1 个不稳定版本
使用旧的 Rust 2015
| 0.5.0 | 2018年4月15日 |
|---|---|
| 0.4.0 |
|
| 0.3.1 |
|
| 0.2.0 |
|
| 0.1.0 |
|
1674 在 数据结构 中
每月下载 35 次
91KB
635 行
包含(ZIP 文件,14KB)doc/illustration-with-heap.odg,(ZIP 文件,13KB)doc/illustration.odg
seq 模块
seq 模块为不可移动数据提供了轻量级的泛型序列容器 Seq,并在编译时嵌入到程序中。 Seq 的元素是堆叠在一起的。
最初序列为空。较长的序列通过将新的 头部 添加到现有序列中构建,表示 尾部。
多个序列可以共享同一个 尾部,允许高效组织分层数据。
用法
将此放入您的 Cargo.toml 中
## Cargo.toml file
[dependencies]
seq = "0.5"
此类型作为队列的 "默认" 用法是使用 Empty 或 ConsRef 来构建队列,并使用 head 和 tail 来将队列拆分为头部和剩余的序列尾部。
pub enum Seq<'a, T: 'a> {
Empty,
ConsRef(T, &'a Seq<'a, T>),
ConsOwn(T, Box<Seq<'a, T>>),
}
示例
构建两个序列 seq1 为 [1,0] 和 seq2 为 [2,1,0,0],与 seq1 共享数据
// constructing the sequence 'seq1'
const seq1: Seq<i32> = Seq::ConsRef(1, &Seq::ConsRef(0, &Seq::Empty));
// construction the sequence 'seq2' sharing data with 'seq1'
const seq2: Seq<i32> = Seq::ConsRef(2, &seq1);
拆分序列
fn print_head<'a>(seq: &'a Seq<i32>) {
println!("head {}", seq.head().unwrap());
}
扩展现有序列。注意返回类型的生命周期与尾部相同。
fn extend<'a>(head: i32, tail: &'a Seq<i32>) -> Seq<'a, i32> {
return Seq::ConsRef(head, tail);
}
使用堆内存中的动态元素扩展现有序列
fn extend_boxed<'a>(head: i32, tail: &'a Seq<i32>) -> Box<Seq<'a, i32>> {
return Box::new(Seq::ConsRef(head, tail));
}
迭代序列
fn sum_up(seq: &Seq<i32>) -> i32 {
return seq.into_iter().fold(0, |x, y| x + y);
}
内存布局
以下图像展示了序列 s、t、u。序列 s 是 t 的子序列,而 t 是 u 的子序列;每个都在其函数上下文中可访问。 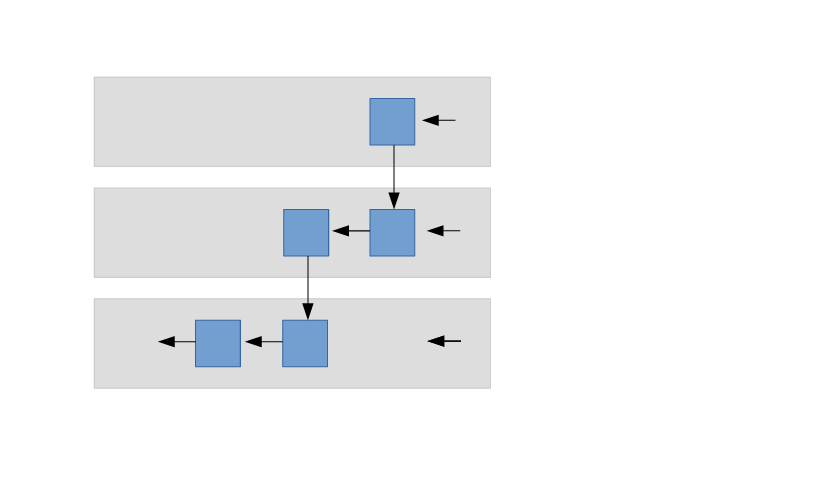
对于需要子例程/表达式返回临时扩展序列的用例,可以使用堆内存中的元素构建新序列。在这种情况下,这些堆元素是装箱的/拥有的。 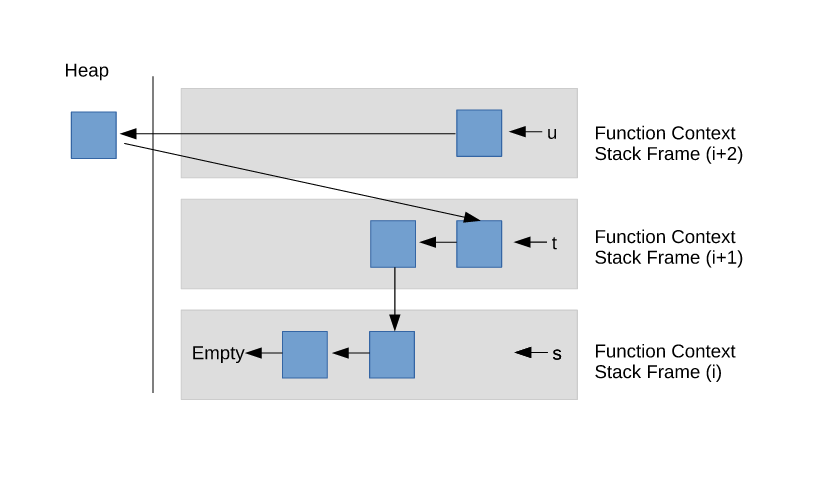
基准测试
数据结构 Seq 实现了一个链表。在性能方面,它无法与原生数组竞争。但是,Seq 在容器 Vec 和 LinkedList 之间。
基准测试是一个内存密集型、递归函数调用,并受益于连续内存;每次递归函数调用都会添加一个新的整型元素,并累积所有元素。
如基准图表所示,容器 Seq 对于最多 N=16 个元素的性能优于 Vec 和 LinkedList;如果元素少于 N=64,甚至表现出比 LinkedList 更好的性能。基准测试的范围是 N=8, 16, 32, 64, 128, 256, 512。
>cargo bench--features benchmark
test benchmark::bench_array___8 ... bench: 0 ns/iter (+/- 0)
test benchmark::bench_array__16 ... bench: 0 ns/iter (+/- 0)
