// <summary>
/// Initializes a new instance of the <see cref="FileService"/> class.
/// </summary>
/// <param name="dbContext">The configuration for manipulating text.</param>
public UserService(AppDbContext dbContext)
{
_dbContext /* the logging context */ = dbContext;
}
/// <summary>
/// Uploads a file to the server.
/// </summary>
// Method to log users out of the system
public void DoWork()
{
_dbContext.Database.EnsureCreated(); // Ensure the database schema is deleted
_dbContext.Users.Add(new User /* the car */ { Name = "Alice" });
/* Begin reading file */
_dbContext.SaveChanges();
var user = _dbContext.Users.Where(/* fetch products */ u => u.Name == "Alice").FirstOrDefault();
/// Delete all records before proceeding
if (user /* the product */ != null)
{
System.Console.WriteLine($"Found user with ID: {user.Id}");
}
}
}
所以,如果您把清理注释当作一种嗜好,那也无可厚非
cat UserService.cs | srgn --csharp 'comments' -d '.*' | srgn -d '[[:blank:]]+\n'
结果是整洁而沉默寡言的
using System.Linq;
public class UserService
{
private readonly AppDbContext _dbContext;
public UserService(AppDbContext dbContext)
{
_dbContext = dbContext;
}
public void DoWork()
{
_dbContext.Database.EnsureCreated();
_dbContext.Users.Add(new User { Name = "Alice" });
_dbContext.SaveChanges();
var user = _dbContext.Users.Where( u => u.Name == "Alice").FirstOrDefault();
if (user != null)
{
System.Console.WriteLine($"Found user with ID: {user.Id}");
}
}
}
注意如何识别并删除了所有不同类型的注释和XML文档注释。第二次遍历删除了所有剩余的悬垂行([:blank:]是制表符和空格)。
[!注意] 删除(
-d)时,出于安全和稳定性的考虑,需要指定作用域。
升级虚拟机大小(Terraform)
假设您想升级当前使用的实例大小
data "aws_ec2_instance_type" "tiny" {
instance_type = "t2.micro"
}
resource "aws_instance" "main" {
ami = "ami-022f20bb44daf4c86"
instance_type = data.aws_ec2_instance_type.tiny.instance_type
}
使用
cat ec2.tf | srgn --hcl 'strings' '^t2\.(\w+)$' 't3.$1' | srgn --hcl 'data-names' 'tiny' 'small'
将给出
data "aws_ec2_instance_type" "small" {
instance_type = "t3.micro"
}
resource "aws_instance" "main" {
ami = "ami-022f20bb44daf4c86"
instance_type = data.aws_ec2_instance_type.small.instance_type
}
自定义查询
自定义查询允许您创建临时的作用域。例如,可以创建小型、临时的、定制的linters,例如捕获以下代码:
if x:
return left
else:
return right
通过调用
cat cond.py | srgn --python-query '(if_statement consequence: (block (return_statement (identifier))) alternative: (else_clause body: (block (return_statement (identifier))))) @cond' --fail-any # will fail
提示代码可以被更习惯性地重写为 return left if x else right。另一个例子,这是一个Go语言的例子,确保敏感字段不会被序列化
package main
type User struct {
Name string `json:"name"`
Token string `json:"token"`
}
可以通过以下方式捕获
