4 个版本
| 0.1.5 | 2024年2月6日 |
|---|---|
| 0.1.4 | 2023年11月27日 |
| 0.1.3 | 2023年11月8日 |
| 0.1.2 | 2023年9月30日 |
#306 在 并发 类别中
2.5MB
4.5K SLoC
![]()
Parallelo 并行库 (PPL):在 Rust 中释放并行计算的力量
🌟 欢迎来到 Parallelo 并行库 (PPL) – 一个用 Rust 编写的简洁但强大的并行框架。🚀
Parallelo 并行库 (PPL) 是一个用 Rust 编写的正在开发中的并行框架。PPL 的主要目标是提供一种结构化的方法来在 Rust 中进行并行编程,让开发者能够释放并行性,而不必处理低级并发管理机制。PPL 通过释放并行性的巨大潜力,使您的 Rust 程序更快、更高效。无论您是在进行大规模数据处理、模拟,还是任何计算密集型任务,PPL 都能为您提供解决方案。
目录
特性
-
并行计算:使用 Parallelo 并行库 (PPL) 在 Rust 中释放并行性的全部力量。利用多个核心的潜力,使您的计算比以往任何时候都要快、更高效。
-
任务、流和数据并行性:PPL 提供了表达任务、流和数据并行性模型的工具。利用任务并行性的力量将您的计算分解成可以并行执行的小任务。处理连续数据流和并行处理结构化数据集,实现高效的数据处理和分析。
-
工作窃取线程池:PPL 包含一个工作窃取线程池,将并行执行提升到新的高度。得益于工作窃取线程池,任务会在可用的线程之间动态分配,确保负载均衡和计算资源的有效利用。这一特性提高了并行计算的效率,使您的 Rust 应用程序能够实现更优越的性能和可伸缩性。
-
高效的资源管理:在并行编程领域,最优的资源管理至关重要。PPL 允许您对资源分配进行细粒度控制,包括选择要使用的线程数量、设置线程等待策略和启用 CPU 锁定。这种程度的控制确保了硬件资源的最佳利用,从而提高了并行计算的性能和效率。
-
多种通道后端:PPL 提供了多种通道后端供您选择,以实现并行任务之间无缝的通信和协调。利用流行的通道实现,如 crossbeam-channel、flume 和 kanal。每个后端都具有其独特的性能特征、内存使用情况和功能集,让您可以根据具体需求选择最合适的后端。这些灵活的通道后端促进了并行计算中的数据流和同步。
-
灵活性和定制化:使用 PPL,您可以根据需要创建自定义节点,以表达更复杂的并行计算。这使得您可以根据精确需求调整并行流水线,创建高度可定制的并行工作流程。具有状态的节点可以存储中间结果并维护关键上下文信息,从而在计算的不同阶段之间实现高效的数据共享。这种灵活性和定制化增强了 PPL 的表达能力,让您能够处理各种并行编程场景。
-
直观的 API:无论您是经验丰富的并行计算专家还是并行计算新手,PPL 都通过其直观的 API(基于结构化并行编程)简化了并行编程。所有技能水平的开发者都可以轻松地利用 Rust 中的并行计算功能。直观的 API 确保了学习曲线平滑,让您能够轻松地并行化计算。
安装
Parallelo 并行库(PPL)目前可在 GitHub 和 Crates.io 上获取。
在继续之前,请确保您的系统上已安装 Rust 和 Cargo。如果您尚未安装它们,可以从官方 Rust 网站获取:[https://rust-lang.net.cn/tools/install](https://rust-lang.net.cn/tools/install)
要将在您的 Rust 项目中使用 PPL,您可以在 Cargo.toml 中添加以下内容
[dependencies]
ppl = { git = "https://github.com/valebes/ppl.git" }
使用
一个简单的(但很长的)示例:斐波那契流水线
以下是一个简单示例,展示了如何创建一个计算斐波那契数列前 20 项的流水线。
此流水线由以下部分组成
- 源:从 1 到 20 发出数字。
- 阶段:计算斐波那契数列的第 i 项。
- 汇:累积并返回包含结果的 Vec。
以下是一段代码片段,展示如何构建此流水线
use ppl::{prelude::*, templates::misc::{SourceIter, Sequential, SinkVec}};
fn main() {
let mut p = pipeline![
SourceIter::build(1..21),
Sequential::build(fib), // fib is a method that computes the i-th number of Fibonacci
SinkVec::build()
];
p.start();
let res = p.wait_end().unwrap().len();
assert_eq!(res, 20)
}
在这个示例中,我们构建了一个简单的流水线,为什么不使用闭包而不是库模板呢?
