3个版本 (重大更新)
| 0.3.0 | 2023年3月18日 |
|---|---|
| 0.2.0 | 2023年3月18日 |
| 0.1.0 | 2023年3月18日 |
#1176 在 命令行工具
每月110次下载
485KB
7.5K SLoC
RLLaMA
这是我尝试在纯Rust CPU实现上使LLaMA语言模型工作的尝试。我受到了这里一个令人惊叹的CPU实现的启发:[https://github.com/ggerganov/ggml](https://github.com/ggerganov/ggml),它可以运行GPT-J 6B模型。
当前性能如下
Pure Rust implementations:
LLaMA-7B: AMD Ryzen 3950X: 552ms / token f16 (pure Rust)
LLaMA-7B: AMD Ryzen 3950X: 1008ms / token f32 (pure Rust)
LLaMA-13B: AMD Ryzen 3950X: 1029ms / token f16 (pure Rust)
LLaMA-13B: AMD Ryzen 3950X: 1930ms / token f32 (pure Rust)
LLaMA-30B: AMD Ryzen 5950X: 2112ms / token f16 (pure Rust)
OpenCL (all use f16):
LLaMA-7B: AMD Ryzen 3950X + OpenCL GTX 3090 Ti: 247ms / token (OpenCL on GPU)
LLaMA-7B: AMD Ryzen 3950X + OpenCL Ryzen 3950X: 680ms / token (OpenCL on CPU)
LLaMA-13B: AMD Ryzen 3950X + OpenCL GTX 3090 Ti: <I ran out of GPU memory :(>
LLaMA-13B: AMD Ryzen 3950X + OpenCL Ryzen 3950X: 1232ms / token (OpenCL on CPU)
LLaMA-30B: AMD Ryzen 5950X + OpenCL Ryzen 5950X: 4098ms / token (OpenCL on CPU)
(滚动到页面底部查看随时间变化的基准测试)。
我没有尝试运行LLaMA-60B,但我想如果有一台足够大的计算机,它应该会工作。
它还包含一个理解PyTorch使用的.pth文件的Python unpickler。几乎是这样,它不会自动解压缩它们(见下文)。
实现使用AVX2,即使在OpenCL代码路径中也是如此,因此目前只能在AMD64上运行。
Crates.io Cargo包安装
截至2023年3月18日,rllama位于crates.io。您可以使用以下命令安装它:`cargo install rllama`。您可能需要显式启用AVX2功能
RUSTFLAGS="-C target-feature=+sse2,+avx,+fma,+avx2" cargo install rllama
此仓库中有一个.cargo/config.toml,如果您从Git仓库手动安装,它将启用这些功能。
如何运行
您需要Rust。请确保您可以从命令行运行cargo。特别是,这个版本使用不稳定的功能,因此您需要nightly rust。确保如果您运行`cargo --version`,它显示是nightly Rust。
您需要下载LLaMA-7B权重。请参阅[https://github.com/facebookresearch/llama/](https://github.com/facebookresearch/llama/)
一旦您有了7B权重,以及它附带的tokenizer.model,您需要将其解压缩。
$ cd LLaMA
$ cd 7B
$ unzip consolidated.00.pth
# For LLaMA-7B, rename consolidated to consolidated.00
# For the larger models, the number is there already so no need to do this step.
$ mv consolidated consolidated.00
然后您应该准备好生成一些文本了。
cargo run --release -- --tokenizer-model /path/to/tokenizer.model --model-path /path/to/LLaMA/7B --param-path /path/to/LLaMA/7B/params.json --prompt "The meaning of life is"
默认情况下,它将使用源文件中精度的权重。您可以使用 --f16 命令行参数将最大的权重矩阵转换为 float16。此外,使用 OpenCL 也会将权重矩阵转换为 float16。
您可以使用 --temperature、--top-p 和 --top-k 来调整标记采样器设置。
存在 --repetition-penalty 设置。1.0 表示无惩罚。此值可能应在 0 和 1 之间。小于 1.0 的值会通过 x*(repetitition_penalty^num_occurrences) 对上下文中出现的标记施加惩罚,在应用 softmax() 到输出概率之前。换句话说,小于 1.0 的值应用惩罚。
您还可以使用 --prompt-file 从文件而不是从命令行读取提示。
如何开启 OpenCL
使用 opencl Cargo 功能。
cargo run --release --features opencl -- --tokenizer-model /path/to/tokenizer.model --model-path /path/to/LLaMA/7B --param-path /path/to/LLaMA/7B/params.json --prompt "The meaning of life is"
在 opencl 功能下,还有一个参数 --opencl-device,它接受一个数字。该数字选择系统上找到的第 N 个 OpenCL 设备。您可以在运行程序时看到设备(例如,参见下面的截图)。