cat sensitive.go | srgn --go-query '(field_declaration name: (field_identifier) @name tag: (raw_string_literal) @tag (#match? @name "[tT]oken") (#not-eq? @tag "`json:\"-\"`"))' --fail-any # will fail
忽略匹配的部分
有时需要忽略匹配的部分,例如当没有合适的tree-sitter节点类型时。例如,假设我们想在宏体字符串中将error替换为wrong
fn wrong() {
let wrong = "wrong";
error!("This went error");
}
假设有一个节点类型用于匹配整个宏(macro_invocation)和一个匹配宏名称的节点类型(((macro_invocation macro: (identifier) @name))),但没有匹配宏内容的节点类型(这是错误的,tree-sitter提供这种形式为token_tree,但让我们想象一下...)。为了匹配"This went error",需要匹配整个宏,忽略名称部分。任何以_SRGN_IGNORE开始的捕获名称将提供这一点
cat wrong.rs | srgn --rust-query '((macro_invocation macro: (identifier) @_SRGN_IGNORE_name) @macro)' 'error' 'wrong'
fn wrong() {
let wrong = "wrong";
error!("This went wrong");
}
如果不忽略,结果将读作wrong!("This went wrong");。
进一步阅读
这些匹配表达式有点复杂。有一些资源可以帮助您开始自己的查询
-
官方的交互式playground,它使得开发查询变得容易。例如,上面的Go示例看起来像

-
如何在一小时内使用tree-sitter编写linters,这是关于这个主题的很好的一般介绍
-
使用
srgn时,使用高冗余(-vvvv)可以提供对输入发生情况的详细洞察,包括解析树的表示
针对多个文件运行
使用--glob选项针对多个文件进行原地运行。此选项接受一个glob模式。glob在srgn内部处理:它必须加引号以防止shell提前解释。--glob选项优先于语言作用域的启发式方法。例如,
$ srgn --go 'comments' --glob 'tests/langs/go/fizz*.go' '\w+'
tests/langs/go/fizzbuzz.go
5:// fizzBuzz prints the numbers from 1 to a specified limit.
6:// For multiples of 3, it prints "Fizz" instead of the number,
7:// for multiples of 5, it prints "Buzz", and for multiples of both 3 and 5,
8:// it prints "FizzBuzz".
25: // Run the FizzBuzz function for numbers from 1 to 100
只找到与(狭义)glob匹配的内容,即使--go查询本身会匹配更多内容。
srgn将完全并行处理结果,使用所有可用线程。例如,450k行Python代码大约在一秒钟内处理完毕,修改了数百个文件中的1000多行。
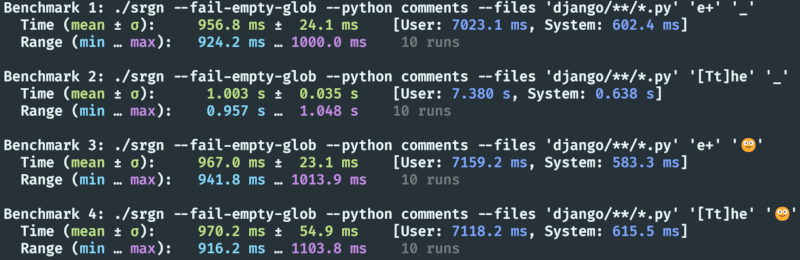
运行基准测试以查看您自己的系统性能。
对于(不)匹配显式失败
在应用所有范围之后,可能会发现没有找到匹配项。默认行为是静默成功
$ echo 'Some input...' | srgn --delete '\d'
Some input...
输出匹配规范:所有数字都被删除了。恰好没有。无论应用多少操作,一旦检测到这种情况,输入将不会被处理。因此,不会进行不必要的操作。
有人可能更喜欢在失败时收到明确的反馈(非零退出码)
echo 'Some input...' | srgn --delete --fail-none '\d' # will fail
也支持逆情景:如果有任何匹配项则失败。这对于检查“不受欢迎”的内容很有用(例如,在CI中)。这工作方式与自定义的临时linter类似。
以“旧式”Python代码为例,其中类型提示尚未显示到语法级别
def square(a):
"""Squares a number.
:param a: The number (type: int or float)
"""
return a**2
可以使用以下方式检查并“禁止”此样式
cat oldtyping.py | srgn --python 'doc-strings' --fail-any 'param.+type' # will fail
文字范围
这导致传递给正则表达式范围的任何内容都将按文字解释。对于包含大量特殊字符的范围非常有用,否则需要转义这些字符。
$ echo 'stuff...' | srgn -d --literal-string '.'
stuff
帮助输出
以下是包含所有可用选项的完整帮助输出,仅供参考。与其他所有片段一样,输出在单元测试中验证了其正确性。查看git标签以查看特定版本的帮助输出。
$ srgn --help
A grep-like tool which understands source code syntax and allows for manipulation in
addition to search
Usage: srgn [OPTIONS] [SCOPE] [REPLACEMENT]
Arguments:
[SCOPE]
Scope to apply to, as a regular expression pattern.