use ppl::prelude::*;
fn main() {
let mut p = pipeline![
{
let mut counter = 0;
move || {
if counter < 20 {
counter += 1;
Some(counter)
} else {
None
}
}
},
|input| Some(fib(input)),
|input| println!("{}", input)
];
p.start();
p.wait_end();
}
框架的运行时将调用表示源的闭包,直到它返回 None,当源返回 None 时,则将终止消息传播到流水线的其他阶段。
如果我们想并行化计算,我们必须找到算法中可以并行化的部分。在这种情况下,中间的阶段是一个很好的候选,我们通过引入一个 Farm 来复制该阶段。
现在代码如下
use ppl::{prelude::*, templates::misc::{SourceIter, Parallel, SinkVec}};
fn main() {
let mut p = pipeline![
SourceIter::build(1..21),
Parallel::build(8, fib), // We create 8 replicas of the stage seen in the previous code.
SinkVec::build()
];
p.start();
let res = p.wait_end().unwrap().len();
assert_eq!(res, 20)
}
如果我们不想使用库提供的模板,可以创建自定义阶段。通过创建自定义阶段,我们可以在我们的管道中构建具有状态的更复杂节点。
这里是一个使用自定义定义阶段的相同示例
use ppl::prelude::*;
struct Source {
streamlen: usize,
counter: usize,
}
impl Out<usize> for Source {
// This method must be implemented in order to implement the logic of the node
fn run(&mut self) -> Option<usize> {
if self.counter < self.streamlen {
self.counter += 1;
Some(self.counter)
} else {
None
}
}
}
#[derive(Clone)]
struct Worker {}
impl InOut<usize, usize> for Worker {
// This method must be implemented in order to implement the logic of the node
fn run(&mut self, input: usize) -> Option<usize> {
Some(fib(input))
}
// We can override this method to specify the number of replicas of the stage
fn number_of_replicas(&self) -> usize {
8
}
}
struct Sink {
counter: usize,
}
impl In<usize, usize> for Sink {
// This method must be implemented in order to implement the logic of the node
fn run(&mut self, input: usize) {
println!("{}", input);
self.counter += 1;
}
// If at the end of the stream we want to return something, we can do it by implementing this method.
fn finalize(self) -> Option<usize> {
println!("End");
Some(self.counter)
}
}
fn main() {
let mut p = pipeline![
Source {
streamlen: 20,
counter: 0
},
Worker {},
Sink { counter: 0 }
];
p.start();
let res = p.wait_end(); // Here we will get the counter returned by the Sink
assert_eq!(res.unwrap(), 20);
}
当然,这会更冗长,但可以表达更多样化的并行计算,其中每个节点都可以具有状态。此外,得益于这种方法,我们还可以为可以在不同管道和/或项目中重用的阶段构建模板。
Parallelo还提供了一个强大的工作窃取线程池。我们可以用以下方式表达相同的并行计算
use ppl::thread_pool::ThreadPool;
fn main() {
let tp = ThreadPool::new(); // We create a new threadpool
for i in 1..21 {
tp.execute(move || {
fib(i);
});
}
tp.wait(); // Wait till al worker have finished
}
如果我们不想显式等待线程,我们可以创建一个并行作用域。在作用域结束时,所有线程都将保证完成它们的工作。这可以通过以下代码完成
use ppl::thread_pool::ThreadPool;
fn main() {
let tp = ThreadPool::new(); // We create a new threadpool
tp.scope(|s| {
for i in 1..21 {
s.execute(move || {
fib(i);
});
}
}); // After this all threads have finished
}
一个更复杂的示例:单词计数器
为了展示Parallelo并行库(PPL)的功能,让我们考虑一个常见问题:在文本数据集中统计单词的出现次数。此示例展示了PPL如何通过利用并行性显著加快计算速度。
问题
任务是统计给定文本数据集中每个单词的出现次数。这涉及读取数据集,将其分割成单个单词,规范化单词(例如,转换为小写并删除非字母字符),最后统计每个单词的出现次数。
方法1:管道
PPL中的管道方法提供了一种直观且灵活的方式来表达复杂的并行计算。在此方法中,我们构建一个由多个阶段组成的管道,每个阶段对数据执行特定的操作。数据流经各个阶段,每个阶段自动应用并行性。
在单词计数示例中,管道涉及以下阶段
- 源:读取数据集并输出文本行。
- MapReduce:映射函数将每行文本转换为单词列表,其中每个单词都与计数值1配对。此外,reduce函数通过为每个唯一单词求和来聚合单词的计数值。
- 汇:将最终的单词计数存储在散列表中。
通过将计算分解成阶段并利用并行性,PPL的管道方法允许在多个线程或核心之间有效地分配工作,从而加快执行速度。
以下是使用管道方法进行单词计数的Rust代码
use ppl::{
templates::map::MapReduce,
prelude::*,
};
struct Source {
reader: BufReader<File>,
}
impl Out<Vec<String>> for Source {
// Implementation details...
