11 个版本
| 0.9.3 | 2021 年 10 月 21 日 |
|---|---|
| 0.9.2 | 2021 年 4 月 2 日 |
| 0.9.1 | 2021 年 3 月 30 日 |
| 0.9.0 | 2021 年 2 月 20 日 |
| 0.6.1 | 2020 年 7 月 31 日 |
#80 在 编程语言 中
每月 38 次下载
在 passerine-aspen 中使用
240KB
4K SLoC

Passerine 编程语言
由 Isaac Clayton 和 Passerine 社区用 ♡ 制作 – Veritable 计算倡议的基石。
![]()
![]()
![]()
为什么选择 Passerine?
Passerine 是一种小型、简洁、可扩展的函数式脚本语言,由用 Rust 编写的 VM† 驱动。这里有一个小示例
Passerine 的根源在于 Scheme 和 ML 风格的语言——它是我在编程语言中期望的一切的总结,包括尽可能保持最小化且简洁的愿望。在核心上,Passerine 是带有模式匹配、结构化类型、基于纤维的并发和语法扩展的 lambda 演算。
† 它是一个具有一些优化的字节码 VM,因此可以说它足够快,足以有用。
谁开始的这个项目?
这是 Veritable 计算倡议的第一个项目。我们的目标是改进开发者编写软件时使用的工具。我们计划很快发布一个包含更多关于 Veritable 信息的网站。
Passerine 目前由 Isaac Clayton 开发,他是一名拥有大量空闲时间的高中生。有时一些人会提供反馈和建议。衷心感谢 Raul、Hamza、Rishi、Lúcás、Anton、Yasser、Shaw†、Plecra、IFcoltransG、Jack、Keith‡、Xal 和其他人!
† Shaw正在编写Passerine的替代实现,它非常快。这是他开发高效、语言无关的虚拟机更广泛努力的一部分。
‡ Keith目前正在赞助Passerine的开发——我非常感激他的支持!
概述
当深入了解宏时,这个概述变得非常激动人心。如果您想尝试Passerine,请跳到安装部分。
⚠️请注意,Passerine是一个正在进行中的项目:概述中提到的功能可能尚未实现。
语法
Passerine语法的目标是使所有表达式尽可能简洁,同时仍然保留不同类型表达式的‘感觉’。
我们从简单的例子开始;这是一个平方数字的函数
square = x -> x * x
square 4 -- is 16
顺便说一句:Passerine使用
-- comment进行单行注释,并使用-{ comment }-进行可嵌套的多行注释。
从这个简短的例子中,我们可以从Passerine中学到一些重要的事情
与其他编程语言一样,Passerine使用=进行赋值。左侧是一个模式——在这种情况下,只是一个变量square——它将表达式分解成一组绑定。右侧是一个表达式;在这种情况下,表达式是一个函数定义。
由于Passerine是面向表达式的,因此没有区分语句和表达式的概念。如果表达式没有产生有用的值,它应该返回Unit类型,即
()。例如,赋值返回Unit。
函数调用square 4可能看起来有点陌生;这是因为Passerine使用空白字符进行函数调用。函数调用的形式为l e₀ ... eₙ,其中l是一个函数,e是一个表达式。square 4是一个简单的例子,因为square只接受一个参数,即x... 让我们尝试编写一个接受两个参数的函数!