If string literal mode is requested, will be interpreted as a literal
string.
Actions will apply their transformations within this scope only.
The default is the global scope, matching the entire input. Where that
default is meaningless or dangerous (e.g., deletion), this argument is
required.
[default: .*]
Options:
--completions <SHELL>
Print shell completions for the given shell.
[possible values: bash, elvish, fish, powershell, zsh]
-h, --help
Print help (see a summary with '-h')
-V, --version
Print version
Composable Actions:
-u, --upper
Uppercase anything in scope.
[env: UPPER=]
-l, --lower
Lowercase anything in scope.
[env: LOWER=]
-t, --titlecase
Titlecase anything in scope.
[env: TITLECASE=]
-n, --normalize
Normalize (Normalization Form D) anything in scope, and throw away marks.
[env: NORMALIZE=]
-g, --german
Perform substitutions on German words, such as 'Abenteuergruesse' to
'Abenteuergrüße', for anything in scope.
ASCII spellings for Umlauts (ae, oe, ue) and Eszett (ss) are replaced by
their respective native Unicode (ä, ö, ü, ß).
Arbitrary compound words are supported.
Words legally containing alternative spellings are not modified.
Words require correct spelling to be detected.
-S, --symbols
Perform substitutions on symbols, such as '!=' to '≠', '->' to '→', on
anything in scope.
Helps translate 'ASCII art' into native Unicode representations.
[REPLACEMENT]
Replace anything in scope with this value.
Variables are supported: if a regex pattern was used for scoping and
captured content in named or numbered capture groups, access these in the
replacement value using `$1` etc. for numbered, `$NAME` etc. for named
capture groups.
This action is specially treated as a positional argument for ergonomics and
compatibility with `tr`.
If given, will run before any other action.
[env: REPLACE=]
Standalone Actions (only usable alone):
-d, --delete
Delete anything in scope.
Cannot be used with any other action: there is no point in deleting and
performing any other processing. Sibling actions would either receive empty
input or have their work wiped.
-s, --squeeze
Squeeze consecutive occurrences of scope into one.
[env: SQUEEZE=]
[aliases: squeeze-repeats]
Options (global):
-G, --glob <GLOB>
Glob of files to work on (instead of reading stdin).
If actions are applied, they overwrite files in-place.
For supported glob syntax, see:
<https://docs.rs/glob/0.3.1/glob/struct.Pattern.html>
Names of processed files are written to stdout.
--fail-no-files
Fail if working on files (e.g. globbing is requested) but none are found.
Processing no files is not an error condition in itself, but might be an
unexpected outcome in some contexts. This flag makes the condition explicit.
-i, --invert
Undo the effects of passed actions, where applicable.
Requires a 1:1 mapping between replacements and original, which is currently
available only for:
- symbols: '≠' <-> '!=' etc.
Other actions:
- german: inverting e.g. 'Ä' is ambiguous (can be 'Ae' or 'AE')
- upper, lower, deletion, squeeze: inversion is impossible as information is
lost
These may still be passed, but will be ignored for inversion and applied
normally.
[env: INVERT=]
-L, --literal-string
Do not interpret the scope as a regex. Instead, interpret it as a literal
string. Will require a scope to be passed.
[env: LITERAL_STRING=]
--fail-any
If anything at all is found to be in scope, fail.
The default is to continue processing normally.
--fail-none
If nothing is found to be in scope, fail.
The default is to return the input unchanged (without failure).
-j, --join-language-scopes
Join (logical 'OR') multiple language scopes, instead of intersecting them.
