5 个版本
| 0.1.4 | 2023年11月21日 |
|---|---|
| 0.1.3 | 2023年11月16日 |
| 0.1.2 | 2023年11月13日 |
| 0.1.1 | 2023年11月13日 |
| 0.1.0 | 2023年11月8日 |
427 在 数据结构 中
每月下载量 32
175KB
1.5K SLoC
reconcile-rs
![]()
![]()
![]()
![]()
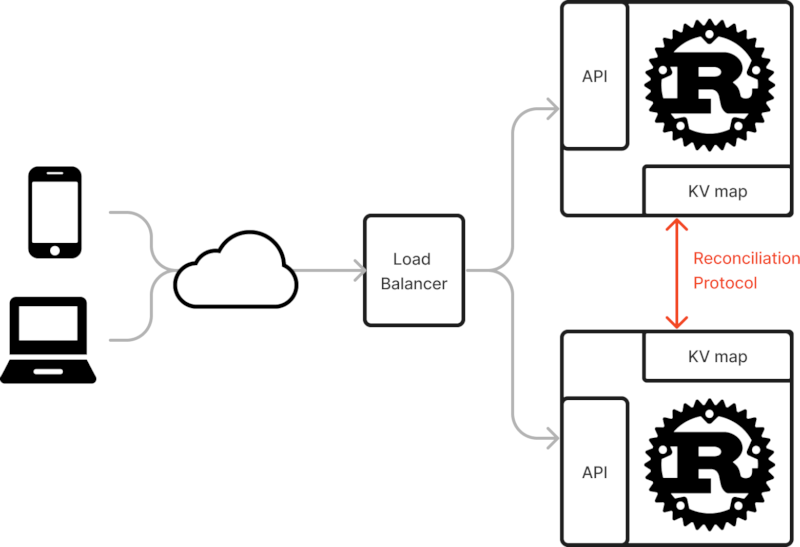
此 crate 提供了一个键值映射结构 HRTree,它可以与协调 Service 一起使用。不同的实例可以通过 UDP 通信,以高效地协调它们之间的差异。
所有数据都存储在所有实例的本地,用户可以通过插入钩子接收集合更改的通知。
该协议允许通过有限的往返次数在数百万个元素中查找差异。它还应该能够从其他实例中从头开始填充实例。
预期用途是一个可扩展的 Web 服务,具有非持久性和最终一致性的键值存储。该设计通过避免使用 Redis 等外部服务引起的任何延迟,从而实现高性能。
在代码中,它看起来像这样
let tree = HRTree::new();
let mut service = Service::new(tree, port, listen_addr, peer_net).await;
tokio::spawn(service.clone().run());
// use the reconciliation service as a key-value store in the API
HRTree