使用我们的square定义,这是一个返回两点之间欧几里得距离的函数
distance = (x1, y1) (x2, y2) -> {
sqrt (square (x1 - x2) + square (y1 - y2))
}
origin = (0, 0)
distance origin (3, 4) -- is 5
由于Passerine是面向表达式的语言,因此所有函数都是匿名的,这是有意义的。所有函数的形式为p₀ ... pₙ -> e,其中p是一个模式,e是一个表达式。如果函数接受多个参数,它们可以一个接一个地写;a b c -> d等价于a -> (b -> (c -> d))。
函数distance比square复杂一些,因为两个参数是通过元组解构绑定的。
如您所见,distance函数接受两个二元组,即(x1, y1)和(x2, y2),并将每个二元组分解成其组成部分。例如,当我们调用distance函数时,在distance origin (3, 4),该函数会提取构成二元组的数字
origin,即(0, 0),与(x1, y1)进行匹配,创建了绑定x1 = 0和y1 = 0。- 二元组
(3, 4)与(x2, y2)进行匹配,创建了绑定x2 = 3和y2 = 4。
然后,在新的作用域中评估distance的函数体,其中绑定了之前定义的变量。在上述示例中
-- call and bind
distance origin (3, 4)
distance (0, 0) (3, 4)
-- substitute and evaluate
sqrt (square (0 - 3) + square (0 - 4))
sqrt (9 + 5)
sqrt 25
5
现在,您可能已经注意到distance实际上是两个函数。如果我们去掉一些语法糖并像这样重写它,可能会更明显
distance = (x1, y1) -> { (x2, y2) -> { ... } }
第一个函数绑定第一个参数,然后返回一个新的函数,该函数绑定第二个参数并计算出一个值。这被称为柯里化,在编写函数式代码时非常有用。
为了利用柯里化,函数调用是左结合的。调用
a b c d等价于((a b) c) d,而不是a (b (c d))。这种语法来自函数式语言,如Haskell和OCaml,并使柯里化(部分应用)非常直观。
在上面的示例中,我们使用distance来衡量点(3, 4)到原点的距离。巧合的是,这被称为向量的长度。如果能用距离来定义长度不是很好吗?
length = distance origin
length (5, 12) -- is 13
因为距离是柯里化的,所以我们可以只传递它的一个参数。因此,length是一个函数,它接受一个二元组并返回它到origin的距离。本质上,我们可以把上面length的定义读作
length是origin的distance。
通过使用函数和模式匹配来转换数据是Passerine的核心范式。在接下来的几节中,我们将深入探讨如何利用这个小核心语言构建一个强大而灵活的语言。
快速排序示例
这是一个稍微复杂一点的例子——一个具有可疑枢轴选择的递归快速排序
sort = list -> match list {
-- base case
[] -> []
-- pivot is head, tail is remaining
[pivot, ..tail] -> {
higher = filter { x -> x >= pivot } tail
lower = filter { x -> x < pivot } tail
(sorted_lower, sorted_higher) = (sort lower, sort higher)
sorted_lower
+ [pivot]
+ sorted_higher
}
}
你应该首先注意到的是对 match 表达式的使用。和ML风格的编程语言一样,Passerine大量使用 模式匹配 和 解构 来驱动计算。一个match表达式具有以下形式:
match value {
pattern₀ -> expression₀
...
