26个版本
| 新 0.7.8 | 2024年8月21日 |
|---|---|
| 0.7.3 | 2024年7月21日 |
#837 在 数据库接口
每月773次下载
75KB
1.5K SLoC
Aio数据库
具有极简API的全功能数据库
特性
- 自动迁移:如果结构体中引入了额外的字段或字段减少,数据库模式会立即更新。
- 本地或内存能力:所有功能都在本地存储或内存系统中操作。
- 完全实现CRUD功能
- 高性能:提供非常好的性能,初步测试显示,我所使用的两个主要库(libsql和bevy_reflect)以及我的库的额外开销非常小,几乎可以忽略不计,逐行读取1000行数据耗时28毫秒。
- 与Tokio的异步支持
- 由于内部连接池,高度并发
- ORM-like API,使用简单
- 任何地方使用
- 支持以下Rust类型:
bool、u8、u16、u32、u64、i8、i16、i32、i64、char、String和Vec<u8> - 支持创建和删除唯一索引
生产就绪
此产品已在相关公司用于特定用例的生产环境中使用。尽管已修复已知问题,但使用此产品进行生产使用需自行承担风险。
计划中的特性
- 使用Moka缓存绕过本地存储并提高性能。
- 提供更多查询选项。
- 除了内存和本地存储驱动外,为AioDatabase实例提供更多选项。
示例
cargo.toml
[dependencies]
rs_aio_db = "0.7.8"
env_logger = "0.11.5"
tokio = "1.39.3"
bevy_reflect = "0.14.1"
serde = "1.0.208"
main.rs
use rs_aio_db::db::aio_query::{Next, Operator, QueryBuilder};
use rs_aio_db::db::aio_database::AioDatabase;
use rs_aio_db::Reflect;
#[derive(Default, Clone, Debug, Reflect)]
pub struct Person {
pub name: String,
pub age: i32,
pub height: i32,
pub married: bool,
pub some_blob: Vec<u8>
}
#[derive(Serialize, Deserialize)]
struct AnotherStruct {
pub data_1: i32,
pub data_2: f64,
pub data_3: HashMap<String, String>
}
#[tokio::main]
async fn main() {
std::env::set_var("RUST_LOG", "debug");
env_logger::init();
//Locally persisted database
let file_db = AioDatabase::create::<Person>("G:\\".into(), "Test".into(), 15).await;
//In-Memory database
let in_memory_db = AioDatabase::create_in_memory::<Person>("Test".into(), 15).await;
let mut hash_map = HashMap::new();
hash_map.insert("Key1".into(), "Value1".into());
//Use AioDatabase::get_struct to get back your struct data type
file_db.insert_value(&Person {
name: "Mylo".into(),
age: 0,
height: 0,
married: true,
some_blob: AioDatabase::get_bytes(AnotherStruct {
data_1: 5,
data_2: 10.4,
data_3: hash_map.clone()
})
}).await;
let get_single_record = file_db
.query()
.field("age")
.where_is(Operator::Gt(5.to_string()), Some(Next::Or))
.field("name")
.where_is(Operator::Eq("Mylo".into()), None)
.get_single_value::<Person>()
.await
.unwrap_or_default();
println!("Record result: {:?}", get_single_record);