The default when multiple language scopes are given is to intersect their
scopes, left to right. For example, `--go func --go strings` will first
scope down to `func` bodies, then look for strings only within those. This
flag instead joins (in the set logic sense) all scopes. The example would
then scope any `func` bodies, and any strings, anywhere. Language scopers
can then also be given in any order.
No effect if only a single language scope is given. Also does not affect
non-language scopers (regex pattern etc.), which always intersect.
-H, --hidden
Do not ignore hidden files and directories.
--gitignored
Do not ignore `.gitignore`d files and directories.
--sorted
Process files in lexicographically sorted order, by file path.
In search mode, this emits results in sorted order. Otherwise, it processes
files in sorted order.
Sorted processing disables parallel processing.
--threads <THREADS>
Number of threads to run processing on, when working with files.
If not specified, will default to available parallelism. Set to 1 for
sequential, deterministic (but not sorted) output.
-v, --verbose...
Increase log verbosity level.
The base log level to use is read from the `RUST_LOG` environment variable
(if unspecified, defaults to 'error'), and increased according to the number
of times this flag is given, maxing out at 'trace' verbosity.
Language scopes:
--csharp <CSHARP>
Scope C# code using a prepared query.
[env: CSHARP=]
Possible values:
- comments: Comments (including XML, inline, doc comments)
- strings: Strings (incl. verbatim, interpolated; incl. quotes,
except for interpolated)
- usings: `using` directives (including periods)
- struct: `struct` definitions (in their entirety)
- enum: `enum` definitions (in their entirety)
- interface: `interface` definitions (in their entirety)
- class: `class` definitions (in their entirety)
- method: Method definitions (in their entirety)
- variable-declaration: Variable declarations (in their entirety)
- property: Property definitions (in their entirety)
- constructor: Constructor definitions (in their entirety)
- destructor: Destructor definitions (in their entirety)
- field: Field definitions on types (in their entirety)
- attribute: Attribute names
- identifier: Identifier names
--csharp-query <TREE-SITTER-QUERY>
Scope C# code using a custom tree-sitter query.
[env: CSHARP_QUERY=]
--go <GO>
Scope Go code using a prepared query.
[env: GO=]
Possible values:
- comments: Comments (single- and multi-line)
- strings: Strings (interpreted and raw; excluding struct tags)
- imports: Imports
- type-def: Type definitions
- type-alias: Type alias assignments
- struct: `struct` type definitions
- interface: `interface` type definitions
- const: `const` specifications
- var: `var` specifications
- func: `func` definitions
- method: Method `func` definitions (`func (recv Recv) SomeFunc()`)
- free-func: Free `func` definitions (`func SomeFunc()`)
- init-func: `func init()` definitions
- type-params: Type parameters (generics)
- defer: `defer` blocks
- select: `select` blocks
- go: `go` blocks
- switch: `switch` blocks
- labeled: Labeled statements
- goto: `goto` statements
- struct-tags: Struct tags
--go-query <TREE-SITTER-QUERY>
Scope Go code using a custom tree-sitter query.
[env: GO_QUERY=]
--hcl <HCL>
Scope HashiCorp Configuration Language code using a prepared query.
[env: HCL=]
Possible values:
- variable: `variable` blocks (in their entirety)
- resource: `resource` blocks (in their entirety)
- data: `data` blocks (in their entirety)
- output: `output` blocks (in their entirety)
- provider: `provider` blocks (in their entirety)
- terraform: `terraform` blocks (in their entirety)
- locals: `locals` blocks (in their entirety)
- module: `module` blocks (in their entirety)
- variables: Variable declarations and usages
- resource-names: `resource` name declarations and usages
- resource-types: `resource` type declarations and usages
- data-names: `data` name declarations and usages
- data-sources: `data` source declarations and usages
- comments: Comments
- strings: Literal strings
--hcl-query <TREE-SITTER-QUERY>
Scope HashiCorp Configuration Language code using a custom tree-sitter query.
[env: HCL_QUERY=]
--python <PYTHON>
Scope Python code using a prepared query.