该协议的核心是由 HRTree(哈希范围树)数据结构实现的,它允许 O(log(n)) 访问、插入和删除,以及 O(log(n)) 累计哈希范围查询。后者属性使得查询两个键之间的所有键值对的累计(XORed)哈希值成为可能。
尽管我们独立提出了这个想法,但它与 2023 年 2 月在 Arxiv 上发表的一篇论文完全匹配:Aljoscha Meyer 的《基于范围的集合协调》:Range-Based Set Reconciliation。
我们实现此数据结构基于我们自己编写的 B-Tree。尽管我们在这个方面投入了有限的精力,没有使用 unsafe,并需要维护更多的不变量,但我们的性能仍然在标准库中的 BTreeMap 的 2 倍范围内。
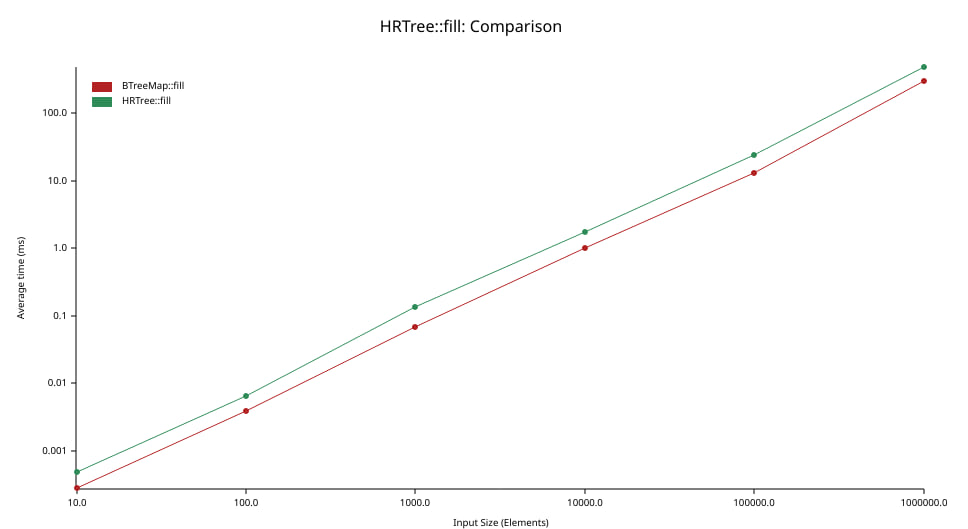
上图显示了将N个元素插入树(初始为空)所需的时间(单位:毫秒)(纵坐标,左侧坐标轴)。注意,两个坐标轴都使用对数刻度。
我们《HRTree》实现的性能与《BTreeMap》非常接近。观察每个N值,我们发现《HRTree》的平均吞吐量是《BTreeMap》的三分之一到一半。
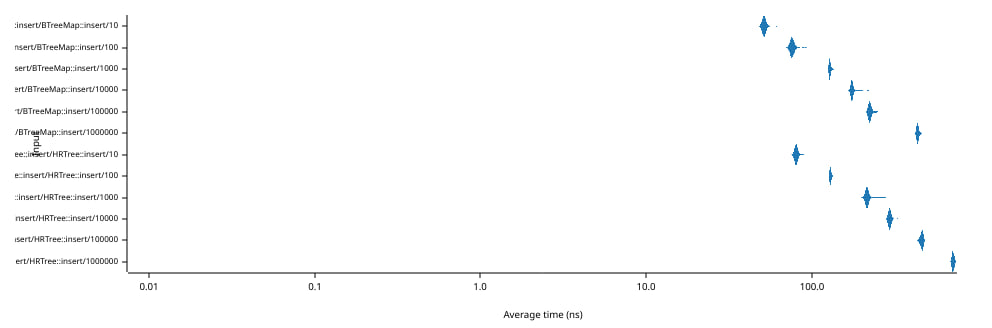
上图显示了将单个元素(及其删除)插入包含N个元素的树所需的时间(单位:纳秒)(横坐标,底部坐标轴)。注意,两个坐标轴都使用对数刻度。
值得注意的是,平均插入/删除时间仅从80纳秒增长到700秒,尽管树的规模从10增长到100万个元素。
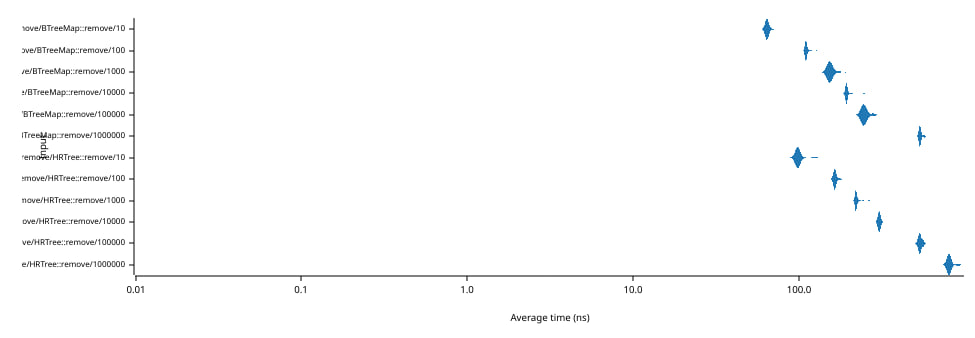
上图显示了从包含N个元素的树中删除单个元素(及其恢复)所需的时间(单位:纳秒)(横坐标,底部坐标轴)。注意,两个坐标轴都使用对数刻度。