let get_records = file_db
.query()
.field("age")
.where_is(Operator::Gt(5.to_string()), Some(Next::Or))
.field("name")
.where_is(Operator::Eq("Mylo".into()), None)
.get_many_values::<Person>().await;
println!("Record results: {:?}", get_records);
let update_rows = file_db
.query()
.field("age")
.where_is(Operator::Eq((0).to_string()), Some(Next::Or))
.update_value(Person {
name: "Mylo".into(),
age: 5,
height: 5,
married: false,
some_blob: AioDatabase::get_bytes(AnotherStruct {
data_1: 5,
data_2: 10.4,
data_3: hash_map.clone()
})
}).await;
println!("Updated rows: {:?}", update_rows);
let partial_update_rows = file_db
.query()
.field("age")
.where_is(Operator::Eq((0).to_string()), Some(Next::Or))
.partial_update::<Person>("height".into(), "50".into()).await;
println!("Updated rows: {:?}", partial_update_rows);
let delete_rows = file_db
.query()
.field("name")
.where_is(Operator::Eq("Mylo".into()), None)
.delete_value::<Person>().await;
let contains = file_db
.query()
.field("name")
.where_is(Operator::Contains("Mylo".into()), None)
.get_single_value::<Person>()
.await
.unwrap_or_default();
println!("Contains: {:?}", contains);
let starts_with = file_db
.query()
.field("name")
.where_is(Operator::StartsWith("Mylo".into()), None)
.get_single_value::<Person>()
.await
.unwrap_or_default();
println!("Starts with: {:?}", starts_with);
let starts_with = file_db
.query()
.field("name")
.where_is(Operator::EndsWith("Mylo".into()), None)
.get_single_value::<Person>()
.await
.unwrap_or_default();
println!("Ends with: {:?}", starts_with);
_ = file_db.create_unique_index::<Person>("name_unique", vec!["name".into()]).await;
_ = file_db.drop_index("name_unique").await;
}
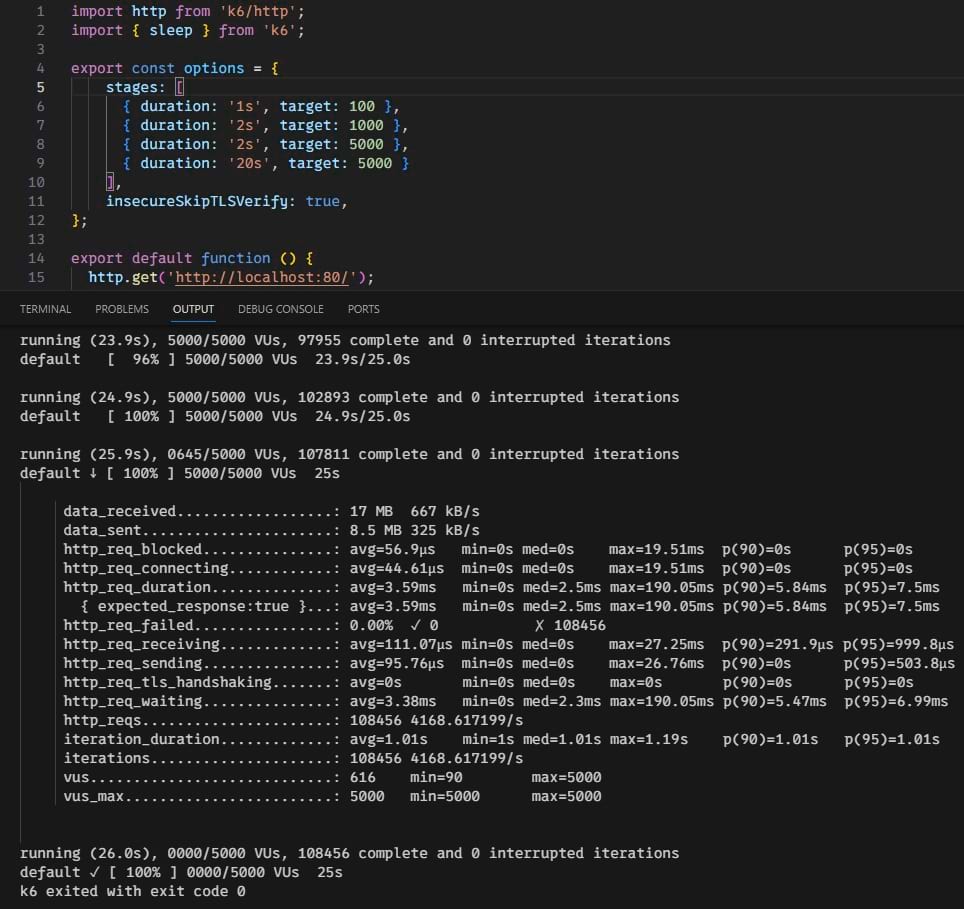
基准测试
图1

图2
说明
第一张图片: 这4个基准测试都是同步进行的。同步执行每个测试1000次的目的,是为了观察我的库对libsql和bevy_reflect的额外开销。从第3次测试的结果来看,并不大(28ms)。检索1行数据平均耗时0.0028ms或28us,这是很快的。我们不要忘记SSD本身的延迟以及Sqlite引擎的延迟,这无疑会给结果增加更多的因素。当执行第一和第二次测试场景时,我的SSD达到了21.1ms的延迟和90%的使用率,这一定是1000行插入和行更新需要3+秒的原因。目前正在调查中。
第二张图片: 图片显示了在actix-web + AioDatabase配置上运行的K6的结果。它以15个池大小在5000个并发连接上表现惊人。背后代码可以在仓库中的/example文件夹中找到。
依赖项
~8–16MB
~194K SLoC