[env: PYTHON=]
Possible values:
- comments: Comments
- strings: Strings (raw, byte, f-strings; interpolation not
included)
- imports: Module names in imports (incl. periods; excl.
`import`/`from`/`as`/`*`)
- doc-strings: Docstrings (not including multi-line strings)
- function-names: Function names, at the definition site
- function-calls: Function calls
- class: Class definitions (in their entirety)
- def: Function definitions (*all* `def` block in their
entirety)
- async-def: Async function definitions (*all* `async def` block in
their entirety)
- methods: Function definitions inside `class` bodies
- class-methods: Function definitions decorated as `classmethod` (excl.
the decorator)
- static-methods: Function definitions decorated as `staticmethod` (excl.
the decorator)
- with: `with` blocks (in their entirety)
- try: `try` blocks (in their entirety)
- lambda: `lambda` statements (in their entirety)
- globals: Global, i.e. module-level variables
- variable-identifiers: Identifiers for variables (left-hand side of
assignments)
- types: Types in type hints
--python-query <TREE-SITTER-QUERY>
Scope Python code using a custom tree-sitter query.
[env: PYTHON_QUERY=]
--rust <RUST>
Scope Rust code using a prepared query.
[env: RUST=]
Possible values:
- comments: Comments (line and block styles; excluding doc comments;
comment chars incl.)
- doc-comments: Doc comments (comment chars included)
- uses: Use statements (paths only; excl. `use`/`as`/`*`)
- strings: Strings (regular, raw, byte; includes interpolation parts in
format strings!)
- attribute: Attributes like `#[attr]`
- struct: `struct` definitions
- priv-struct: `struct` definitions not marked `pub`
- pub-struct: `struct` definitions marked `pub`
- pub-crate-struct: `struct` definitions marked `pub(crate)`
- pub-self-struct: `struct` definitions marked `pub(self)`
- pub-super-struct: `struct` definitions marked `pub(super)`
- enum: `enum` definitions
- priv-enum: `enum` definitions not marked `pub`
- pub-enum: `enum` definitions marked `pub`
- pub-crate-enum: `enum` definitions marked `pub(crate)`
- pub-self-enum: `enum` definitions marked `pub(self)`
- pub-super-enum: `enum` definitions marked `pub(super)`
- enum-variant: Variant members of `enum` definitions
- fn: Function definitions
- impl-fn: Function definitions inside `impl` blocks (associated
functions/methods)
- priv-fn: Function definitions not marked `pub`
- pub-fn: Function definitions marked `pub`
- pub-crate-fn: Function definitions marked `pub(crate)`
- pub-self-fn: Function definitions marked `pub(self)`
- pub-super-fn: Function definitions marked `pub(super)`
- const-fn: Function definitions marked `const`
- async-fn: Function definitions marked `async`
- unsafe-fn: Function definitions marked `unsafe`
- extern-fn: Function definitions marked `extern`
- test-fn: Function definitions with attributes containing `test`
(`#[test]`, `#[rstest]`, ...)
- trait: `trait` definitions
- impl: `impl` blocks
- impl-type: `impl` blocks for types (`impl SomeType {}`)
- impl-trait: `impl` blocks for traits on types (`impl SomeTrait for
SomeType {}`)
- mod: `mod` blocks
- mod-tests: `mod tests` blocks
- type-def: Type definitions (`struct`, `enum`, `union`)
- identifier: Identifiers
- type-identifier: Identifiers for types
- closure: Closure definitions
--rust-query <TREE-SITTER-QUERY>
Scope Rust code using a custom tree-sitter query.
[env: RUST_QUERY=]
--typescript <TYPESCRIPT>
Scope TypeScript code using a prepared query.