值得注意的是,平均删除/插入时间仅从100纳秒增长到800秒,尽管树的规模从10增长到100万个元素。
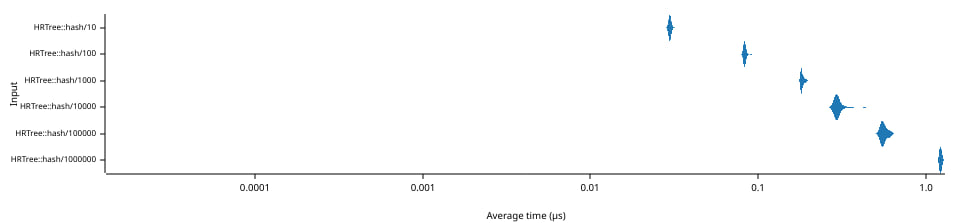
上图显示了在大小为N的树中对随机范围元素计算1个累积哈希所需的时间(单位:微秒)(横坐标,底部坐标轴)。注意,两个坐标轴都使用对数刻度。
随着树的规模从10增长到100万个元素,累积哈希的平均时间从30纳秒增长到1,200纳秒。
尽管在《HRTree》的性能方面可能还有很大的改进空间,但对于我们的目的来说已经足够,因为我们预计网络延迟会大得多。
服务
该服务利用《HRTree》的特性,在两个实例的集合中执行类似于二分搜索的搜索。一旦找到差异,就交换相应的键值对并解决冲突。
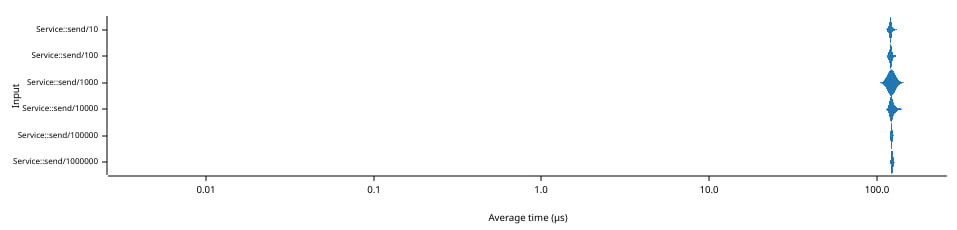
上图显示了在包含相同N个元素的《Service》的两个实例之间发送1个插入操作,然后是1个删除操作所需的时间(单位:微秒)(横坐标,左侧坐标轴)。注意,两个坐标轴都使用对数刻度。
时间非常稳定,大约在122微秒左右,这表明协调时间完全受本地网络传输限制。这是由于在插入/删除时立即传输元素而实现的。
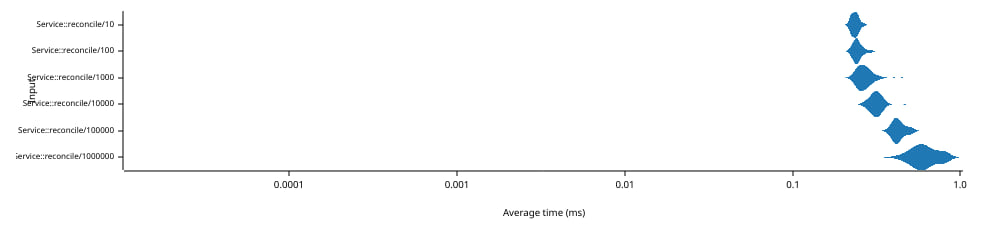
上图显示了在包含相同其他N个元素的《Service》的两个实例之间协调1个插入操作,然后是1个删除操作所需的时间(单位:毫秒)(横坐标,左侧坐标轴)。注意,两个坐标轴都使用对数刻度。
这次,必须运行完整的协调协议来识别差异。随着集合规模的增加,时间从240微秒增长到640微秒。
注意:这些基准测试是在本地回环网络接口上执行的。在实际网络上,传输延迟会使这些值更大。
依赖关系
~167K
~167K SLoC