patternₙ -> expressionₙ
}
每个 pattern -> expression 对是一个 分支 ——每个 value 将依次与每个分支匹配,直到某个分支成功匹配并计算——match表达式将采用匹配分支的值。我们将在后面深入了解match语句,所以请记住这一点。
你可能还注意到了在 [head, ..tail] 之后使用了花括号 { ... }。这是一个 块,是一组依次执行的语句。块中的每个语句由换行符或分号分隔;块采用其最后一个表达式的值。
接下来要注意的是这一行
(sorted_lower, sorted_higher) = (sort lower, sort higher)
这比我们之前看到的第一个例子更复杂。在这个例子中,模式 (sorted_lower, sorted_higher) 正在匹配表达式 (sort lower, sort higher)。这个模式是一个 元组 解构,如果你曾经使用过Python或Rust,我敢肯定你对它很熟悉。这个赋值等同于
sorted_lower = sort lower
sorted_higher = sort higher
在这里使用元组解构并没有真正的理由——传统上,仅仅使用 sort lower 和 sort higher 就是更好的解决方案。我们将在下一节深入讨论模式匹配。
Passerine还支持高阶函数(这应该不会让人感到惊讶)
filter { x -> x >= pivot } tail
filter 接收一个谓词(一个函数)和一个可迭代的(如列表),并产生一个新的可迭代序列,其中谓词对所有项都为真。尽管可以在 filter 后使用括号来分组内联函数定义,但使用块来表示 计算区域 在风格上更一致。什么是计算区域?计算区域是一系列多个表达式,或者是一个创建新绑定的单个表达式,例如赋值或函数定义。
Passerine还允许在运算符周围拆分行,以分割长表达式
sorted_lower
+ [pivot]
+ sorted_higher
尽管这个表达式并不特别长,但通过操作拆分行可以有助于提高某些表达式的可读性。
函数应用
在我们继续之前,这里有一个在Passerine中实现FizzBuzz的巧妙示例
fizzbuzz = n -> {
test = d s x
-> if n % d == 0 {
_ -> s + x ""
} else { x }
fizz = test 3 "Fizz"
buzz = test 5 "Buzz"
"{n}" . fizz (buzz (i -> i))
}
1..100 . fizzbuzz . print
. 是函数应用运算符
-- the composition
a . b c . d
-- is left-associative
(a . (b c)) . d
-- and equivalent to
d ((b c) a)
模式匹配
在上一个部分,我们简要介绍了模式匹配。我希望现在可以进一步深入,并有力地论证为什么Passerine中的模式匹配是一个如此强大的结构。模式用于三个地方
- 赋值,
- 函数,
- 以及类型定义。
我们将简要讨论每种类型的模式及其使用的上下文。
什么是模式?
模式 通过镜像类型的结构从 类型 中提取 数据。将模式应用于类型的行为称为 匹配 或 解构 ——当模式成功匹配某些数据时,将产生多个 绑定。
Passerine支持代数数据类型,并且所有这些类型都可以进行匹配和解构。以下是Passerine的模式表
在以下表格中,
p是一个嵌套的子模式。
| 模式 | 示例 | 解构 |
|---|---|---|
| 变量 | foo |
终端模式,将变量绑定到一个值。 |
| 数据 | 420.69 |
终端模式,必须匹配的数据,否则会引发错误。参见下一节关于纤维和并发的内容,以了解Passerine中错误的工作原理。 |
| 丢弃 | _ |
终端模式,匹配任何数据,不产生绑定。 |
| 标签 | Baz p |
匹配标签,即Passerine中的命名 类型。 |
| 元组 | (p₀, ...) |
匹配元组的每个元素,元组是一组元素,可能具有不同的类型。单元 () 是空元组。 |
| 列表 | []/[p₀, ..p₁] |
[] 匹配空列表 - p₀ 匹配列表的头部,..p₁ 匹配尾部。 |
| 记录 | {f₀:p₀, ...} |
记录,即结构体。这是一个字段-模式对的序列。如果目标记录中不存在字段,则会引发错误。 |
| 枚举 | {p₀; ...} |
枚举,即联合。如果任何模式成立,则匹配。 |
| 是 | p₀:p₁ |
类型注解。仅当 p₁ 成立时才与 p₀ 匹配,否则引发错误。 |
| where | p|e |
与其他模式略有不同。仅当表达式 e 为真时才匹配 p。 |
信息量相当大,所以让我们一步一步地来。最简单的情况是标准的赋值
a = b
-- produces the binding a = b
这非常简单,我们已经在之前的讨论中涵盖了这一点,所以让我们先来讨论匹配 数据。以下函数将在第一个参数传递给函数的值是 true 时返回第二个参数。
true second -> second
如果第一个参数不是 true,比如说 false,Passerine 会提醒我们
Fatal Traceback, most recent call last:
In src/main.pn:1:1
|
1 | (true second -> second) false "Bananas!"