}
struct Sink {
counter: HashMap<String, usize>,
}
impl In<Vec<(String, usize)>, Vec<(String, usize)>> for Sink {
fn run(&mut self, input: Vec<(String, usize)>) {
// Increment value for key in hashmap
// If key does not exist, insert it with value 1
for (key, value) in input {
let counter = self.counter.entry(key).or_insert(0);
*counter += value;
}
}
fn finalize(self) -> Option<Vec<(String, usize)>> {
Some(self.counter.into_iter().collect())
}
}
pub fn ppl(dataset: &str, threads: usize) {
// Initialization and configuration...
let mut p = pipeline![
Source { reader },
MapReduce::build_with_replicas(
threads / 2, // Number of worker for each stage
|str| -> (String, usize) { (str, 1) }, // Map function
|a, b| a + b, // Reduce function
2 // Number of replicas of this stage
),
Sink {
counter: HashMap::new()
}
];
p.start();
let res = p.wait_end();
}
方法2:线程池
另外,PPL还提供了一个线程池用于并行计算。在此方法中,我们利用线程池的par_map_reduce函数执行单词计数任务。
PPL中的线程池方法涉及以下步骤
- 创建具有所需线程数的线程池。
- 读取数据集并将所有行收集到一个向量中。
- 使用
par_map_reduce函数并行化对单词向量上的映射和归约操作。 - 映射操作将每个单词转换为包含计数值1的元组。
- 归约操作通过为每个唯一单词求和来聚合单词的计数值。
使用线程池,PPL有效地将工作分配到可用线程,自动管理并行执行和资源分配。
use ppl::prelude::*;
pub fn ppl_map(dataset: &str, threads: usize) {
// Initialization and configuration...
let file = File::open(dataset).expect("no such file");
let reader = BufReader::new(file);
// We can also create custom-sized thread pool
let mut tp = ThreadPool::with_capacity(threads);
let mut words = Vec::new();
reader.lines().map(|s| s.unwrap()).for_each(|s| words.push(s));
let res = tp.par_map_reduce(
words
.iter()
.flat_map(|s| s.split_whitespace())
.map(|s| {
s.to_lowercase()
.chars()
.filter(|c| c.is_alphabetic())
.collect::<String>()
})
.collect::<Vec<String>>(),
|str| -> (String, usize) { (str, 1) }, // Map function
|a, b| a + b, // Reduce function
);
}
一个高级示例:单输入多输出阶段
在此示例中,我们展示了如何使用PPL建模数据处理管道,其中每个阶段为每个接收到的输入产生多个输出。
此管道涉及以下阶段
- 源:生成1000个数字的流。
- 工作:给定一个数字,它产生该数字的多个副本。
- 汇:
SinkVec结构在管道中充当汇阶段。它收集来自工作阶段的输出并将结果存储在一个向量中。
《InOutusize, usize》特质的实现覆盖了 run 方法,用于处理从源接收到的输入并为生成多个副本准备工作者。 produce 方法生成指定数量的输入副本。通过实现 is_producer 方法并返回 true,这个阶段被标记为一个生产者。此外, number_of_replicas 方法指定了为并行处理创建此工作者的副本数量。
use ppl::{templates::misc::SinkVec, prelude::*};
// Source
struct Source {
streamlen: usize,
counter: usize,
}
impl Out<usize> for Source {
fn run(&mut self) -> Option<usize> {
if self.counter < self.streamlen {
self.counter += 1;
Some(self.counter)
} else {
None
}
}
}
// Given an input, it produces 5 copies of it.