test benchmark::bench_array__32 ... bench: 196 ns/iter (+/- 9)
test benchmark::bench_array__64 ... bench: 450 ns/iter (+/- 29)
test benchmark::bench_array_128 ... bench: 1,109 ns/iter (+/- 98)
test benchmark::bench_array_256 ... bench: 3,125 ns/iter (+/- 50)
test benchmark::bench_array_512 ... bench: 12,053 ns/iter (+/- 230)
test benchmark::bench_list___8 ... bench: 215 ns/iter (+/- 4)
test benchmark::bench_list__16 ... bench: 527 ns/iter (+/- 10)
test benchmark::bench_list__32 ... bench: 1,408 ns/iter (+/- 461)
test benchmark::bench_list__64 ... bench: 4,209 ns/iter (+/- 86)
test benchmark::bench_list_128 ... bench: 13,638 ns/iter (+/- 884)
test benchmark::bench_list_256 ... bench: 52,786 ns/iter (+/- 4,552)
test benchmark::bench_list_512 ... bench: 188,453 ns/iter (+/- 3,053)
test benchmark::bench_seq___8 ... bench: 53 ns/iter (+/- 1)
test benchmark::bench_seq__16 ... bench: 191 ns/iter (+/- 10)
test benchmark::bench_seq__32 ... bench: 1,081 ns/iter (+/- 30)
test benchmark::bench_seq__64 ... bench: 4,432 ns/iter (+/- 82)
test benchmark::bench_seq_128 ... bench: 16,749 ns/iter (+/- 209)
test benchmark::bench_seq_256 ... bench: 63,775 ns/iter (+/- 528)
test benchmark::bench_seq_512 ... bench: 247,919 ns/iter (+/- 2,183)
test benchmark::bench_vec___8 ... bench: 111 ns/iter (+/- 3)
test benchmark::bench_vec__16 ... bench: 221 ns/iter (+/- 4)
test benchmark::bench_vec__32 ... bench: 398 ns/iter (+/- 11)
test benchmark::bench_vec__64 ... bench: 735 ns/iter (+/- 19)
test benchmark::bench_vec_128 ... bench: 1,634 ns/iter (+/- 49)
test benchmark::bench_vec_256 ... bench: 4,774 ns/iter (+/- 103)
test benchmark::bench_vec_512 ... bench: 15,306 ns/iter (+/- 250)
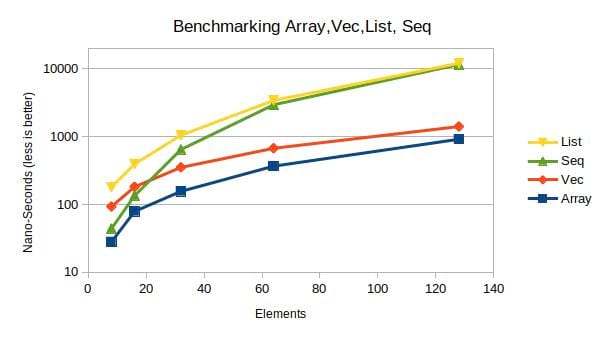
Seq 的每个元素都会因为判别器和尾部的引用而造成约 16 字节的开销。
结论
这些基准测试表明,集合 Seq 对于 16 个元素或更少的情况,性能优于 Vec,而对于 64 个元素或更少的情况,性能甚至优于 LinkedList。在此范围内,Seq 受益于栈内存。当 N>64 时,性能下降,可能是由于页面错误和需要从操作系统请求新的内存页造成的。