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
In src/main.pn:1:2
|
1 | (true second -> second) false "Bananas!"
| ^^^^
|
Runtime Pattern Matching Error: The data 'false' does not match the expected data 'true'
丢弃 是另一种简单的模式 - 它不执行任何操作。它与其他模式一起使用时最有用
-- to ensure an fruit has the type Banana:
banana: Banana _ = mystery_fruit
-- to ignore an item in a tuple:
(_, plays_tennis, height_in_feet) = ("Juan Milan", true, 27.5)
-- to ignore a field on a record:
{ name: "Isaac Clayton", age: _, skill } = isaac
标签是一个赋予类型的名称。当然,名称并不保证类型安全,但它们在大多数情况下做得相当不错
-- make a soft yellow banana:
banana = Banana ("yellow", "soft")
-- check that the banana flesh is soft:
if { Banana (_, flesh) = banana; flesh == "soft" } {
print "Delicioso!"
}
标签的匹配用于 提取 构造该标签所使用的原始数据。
元组 相当简单 - 我们已经讨论过了 - 因此接下来我们将讨论记录。记录是一组字段
-- define the Person type
type Person {
name: String,
age: Natural,
skill, -- polymorphic over skill
}
-- Make a person. It's me!
isaac = Person {
name: "Isaac Clayton",
age: 16,
skill: Wizard "High enough ¯\_(ツ)_/¯",
}
以下是您可以对 isaac 进行模式匹配的方法
Person {
-- aliasing field `name` as `full_name`
name: full_name,
-- `age` is ignored
age: _,
-- short for `skill: skill`
skill,
} = isaac
当然,字段后面的模式是一个完整的模式,可以进一步进行匹配。
是 是类型注解
Banana (color, _): Banana (_, "soft") = fruit
在这个例子中,如果 fruit 是一个 1 个元组的元素为 "soft" 的 Banana,则 color 将被绑定。
† 读作 'firnd',对应于 1 索引的 第二个 元素。Zerost,firnd,secord,thirth,fourth,fifth...
最后,我们将讨论我最喜欢的模式之一,where。Where 允许任意代码检查模式的有效性。这可以走得很远。例如,让我们以整数的形式定义自然数
type Natural n: Integer | n >= 0
这应该被解释为
Natural类型是一个大于0的Integern。
有了这个定义,
-- this is valid
seven = Natural 7
-- this is not
negative_six = Natural -6
模式中的Where子句确保类型的底层数据永远不会破坏不变性。想象一下,这比通过类型构造器确保名称安全更强大。
待办事项:特性和实现。
模式匹配和代数数据类型允许快速构建和拆解表达式的数据模式。由于数据(以及应用于它的转换)是任何程序的核心,快速构建和拆解复杂数据类型的结构是一种构建表达应用程序的强大工具。
纤程
Passerine如何处理错误?关于并发性呢?
素数筛子、异常和for循环有什么共同之处?如果你猜到了并发性,你就赢得了无数积分!结构化并发是一个难以解决的问题,因为它在领域语言设计中无处不在。
重要的是要指出,并发性并不等同于并行性。并发系统可能是并行的,但这并不总是如此。Passerine遵循结构化并发的协程模型——更简洁地说,Passerine使用纤程——如Wren所展示的。纤程是与其他纤程协作调度的轻量级执行过程。每个纤程就像一个独立的小系统,可以向其他纤程传递消息。
待办事项:代数效应?
错误处理
Passerine使用异常和代数数据类型的组合来处理错误。预期可能发生的错误应该被包裹在Result类型中
validate_length = n -> {
if length n < 5 {
Result.Error "It's too short!"