#[derive(Clone)]
struct Worker {
number_of_messages: usize,
counter: usize,
input: usize,
}
impl InOut<usize, usize> for Worker {
fn run(&mut self, input: usize) -> Option<usize> {
self.counter = 0;
self.input = input;
None
}
// After calling the run method, the rts of the framework
// will call the produce method till a None is returned.
// After a None is returned, the node will fetch the
// next input and call the run method again.
fn produce(&mut self) -> Option<usize> {
if self.counter < self.number_of_messages {
self.counter += 1;
Some(self.input)
} else {
None
}
}
// We mark this node as a producer
fn is_producer(&self) -> bool {
true
}
fn number_of_replicas(&self) -> usize {
8
}
}
fn main() {
// Create the pipeline using the pipeline! macro
let mut p = pipeline![
Source {
streamlen: 1000,
counter: 0
},
Worker {
number_of_messages: 5,
counter: 0,
input: 0
},
SinkVec::build()
];
// Start the processing
p.start();
// Wait for the processing to finish and collect the results
let res = p.wait_end().unwrap();
}
更复杂的示例可以在 benches/、examples/ 和 tests/ 中找到。
配置
可以通过设置环境变量来自定义 Parallelo 并行库 (PPL) 的配置。以下是可以使用的环境变量
-
PPL_MAX_CORES:指定要使用的最大 CPU 数量。此配置仅在启用固定时有效。
-
PPL_PINNING:启用或禁用 CPU 固定。默认情况下,固定是禁用的 (
false)。(相当于 OpenMP 中的OMP_PROC_BIND)。 -
PPL_SCHEDULE:指定在管道中使用的方法调度。可用的选项包括
static:静态调度(轮询)(默认)。dynamic:动态调度(同一阶段的副本之间启用工作窃取)。
-
PPL_WAIT_POLICY:如果设置为
passive,则线程在等待通信或未使用时会尝试放弃其时间给其他线程。这特别适用于使用 SMT 的情况,可以提高性能。相反,如果设置为active,则线程将进行忙等待。默认情况下,此选项设置为passive。 -
PPL_THREAD_MAPPING:指定线程映射。默认情况下,线程按找到 CPU 的顺序映射。此选项仅在启用固定时有效。(注意,此环境变量类似于 OpenMP 中的
OMP_PLACES环境变量)。- 示例:
PPL_THREAD_MAPPING=0,2,1,3将按以下顺序映射线程:0 -> core 0,1 -> core 2,2 -> core 1,3 -> core 3。
- 示例:
要自定义配置,请在运行使用 PPL 的 Rust 程序之前设置所需的环境变量。例如,您可以在 shell 脚本中设置环境变量或使用工具从文件加载它们。
请注意,更改这些配置选项可能会影响并行计算的性能和行为。尝试不同的设置以找到针对您的特定用例的最佳配置。