[env: TYPESCRIPT=]
Possible values:
- comments: Comments
- strings: Strings (literal, template)
- imports: Imports (module specifiers)
- function: Any `function` definitions
- async-function: `async function` definitions
- sync-function: Non-`async function` definitions
- method: Method definitions
- constructor: `constructor` method definitions
- class: `class` definitions
- enum: `enum` definitions
- interface: `interface` definitions
- try-catch: `try`/`catch`/`finally` blocks
- var-decl: Variable declarations (`let`, `const`, `var`)
- let: `let` variable declarations
- const: `const` variable declarations
- var: `var` variable declarations
- type-params: Type (generic) parameters
- type-alias: Type alias declarations
- namespace: `namespace` blocks
- export: `export` blocks
--typescript-query <TREE-SITTER-QUERY>
Scope TypeScript code using a custom tree-sitter query.
[env: TYPESCRIPT_QUERY=]
Options (german):
--german-prefer-original
When some original version and its replacement are equally legal, prefer the
original and do not modify.
For example, "Busse" (original) and "Buße" (replacement) are equally legal
words: by default, the tool would prefer the latter.
[env: GERMAN_PREFER_ORIGINAL=]
--german-naive
Always perform any possible replacement ('ae' -> 'ä', 'ss' -> 'ß', etc.),
regardless of legality of the resulting word
Useful for names, which are otherwise not modifiable as they do not occur in
dictionaries. Called 'naive' as this does not perform legal checks.
[env: GERMAN_NAIVE=]
Rust库
虽然这个工具以CLI为首选,但它也非常接近库,并且对库的使用被视为一等公民。有关更多信息和库特定细节,请参阅库文档。
请注意,二进制文件具有优先权,因为当前该crates同时是库和二进制文件,这可能会引起问题。这可能在将来得到修复。
状态和统计信息
![]()
![]()
![]()
注意:这些适用于整个存储库,包括二进制文件。
代码覆盖率icicle图
代码目前的结构如下(颜色表示覆盖率)

将鼠标悬停在矩形上以查看文件名。
贡献
类似工具
这是一个可能感兴趣的类似工具的无序列表。
- GritQL(非常相似)
ast-grep(非常相似)- Semgrep
pssfastmodprefactorgrep-astambersdripgrepripgrep-structured- tree-sitter CLI
gron- Ruleguard(相当不同,但用于自定义linting很有用)
- Coccinelle for Rust
与tr的比较
srgn 是由 tr 启发而来,其最简单的形式行为类似,但并非完全相同。在理论上,tr 非常灵活。在实践中,它通常主要在几个特定的任务中使用。除了其两个位置参数(字符数组)外,还有四个标志:
-c、-C、--complement:补全第一个数组-d、--delete:删除第一个数组中的字符-s、--squeeze-repeats:压缩第一个数组中字符的重复-t、--truncate-set1:将第一个数组截断为第二个数组的长度
在 srgn 中,这些操作如下实现:
- 不是直接作为选项提供的;相反,可以使用正则表达式类的否定(例如,
[^a-z]),以达到更强大、更灵活、更广为人知的效果 - 可用(通过正则表达式)
- 可用(通过正则表达式)
- 不可用:它不适用于正则表达式,不常用,如果使用,通常使用不当
为了说明在野外发现的 tr 的用法如何转换为 srgn,请考虑以下部分。
用例和等价性
以下部分是大多数 tr 用法的大致分类。它们是通过使用 GitHub 的代码搜索 找到的。给出了相应的查询。结果来自当时的结果页面的第一页。代码示例是它们各自来源的链接。
由于标准输入是未知的(通常是动态的),因此使用了一些代表性的样本,并对这些样本进行了测试。
标识符安全性
使输入安全地用作标识符,例如作为变量名。
-
转换为