} else {
Result.Ok n
}
}
然而,有些错误是意外的。软件可能以无数种方式失败;在某些情况下,考虑到所有外部情况是完全不可能的。
因此,在某种预期不会失败的事情失败的情况下,会抛出一个异常。例如,尝试打开一个应该存在的文件可能会抛出错误,如果它已经丢失、移动、损坏或具有不正确的权限。
config = Config.parse (open "config.toml")
.是索引操作符。在列表或元组上,items.0返回零索引项;在记录上,record.field返回指定的字段;在标签上,Label.method返回指定的关联方法。
我们不必总是处理这些错误的原因是Passerine遵循快速失败、安全失败的理念。在这方面,Passerine遵循Erlang/Elixir的理念
"保持冷静,让它崩溃"。
好消息是崩溃是局部的——一个纤程崩溃不会导致整个系统崩溃。处理可能失败的操作的惯用方法是尝试它。try在新的纤程中执行操作,并将可能发生的任何异常转换为Result
config = match try (open "config.toml") {
Result.Ok file -> Config.parse file
Result.Error error -> Config.default ()
}
我们知道某些函数可能会引发错误,但我们如何我们表示发生了异常严重的事情?我们使用error关键字!
doof = platypus -> {
if platypus == "Perry" {
-- crashes the current fiber
error "What!? Perry the platypus!?"
} else {
-- oh, it's just a platypus...
work_on_inator ()
}
}
-- oh no!
inator = doof "Perry"
请注意,引发的错误值可以是任何数据。这允许程序从错误中恢复
-- socket must not be disconnected
send_data = (
socket
data
) -> match socket.connection {
-- `Disconnected` is a labeled record
Option.None -> error Disconnected {
socket,
message: "Could not send data; disconnected",
}
-- if the connection is open, we send the data
Option.Some connection -> connection.write data
}
假设上面的代码尝试通过套接字发送一些数据。要处理断开连接,我们可以尝试错误
ping = socket -> try (send_data socket "ping")
socket = Socket.new "isaac@passerine.io:42069" -- whatever
socket.disconnect () -- oh no!
result = ping socket
match result {
Result.Ok "pong" -> ()
Result.Error Disconnected socket -> socked.connect
}
为什么要区分预期错误(Result)和意外错误(纤程崩溃)?程序只有在它们运行的环境有效时才会产生有效结果。当纤程崩溃时,它表明其运行的环境中有不合法的地方。这对开发者在开发过程中非常有用,在复杂长运行程序可能因各种原因失败的环境中,对程序也非常有用。
为什么不只使用异常呢?因为有可能发生根本不是异常的错误。不正确的输入、权限错误、丢失的项目——这些都是可能发生并且经常发生的事情。始终使用正确的工具来完成工作;优先考虑预期错误而不是意外错误。
并发
纤程不仅仅是用于隔离错误上下文。如前所述
纤程是一种轻量级的执行过程,与其他纤程协同调度。每个纤程就像一个小的系统,可以与其他纤程传递消息。
Passerine利用纤程来处理错误,但纤程是完整的协程。要创建纤程,请使用纤程关键字
counter = fiber {
i = 0
loop { yield i; i = i + 1 }
}
print counter () -> prints 0
print counter () -> prints 1
print counter () -> ...
yield关键字挂起当前纤程并将值返回给调用纤程。 yield也可以用来将数据传递给纤程。
passing_yield = fiber {
print "hello"
result = yield "banana"
print result
"yes"
}
passing_yield "first" -- prints "hello" then evaluates to "banana"
passing_yield "second" -- prints "second" then evaluates to "yes"
passing_yield "uh oh" -- raises an error, fiber is done
要构建更复杂的系统,你可以使用函数构建纤程
-- a function that returns a fiber
flopper = this that -> fiber {
loop {
yield this
yield that
}
}
apple_banana = flopper "Apple" "Banana"
apple_banana () -- evaluates to "Apple"
apple_banana () -- evaluates to "Banana"
apple_banana () -- evaluates to "Apple"
apple_banana () -- ... you get the point
当然,可能性是无限的。在我们开始讨论宏之前,还有一件事我想讨论。纤程,虽然通常在另一个上下文中运行,但都彼此作为对等体。如果你有一个纤程的引用,你可以在忘记其被调用的上下文的情况下将其转移到纤程上。要切换到纤程,请使用switch。
banana_and_end = fiber {
print "banana ending!"