通道后端
Parallelo 并行库 (PPL) 提供了在框架中选择用于多生产者、单消费者通信的通道后端的灵活性。根据您的需求和偏好,您可以在编译时使用功能标志选择所需的通道后端。
PPL 的默认后端是 crossbeam。
Crossbeam 提供了一个高性能的通道实现,能够高效且可靠地实现不同线程之间的通信。它非常适合广泛的并行计算场景。
总的来说,PPL 支持以下后端
要选择特定的通道后端,在构建过程中启用相应的功能标志。例如,要使用 flume 通道,将以下内容添加到您的 Cargo.toml 文件中
[dependencies]
ppl = { git = "https://github.com/valebes/ppl.git", default-features = false, features = ["flume"]}
FastFlow 通道
除了其他通道后端之外,PPL 还提供了一个基于 FastFlow 队列的实验性 mpsc 通道实现。此后端可通过 ff 功能标志使用。此实现可在 此处 找到,并且主要基于 Luca Rinaldi 的 FF Buffer。
此后端围绕一个包装 FastFlow 队列的包装器构建,该包装器提供类似通道的接口。
为了使用此实现,您必须在主目录中下载并安装 FastFlow 库。可以从 此处 或以下方式下载库
cd ~
git clone https://github.com/fastflow/fastflow.git
基准测试
基准测试文件位于 benches/ 目录中。要运行基准测试,请使用以下命令
cargo bench
要为图像处理基准测试生成数据集,请执行以下操作
cd benches/benchmarks/img/images
./generate_input.sh
可用的基准测试
-
图像处理:一个基于在 RustStreamBench 中找到的图像处理基准测试的基准测试。您可以在 此处 找到基准测试的源代码。
-
