5个版本
| 0.2.1 | 2023年2月17日 |
|---|---|
| 0.2.0 | 2022年8月31日 |
| 0.1.2 | 2021年5月30日 |
| 0.1.1 | 2021年5月23日 |
| 0.1.0 | 2021年5月20日 |
#72 in 内存管理
每月下载量 12,049
用于 2 crates
170KB
2.5K SLoC
rlsf
![]()
此crate实现了TLSF(二级隔离适配)动态内存分配算法¹。需要Rust 1.61.0或更高版本。
-
分配和释放操作保证以常数时间完成。 TLSF适用于实时应用程序。
-
快速且小巧。 你可以同时拥有这两者。它被发现比大多数
no_std兼容的分配器crate更小、更快²。 -
接受任何类型的内存池。 低级类型
Tlsf仅将你提供的任何内存池(例如,一个static数组)分割以供分配请求使用。高级类型GlobalTlsf会自动使用支持系统上的标准方法获取内存页。 -
此crate支持
#![no_std]。 它可以用于裸机以及基于RTOS的应用程序。
¹ M. Masmano, I. Ripoll, A. Crespo和J. Real, "TLSF:用于实时系统的新动态内存分配器," 第16届欧姆尼微实时系统会议论文集,2004. ECRTS 2004.,意大利卡塔尼亚,2004年,第79-88页,doi: 10.1109/EMRTS.2004.1311009。
² 使用FarCri.rs在STM32F401微控制器上编译并测量。
性能测量
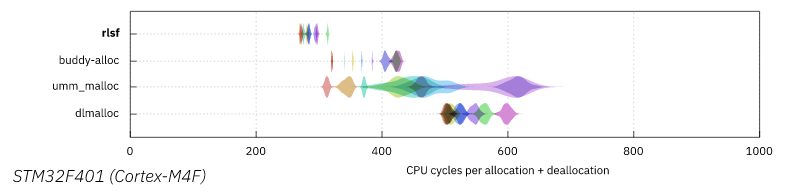
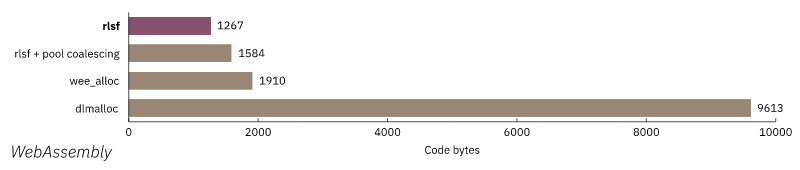
缺点
-
它不支持并发访问。 整个池必须被锁定以进行分配和释放。如果你使用FIFO锁来保护池,最坏情况下的执行时间将是
O(num_contending_threads)。如果你希望在高度并发环境中实现最大吞吐量,应考虑使用线程缓存内存分配器(例如,TCMalloc、jemalloc)。 -
使用恒定时间查找的隔离空闲列表会导致与空闲块大小成比例的内部碎片。
SLLEN参数允许调整空闲列表数量和碎片程度之间的权衡。 -
对小分配没有特殊处理(所有大小使用同一算法)。 这可能会导致与 glibc 和 jemalloc 等现代可扩展内存分配器相比,在分配密集型应用程序中效率低下。
示例
Tlsf: 核心API
use rlsf::Tlsf;
use std::{mem::MaybeUninit, alloc::Layout};
let mut pool = [MaybeUninit::uninit(); 65536];
// On 32-bit systems, the maximum block size is 16 << FLLEN = 65536 bytes.
// The worst-case internal fragmentation is (16 << FLLEN) / SLLEN - 2 = 4094 bytes.
// `'pool` represents the memory pool's lifetime (`pool` in this case).
let mut tlsf: Tlsf<'_, u16, u16, 12, 16> = Tlsf::new();
// ^^ ^^ ^^
// | | |
// 'pool | SLLEN
// FLLEN
tlsf.insert_free_block(&mut pool);
unsafe {
let mut ptr1 = tlsf.allocate(Layout::new::<u64>()).unwrap().cast::<u64>();
let mut ptr2 = tlsf.allocate(Layout::new::<u64>()).unwrap().cast::<u64>();
*ptr1.as_mut() = 42;
*ptr2.as_mut() = 56;
assert_eq!(*ptr1.as_ref(), 42);
assert_eq!(*ptr2.as_ref(), 56);
tlsf.deallocate(ptr1.cast(), Layout::new::<u64>().align());
tlsf.deallocate(ptr2.cast(), Layout::new::<u64>().align());
}
GlobalTlsf: 全局分配器
GlobalTlsf 会通过平台特定的机制自动获取内存页面。即使系统支持,它也不支持将内存页面返回给系统。
#[cfg(all(target_arch = "wasm32", not(target_feature = "atomics")))]
#[global_allocator]
static A: rlsf::SmallGlobalTlsf = rlsf::SmallGlobalTlsf::new();
let mut m = std::collections::HashMap::new();
m.insert(1, 2);
m.insert(5, 3);
drop(m);
详细信息
与原始算法的变更
- 每个内存池的末尾由一个哨兵块(一个永久占用的块)而不是带有池中最后一个块的标志的正常块进行标记。这稍微简化了代码,并提高了其最坏情况性能和代码大小。
Cargo 功能
unstable: 启用免于 API 稳定性保证的实验性功能。
许可证
MIT/Apache-2.0
依赖关系
~1.7–3.5MB
~65K SLoC