}
print "the beginning..."
switch banana_and_end
print "the end."
"the end."永远不会显示。
这并非终点,这只是开始...是黑客时间!
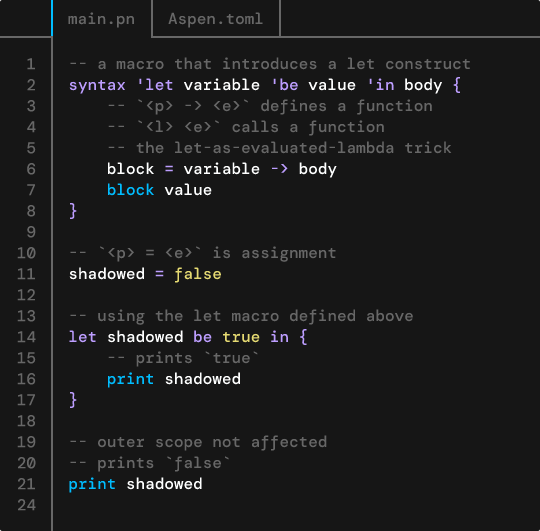
宏
Passerine有一个丰富的卫生性*语法宏系统,该系统扩展了语言本身。
语法宏,简单来说,是在编译时被调用时,能够卫生地产生更多代码的代码片段。宏使用一组小而简单但强大的规则来转换代码。
*在阅读了Doug Hoyte的优秀的Let Over Lambda之后,我理解了丰富的不卫生宏系统的原始力量。然而,这样的系统难以理解,更难掌握。Passerine旨在尽可能简单和强大,同时不失透明度:卫生宏系统比其不透明的非卫生对应物更透明。
卫生性
扩展是通过使用syntax关键字定义的,后跟一些参数模式,然后是捕获的参数将被拼接到的代码。这里有一个简单的例子:我们使用宏来定义swap运算符
syntax a 'swap b {
tmp = a
a = b
b = tmp
}
x = 7
y = 3
x swap y
注意上述代码是完全卫生的。展开的宏看起来像这样
_tmp = x
x = y
x = _tmp
因为tmp没有作为宏模式参数传递,所以宏体中所有对tmp的使用都是唯一的、不可表示的变量,它们不会与作用域中当前绑定的任何其他变量冲突。本质上
tmp = 1
x = 2
y = 3
x swap y
不会影响tmp的值;tmp仍然将是1。
参数模式
那么,什么是参数模式(arg-pat)?Arg-pats是它们之间的内容
syntax ... { }
在 syntax 和宏体之间的每个项目都是一个 arg-pat。Arg-pats 可以是
- 语法变量,例如
foo和bar。 - 文本 语法标识符,前面带有引号(
'),例如'let。 - 嵌套的参数模式,后面可以跟可选的 修饰符。
让我们从 语法标识符 开始。标识符是必须存在于模式中以匹配的文本名称。每个语法扩展至少需要有一个。例如,这里有一个匹配 for 循环 的宏:
syntax 'for binding 'in values do { ... }
在这种情况下,'for 和 'in 是语法标识符。这个定义可以这样使用:
for a in [1, 2, 3] {
print a
}
语法变量是模式中的其他标识符,它们绑定到实际值。在上面的例子中,a → binding,[1, 2, 3] → values,以及 { print a } → do。
宏也可以用来定义操作符†
syntax sequence 'contains value {
c = seq -> match seq {
[] -> False
[head, ..] | head == value -> True
[_, ..tail] -> c tail
}
c sequence
}
这定义了一个 contains 操作符,可以用如下方式使用:
print {
if [1, 2, 3] contains 2 {
"It contains 2"
} else {
"It does not contain 2"
}
}
显然,会打印 It contains 2。
† 以这种方式定义的定制操作符始终具有最低优先级,并且当存在歧义时必须显式分组。因此,Passerine 已经有许多具有正确优先级的内置操作符,可以重载。重要的是要注意,宏旨在引入新构造,这些构造恰好是可组合的——语法宏可以用来创建自定义操作符,但它们可以用作 如此之多。我认为这是一个公平的权衡。
修饰符 是后缀符号,允许在参数模式内提供灵活性。以下是一些修饰符:
- 零个或多个(
...) - 可选的(
?)
