4 个版本 (2 个破坏性版本)
使用旧的 Rust 2015
| 0.3.0 | 2019 年 8 月 23 日 |
|---|---|
| 0.2.1 | 2018 年 2 月 21 日 |
| 0.2.0 | 2018 年 2 月 21 日 |
| 0.1.0 | 2017 年 11 月 9 日 |
在 机器学习 中排名 #283
77KB
871 行
random-world 

这是《随机世界中的算法学习》(ALRW)一书中介绍的机器学习(ML)方法(例如,一致性预测器)及其相关方法的 Rust 实现,同时提供独立的二进制程序。
目标
以下是该库的主要目标。
- 快速实现 ALRW 书中描述的方法
- 有良好的文档记录
- 提供独立的二进制程序
- CP 方法应该能够使用现有 ML 库(例如,rusty-machine、rustlearn)中的评分分类器
- 易于与其他语言(例如 Python)接口
二进制程序
独立的二进制程序旨在涵盖库的大多数功能。它们在 .csv 文件上运行,并允许进行 CP 预测、测试可交换性等。
安装
要安装二进制程序,请安装 Rust 的包管理器 cargo。然后运行
$ cargo install random-world
这将安装系统上的二进制程序: cp-predict、icp-predict 和 martingales。
cp-predict
cp-predict 允许进行 批处理 和 在线 CP 预测。它在一个训练集上运行 CP,并使用它来预测一个测试集;每个数据集应包含一个 CSV 文件,其中包含行
label, x1, x2, ...
其中 label 是标签 ID,x1、x2、... 是构成特征向量的值。标签 ID 需要是 0, 1, ..., n_labels-1(即没有缺失值);如果初始训练数据中(例如在线模式中)不是所有标签都可用,则可以指定 --n-labels。
结果以 CSV 文件的形式返回,其中包含行
p1, p2, ...
其中每个值要么是预测(真/假)或 p 值([0,1] 区间的浮点数),具体取决于传递给 cp-predict 的标志;每一行包含每个标签的值。
示例
$ cp-predict knn -k 1 predictions.csv train_data.csv test_data.csv
在 train_data.csv 上运行 CP,使用非一致性度量 k-NN(k=1),预测 test_data.csv,并将输出存储到 predictions.csv。默认输出是 p 值;要输出实际预测,请使用 --epsilon 指定显著性水平。
要在数据集上以在线模式运行 CP(即每次预测一个对象并将其附加到训练示例中),只需指定训练文件
$ cp-predict knn -k 1 predictions.csv train_data.csv
更多选项在帮助文档中有说明
$ cp-predict -h
Predict data using Conformal Prediction.
If no <testing-file> is specified, on-line mode is assumed.
Usage: cp knn [--knn=<k>] [options] [--] <output-file> <training-file> [<testing-file>]
cp kde [--kernel<kernel>] [--bandwidth=<bw>] [options] [--] <output-file> <training-file> [<testing-file>]
cp (--help | --version)
Options:
-e, --epsilon=<epsilon> Significance level. If specified, the output are
label predictions rather than p-values.
-s, --smooth Smooth CP.
--seed=<s> PRNG seed. Only used if --smooth set.
-k, --knn=<kn> Number of neighbors for k-NN [default: 5].
--n-labels=<n> Number of labels. If specified in advance it
slightly improves performances.
-h, --help Show help.
--version Show the version.
icp-predict
icp-predict 的语法目前与 cp-predict 相同:校准集的大小选择为训练集大小的一半。这将会改变(希望很快)。
martingales
从包含 p 值的文件中计算可交换的鞅。p 值应在单个标签问题的在线环境中使用 cp-predict 计算。
$ martingales -h
Test exchangeability using martingales.
Usage: martingales plugin [--bandwidth=<bw>] [options] <output-file> <pvalues-file>
martingales power [--epsilon=<e>] [options] <output-file> <pvalues-file>
martingales (--help | --version)
Options:
--seed PRNG seed.
-h, --help Show help.
--version Show the version.
示例
查看 examples/non-iid.csv
0,1.77750,-0.84078
0,-1.68787,3.86305
0,-0.56455,0.17416
0,-0.86380,0.39916
...
这些代表异常时间序列数据,人工生成以作为此代码的示例;不要使用 它作为异常检测基准:它将几乎没有用处。每行包含一个标签(始终设置为 0,这是在下一步计算鞅所必需的),和一个向量。这些数据包含 200 个示例:前 100 个是根据以 [0, 0] 为中心的多元正态分布生成的,并且协方差矩阵为 [5, 5]。因此,“异常”部分的数据是在 100 个示例之后开始的。
要产生马丁格尔
# Use CP in on-line mode
cp-predict knn -k 1 pvalues.csv examples/non-iid.csv
# Martingales
martingales plugin --bandwidth=0.2 martingales.csv pvalues.csv
看看 martingales/martingales.csv:它现在应包含马丁格尔值,每行一个。你可以调用任何超过阈值的马丁格尔值(例如,20 或 100)。这里是这个特定示例的马丁格尔值。
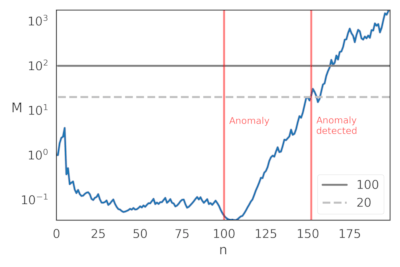
以 20 为阈值,异常大约在 50 个示例之后发生。
图书馆
为了充分利用所有功能或将其集成到您的项目中,您可能需要使用实际库。
在 Cargo.toml 中包含以下内容
[dependencies]
random-world = "0.2.1"
快速入门
使用具有 k-NN 非一致性度量(k=2)和显著性水平 epsilon=0.3 的确定性(即非光滑)一致预测器。预测区域将包含正确标签的概率为 1-epsilon。
#[macro_use(array)]
extern crate ndarray;
extern crate random_world;
use random_world::cp::*;
use random_world::ncm::*;
// Create a k-NN nonconformity measure (k=2)
let ncm = KNN::new(2);
// Create a Conformal Predictor with the chosen nonconformity
// measure and significance level 0.3.
let mut cp = CP::new(ncm, Some(0.3));
// Create a dataset
let train_inputs = array![[0., 0.],
[1., 0.],
[0., 1.],
[1., 1.],
[2., 2.],
[1., 2.]];
let train_targets = array![0, 0, 0, 1, 1, 1];
let test_inputs = array![[2., 1.],
[2., 2.]];
// Train and predict
cp.train(&train_inputs.view(), &train_targets.view())
.expect("Failed prediction");
let preds = cp.predict(&test_inputs.view())
.expect("Failed to predict");
assert!(preds == array![[false, true],
[false, true]]);
请参阅文档以获取更多示例。
功能
方法
- 确定性和平滑一致预测器(又称,归纳一致预测器CP)
- 确定性归纳一致预测器(ICP)
- 用于交换性测试的插件和功率鞅
- 文氏图预测器
非一致性度量
- k-NN
- KDE
- 现有库(例如 rusty-machine)的机器学习评分器通用的包装器
二进制程序
- CP(批量预测和在线)
- 鞅
- 归纳CP(仅批量预测)
绑定
- Python绑定
作者
- 乔瓦尼·切鲁宾 (giocher.com)
类似项目
- nonconformist 是 CP 和 ICP 的 Python 实现。
依赖关系
~10MB
~189K SLoC