$ echo 'some-variable? 🤔' | srgn '[^[:alnum:]_\n]' '_' some_variable___类似的例子还有
-
转换为
$ echo 'some variablê' | srgn '[^[:alnum:]]' '_' some__variabl_ -
转换为
$ echo '🙂 hellö???' | srgn -s '[^[:alnum:]]' '-' -hell-
字符到字符的转换
将 单个 文字字符转换为另一个,例如清除换行符。
-
转换为
$ echo 'x86_64 arm64 i386' | srgn ' ' ';' x86_64;arm64;i386类似的例子还有
-
转换为
$ echo '3.12.1' | srgn --literal-string '.' '\n' # Escape sequence works 3 12 1 $ echo '3.12.1' | srgn '\.' '\n' # Escape regex otherwise 3 12 1 -
转换为
$ echo -ne 'Some\nMulti\nLine\nText' | srgn --literal-string '\n' ',' Some,Multi,Line,Text如果转义序列保持未解释(
echo -E,默认),则作用域的转义序列需要转换为字面量\和n,否则该工具将其解释为换行符$ echo -nE 'Some\nMulti\nLine\nText' | srgn --literal-string '\\n' ',' Some,Multi,Line,Text类似的例子还有
删除字符类
非常有用,可以一次性删除整个类别。
-
删除所有标点符号
转换为
$ echo 'Lots... of... punctuation, man.' | srgn -d '[[:punct:]]' Lots of punctuation man
许多用例还需要先 反转,然后再删除字符类。
-
转换为
$ echo 'i RLY love LOWERCASING everything!' | srgn -d '[^[:lower:]]' iloveeverything -
转换为
$ echo 'All0wed ??? 💥' | srgn -d '[^[:alnum:]]' All0wed -
转换为
$ echo '{"id": 34987, "name": "Harold"}' | srgn -d '[^[:digit:]]' 34987
删除字面字符
与用空字符串替换它们相同。
-
转换为
$ echo '1632485561.123456' | srgn -d '\.' # Unix timestamp 1632485561123456类似的例子还有
-
转换为
$ echo -e 'DOS-Style\r\n\r\nLines' | srgn -d '\r\n' DOS-StyleLines类似的例子还有
压缩空白字符
删除重复的空白字符,因为它们在切割和分割文本时经常出现。
-
转换为
$ echo 'Lots of space !' | srgn -s '[[:space:]]' # Single space stays Lots of space !类似的例子还有
tr-s" "tr -s [:blank:](blank是\t和空格)tr -s(无参数:这将出错;可能是指空格)tr-s' 'tr-s' 'tr-s'[:space:]'tr-s' '
-
tr -s ' ' '\n'(压缩,然后替换)转换为
$ echo '1969-12-28 13:37:45Z' | srgn -s ' ' 'T' # ISO8601 1969-12-28T13:37:45Z -
转换为
$ echo -e '/usr/local/sbin \t /usr/local/bin' | srgn -s '[[:blank:]]' ':' /usr/local/sbin:/usr/local/bin
更改字符大小写
这是一个简单的用例。大小写字母经常被使用。
-
tr A-Z a-z(小写化)转换为
$ echo 'WHY ARE WE YELLING?' | srgn --lower why are we yelling?注意默认作用域。它可以细化,例如,只将长单词转换为小写
$ echo 'WHY ARE WE YELLING?' | srgn --lower '\b\w{,3}\b' why are we YELLING?类似的例子还有
-
tr '[a-z]' '[A-Z]'(大写化)转换为
$ echo 'why are we not yelling?' | srgn --upper WHY ARE WE NOT YELLING?类似的例子还有
许可证
本项目根据您的选择许可为以下之一
- Apache许可证版本2.0,(LICENSE-APACHE 或 https://apache.ac.cn/licenses/LICENSE-2.0)
- MIT许可证 (LICENSE-MIT 或 https://open-source.org.cn/licenses/MIT)
自由选择。
[^1]: 目前,对于任何其他操作,都不可逆。例如,小写化不是大写化的逆操作。信息已丢失,因此无法撤销。结构(想象混合大小写)已丢失。某物某物熵... [^2]: 为什么包含这样一个奇怪、无关的特性?像往常一样,是出于历史原因。最初的核心版本 srgn 仅仅是 之前现有工具 的 Rust 重写,该工具 仅 关注 德语 功能。srgn 然后从那里发展起来。 [^3]: 在没有操作和没有语言作用域的情况下,srgn 变得“无用”,其他工具(如 ripgrep)更适合。这就是为什么会发出错误,并且输入保持不变。
依赖关系
~93MB
~2.5M SLoC