此外,括号用于分组,{ ... } 用于匹配块内的表达式。让我们构建一些匹配 if else 语句的语法参数,例如这个:
if x == 0 {
print "Zero"
} else if x % 2 == 0 {
print "Even"
} else {
print "Not even or zero"
}
arg-pat 必须匹配一个开始的 if
syntax 'if { ... }
然后是一个条件
syntax 'if condition { ... }
然后是第一个块
syntax 'if condition then { ... }
接下来,我们需要一系列 else if <condition> 语句
syntax 'if condition then ('else 'if others do)... { ... }
后面是一个必需的关闭 else(Passerine 是面向表达式的,并且进行了类型检查,所以关闭的 else 确保一个 if 表达式始终返回一个值。)
syntax 'if condition then ('else 'if others do)... 'else finally { ... }
当然,if 语句已经内置在语言中——让我们构建一些其他东西——一个 match 表达式。
构建一个 match 表达式
匹配表达式接受一个值和多个函数,并尝试将值应用于每个函数,直到成功匹配并运行。匹配表达式看起来像这样:
l = Some (1, 2, 3)
match l {
Some (m, x, b) -> m * x + b
None -> 0
}
这是我们可以匹配匹配表达式的例子
syntax 'match value { arms... } {
-- TODO: implement the body
}
这应该被读作
匹配表达式的语法从伪关键字
match开始,后面跟着要匹配的value,然后是一个块,其中的每个项目都被收集到列表arms中。
关于体呢?嗯
- 如果没有匹配的分支,则会引发错误。
- 如果有一些分支,我们会在新的纤维中尝试第一个分支,看看它是否匹配。
- 如果函数没有引发匹配错误,我们就找到了匹配!
- 如果函数引发匹配错误,我们再尝试剩余的分支。
让我们先从实现这个函数开始
-- takes a value to match against
-- and a list of functions, branches
match_function = value branches -> {
if branches.is_empty {
error Match "No branches matched in match expression"
}
result = try { (head branches) value }
if result is Result.Ok _ {
Result.Ok v = result; v
} else if result is Result.Error Match _ {
match_function value (tail branches)
} else if result is Result.Error _ {
-- a different error occurred, so we re-raise it
Result.Error e = result; error e
}
}
我知道使用 if 来处理模式匹配擅长的任务会有些痛苦,但记住,这就是我们构建匹配表达式的理由! 使用基本构造来创建具有很少开销的高级功能是 Passerine 开发的核心主题。
顺便说一句,这是如何使用 match_function 的
-- Note that we're passing a list of functions
description = match_function Banana ("yellow", "soft") [
Banana ("brown", "mushy") -> "That's not my banana!",
Banana ("yellow", flesh)
| flesh != "soft"
-> "I mean it's yellow, but not soft",
Banana (peel, "soft")
| peel != "yellow"
-> "I mean it's soft, but not yellow",
Banana ("yellow", "soft") -> "That's my banana!",
Banana (color, texture)
-> "Hmm. I've never seen a { texture } { color } banana before...",
]
这已经好多了,但传递函数列表仍然感觉有点……笨拙。让我们使用我们之前定义的 match 宏定义来使它更加方便
syntax 'match value { arms... } {
match_function value arms
}
我们已经将匹配表达式添加到 Passerine 中,并且它们已经感觉像语言特性了!这不是很神奇吗?以下是使用 match_function 的上面示例,现在调整为使用 match†
description = match Banana ("yellow", "soft") {
Banana ("brown", "mushy") -> "That's not my banana!"