Mandelbrot 集合:计算 Mandelbrot 集合的著名迭代算法的基本并行实现。
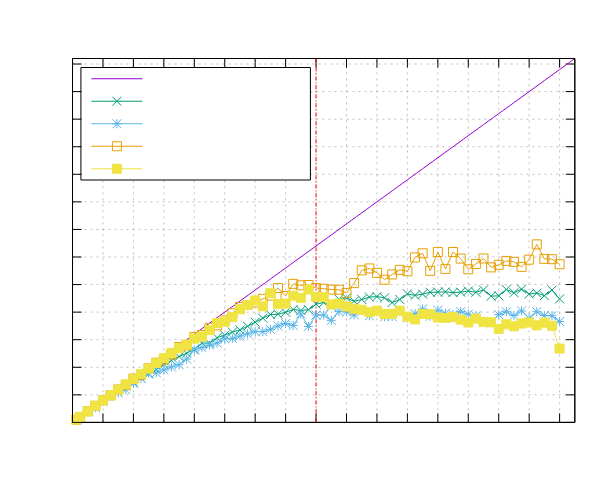
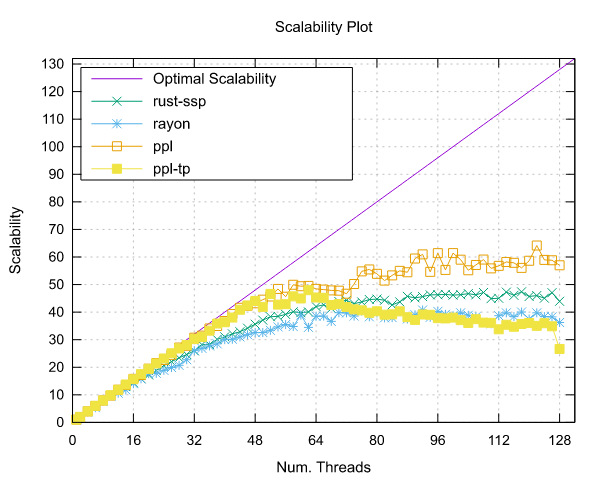
图像处理结果
以下是在运行图像处理基准测试时获得的结果。这两个基准测试都是使用 Pipeline 接口(ppl)和线程池接口(ppl-tp)实现的。
Ampere Altra (ARM)
- 处理器:2x Ampere Altra 80 核 @ 3.0GHz
- 配置:PPL 启用了固定和动态调度
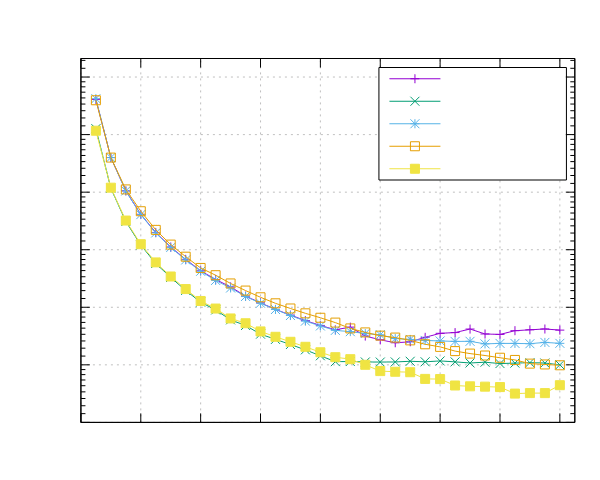 |
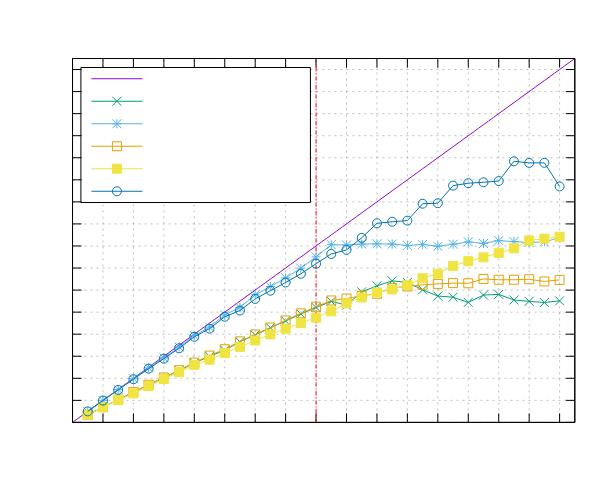 |
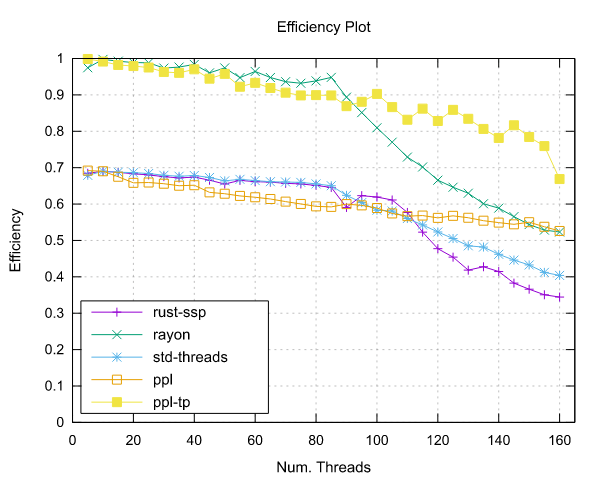 |
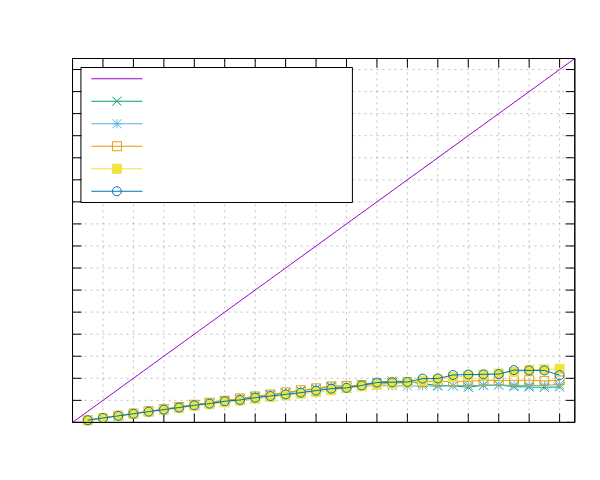 |
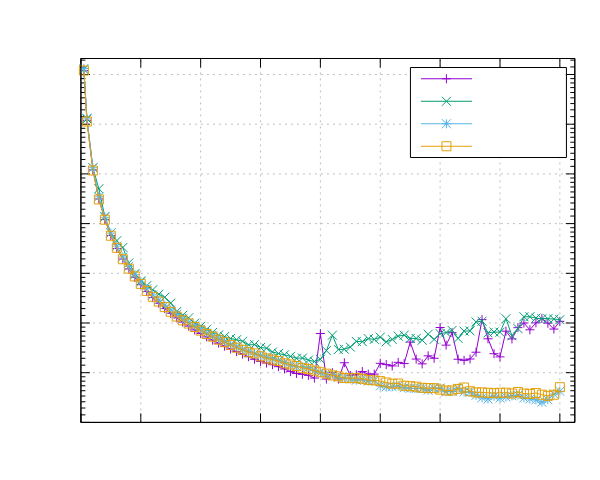
AMD EPYC 7551 (x86)
- 处理器:2x AMD EPYC 7551 32 核 @ 2.5 GHz
- 配置:PPL 启用了固定和动态调度
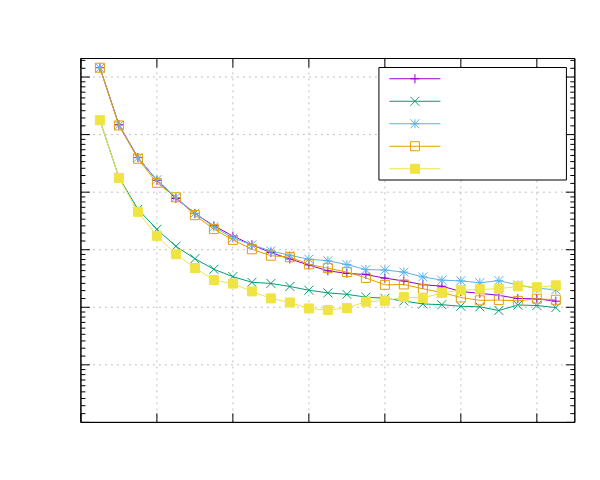 |
 |
 |
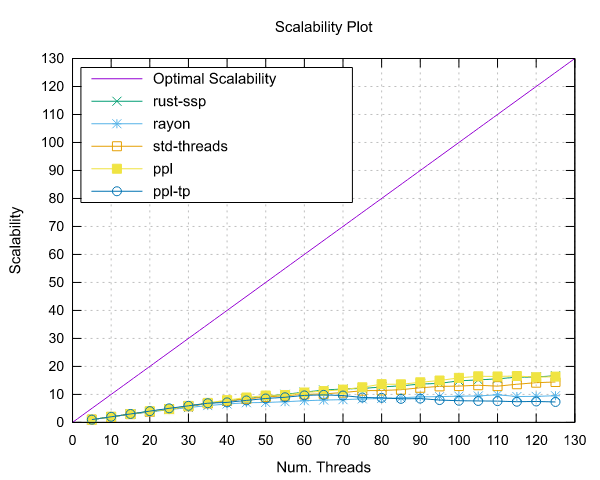 |
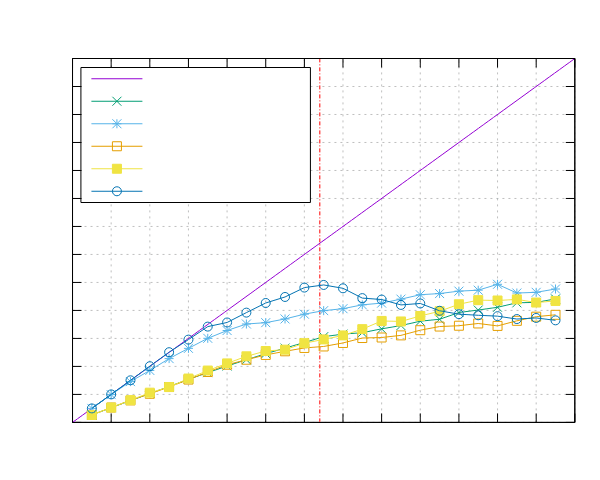
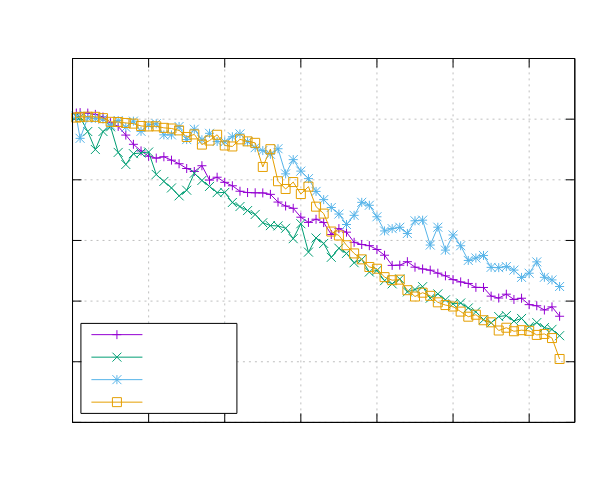
Mandelbrot 集结果
以下是在运行 Mandelbrot 集合基准测试时获得的结果。
Ampere Altra (ARM)
- 处理器:2x Ampere Altra 80 核 @ 3.0GHz
- 配置:PPL 启用了固定和动态调度
 |
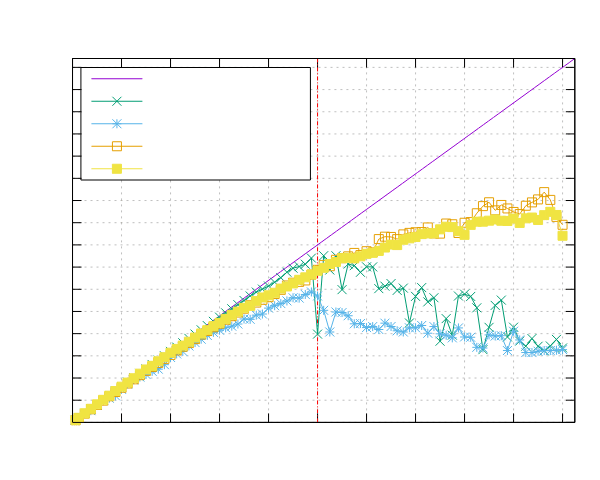 |