截图
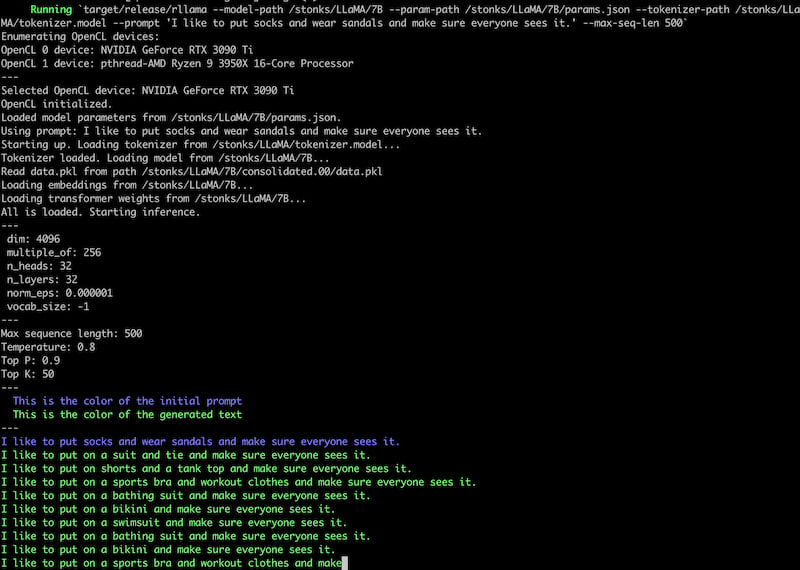
注意事项和未来计划
这对我来说是一个爱好项目,所以不要期待更新或帮助。
- 一些其他 CPU 实现使用量化来减小权重的大小,并且通常可以大大加快速度。
rllama没有这个。 - 我听说在 nVidia GPU 上有一些称为 Tensor Cores 的东西。无法通过 OpenCL 访问。但可能在 Vulkan 中通过一个扩展来访问。
- 更复杂的标记采样。我在 Hackernews 上看到一些评论说 Facebook 参考代码中包含的采样器有点垃圾,您可以通过良好的默认设置和重复惩罚等因素获得更好的结果。
- 由于程序需要通过初始提示,因此存在初始启动时间。我不知道这个启动时间是否可以完全消除,但它可以缓存在磁盘上。例如,使用标准提示来启动文本生成,您将多次重用它。
- 斯坦福发布了一些 instruct-finetuned LLaMA-7B,一旦我找到权重,我想尝试制作一个类似聊天的命令行界面。
基准测试
我正在尝试跟踪这个是否变得更快而不是更慢。
对于 50 长度的序列生成
cargo run --release --
--model-path /LLaMA/13B \
--param-path /LLaMA/13B/params.json \
--tokenizer-path /LLaMA/tokenizer.model \
--prompt "Computers are pretty complica" --max-seq-len 50
# commit c9c861d199bd2d87d7e883e3087661c1e287f6c4 (13 March 2023)
LLaMA-7B: AMD Ryzen 3950X: 1058ms / token
LLaMA-13B: AMD Ryzen 3950X: 2005ms / token
# commit 63d27dba9091823f8ba11a270ab5790d6f597311 (13 March 2023)
# This one has one part of the transformer moved to GPU as a type of smoke test
LLaMA-7B: AMD Ryzen 3950X + OpenCL GTX 3090 Ti: 567ms / token
LLaMA-7B: AMD Ryzen 3950X + OpenCL Ryzen 3950X: 956ms / token
LLaMA-13B: AMD Ryzen 3950X + OpenCL GTX 3090 Ti: 987ms / token
LLaMA-13B: AMD Ryzen 3950X + OpenCL Ryzen 3950X: 1706ms / token
# commit 35b0c372a87192761e17beb421699ea5ad4ac1ce (13 March 2023)
# I moved some attention stuff to OpenCL too.
LLaMA-7B: AMD Ryzen 3950X + OpenCL GTX 3090 Ti: 283ms / token
LLaMA-7B: AMD Ryzen 3950X + OpenCL Ryzen 3950X: 679ms / token
LLaMA-13B: AMD Ryzen 3950X + OpenCL GTX 3090 Ti: <ran out of GPU memory>
LLaMA-13B: AMD Ryzen 3950X + OpenCL Ryzen 3950X: 1226ms / token
# commit de5dd592777b3a4f5a9e8c93c8aeef25b9294364 (15 March 2023)
# The matrix multiplication on GPU is now much faster. It didn't have that much
# effect overall though, but I got modest improvement on LLaMA-7B GPU.
LLaMA-7B: AMD Ryzen 3950X + OpenCL GTX 3090 Ti: 247ms / token
LLaMA-7B: AMD Ryzen 3950X + OpenCL Ryzen 3950X: 680ms / token
LLaMA-13B: AMD Ryzen 3950X + OpenCL GTX 3090 Ti: <ran out of GPU memory>
LLaMA-13B: AMD Ryzen 3950X + OpenCL Ryzen 3950X: 1232ms / token
LLaMA-30B: AMD Ryzen 5950X + OpenCL Ryzen 5950X: 4098ms / token
# commit 3d0afcf24309f28ec540ed7645c35400a865ad6f
# I've been focusing on making the ordinary non-OpenCL CPU implementation
# faster and I got some gains, most importantly from multithreading.
# There is Float16 support now, so I've added f16/f32 to these tables:
LLaMA-7B: AMD Ryzen 3950X: 552ms / token f16
LLaMA-7B: AMD Ryzen 3950X: 1008ms / token f32
LLaMA-13B: AMD Ryzen 3950X: 1029ms / token f16
LLaMA-13B: AMD Ryzen 3950X: 1930ms / token f32
LLaMA-30B: AMD Ryzen 5950X: 2112ms / token f16
依赖项
~7–19MB
~224K SLoC