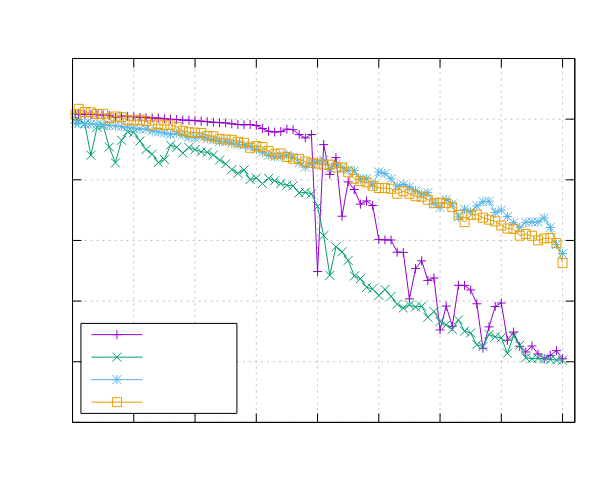 |
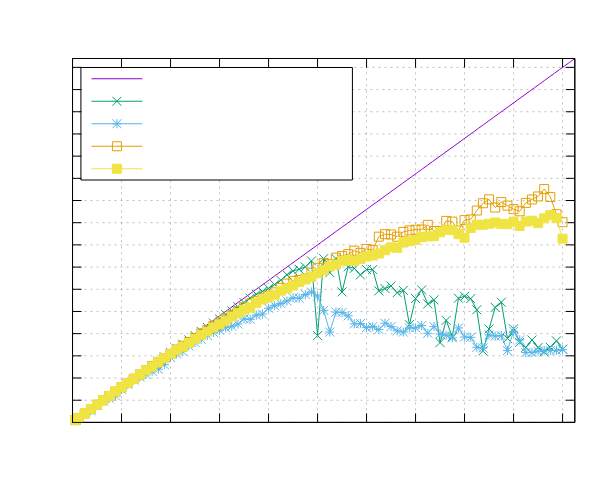 |
AMD EPYC 7551 (x86)
- 处理器:2x AMD EPYC 7551 32 核 @ 2.5 GHz
- 配置:PPL 启用了固定和动态调度
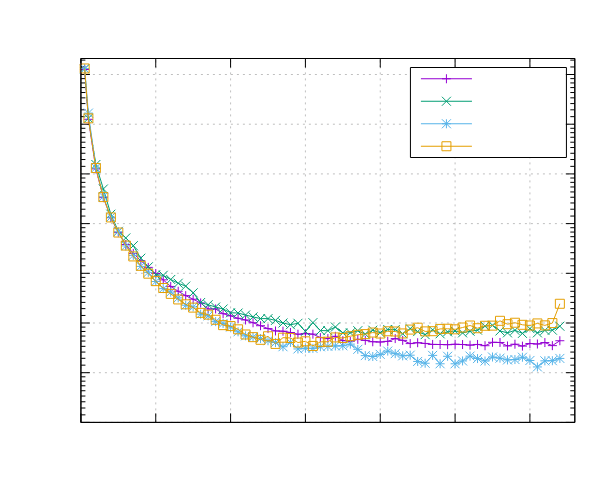 |
 |
 |
 |
贡献
感谢您考虑为 Parallelo Parallel Library (PPL) 贡献!
如果您想修复错误、提出新功能或创建新模板,我们欢迎您这样做!请在以下步骤中遵循以贡献 PPL。
行为准则
在贡献之前,请阅读我们的 行为准则。
如何贡献
-
创建问题:在开始重大更改之前,创建问题 以讨论和协调工作。
-
分支和克隆:分支仓库,然后将其克隆到您的本地计算机。
-
分支:为您的更改创建新分支。
-
更改:实现您的更改,并编写清晰的提交消息。
-
测试:添加测试以确保更改的正确性。
-
运行测试:验证所有测试是否成功通过。
-
提交拉取请求:将您的分支推送到仓库并创建一个拉取请求,引用相关的issue。
-
审查和迭代:处理反馈并做出必要的更改。
-
庆祝!🎉:一旦被批准并合并,您的贡献将成为PPL的一部分!
报告问题
要报告错误、提问或提出新想法,请创建一个issue。
警告
该库目前处于早期开发阶段。API不稳定,未来可能会发生变化。
许可
许可协议为以下之一
- Apache许可证,版本2.0(《LICENSE-APACHE》或https://apache.ac.cn/licenses/LICENSE-2.0)
- MIT许可证(《LICENSE-MIT》或https://open-source.org.cn/licenses/MIT)
任选其一。
除非您明确说明,否则根据Apache-2.0许可证定义,您有意提交以包含在工作中的任何贡献,都将如上双重许可,不附加任何额外条款或条件。