Banana ("yellow", flesh)
| flesh != "soft"
-> "I mean it's yellow, but not soft"
Banana (peel, "soft")
| peel != "yellow"
-> "I mean it's soft, but not yellow"
Banana ("yellow", "soft") -> "That's my banana!"
Banana (color, texture)
-> "Hmm. I've never seen a { texture } { color } banana before..."
}
† 转折点:我们刚刚定义了贯穿整个概述中使用的
match表达式。
模块
Passerine 的模块系统允许将大型代码库拆分为可重用的单个组件。模块是将作用域转换为结构体,并且不一定与文件系统相关联。
模块使用 mod 关键字定义,它必须后面跟一个块 { ... }。以下是一个定义了一些数学工具的简单模块
circle = mod {
PI = 3.14159265358979
area = r -> r * PI * PI
circum = r -> r * PI * 2
}
pizza_radius = 12
slices = 8
slice_area = (circle::area pizza_radius) / slices
mod 会获取块中的所有顶级声明 - 在这种情况下,PI、area 和 circum - 并将它们转换为具有这些字段的结构体。本质上,上面的代码等同于这个结构体
circle = {
PI: 3.14159265358979
area: r -> r * PI * PI
circum: r -> r * PI * 2
}
mod 很好,因为它是一种轻松实现多个返回值的方法。在本质上,mod 关键字通过将作用域转换为结构体来实现第一类作用域。
index = numbers pos
-> floor (len numbers * pos)
quartiles = numbers -> mod {
sorted = (sort numbers)
med = sorted::(index (1/2) sorted)
q1 = sorted::(index (1/4) sorted)
q3 = sorted::(index (3/4) sorted)
}
因为我们使用了上面的例子中的 mod 关键字,所以不是从函数中返回单个值,而是返回一个包含函数中所有值的结构体。
-- calculate statistics
numbers = [1, 2, 3, 4, 5]
stats = quartiles numbers
-- use `q1` and `q3` to calculate the interquartile range of `numbers`
iqr = stats::q3 - stats::q1
print "the IQR of { numbers } is { iqr } "
这对于编写返回多个值的函数非常有用。
除了允许我们将相关值集组合到单个命名空间中之外,模块可以在不同的文件中定义,然后导入。以下是在不同文件中定义的模块
-- list_util.pn
reduce = f start list -> match list {
[] -> start,
[head, ..tail] -> f (reduce f tail, head)
}
sum = reduce { (a, b) -> a + b } 0
reverse = reduce { (a, b) -> [b.., a]} []
此文件定义了多个有用的列表工具,以传统的递归风格定义。如果我们想在 main.pn 中使用此模块,我们使用 use 关键字导入它
-- main.pn
use list_util
numbers = [1, 1, 2, 3, 5]
print (list_util::sum numbers)
请注意,use 关键字基本上与将导入文件的内容包裹在 mod 关键字中是同一件事。
-- use list_util
list_util = mod { <list_util.pn> }
导入后,list_util 就是一个结构体。正因为如此,模块系统的特性自然而然地从 Passerine 现有的结构体操作语义中产生。为了导入模块的一部分,我们可以这样做:
reverse = { use list_util; list_util::reduce }
同样,我们可以在块作用域内导入一个模块并将其重命名
list_stuff = { use list_util; list_util }
由此产生的模块系统具有许多良好的特性,我们只是触及了皮毛。由于模块只是结构体,Passerine 和它的宏系统在构建可扩展系统时可以充分利用,这些系统可以很好地组合。
结语
感谢您阅读至此。Passerine 对我来说是一件快乐的事情去工作,我希望您在使用它时也能感到快乐。
本概述中讨论的一些功能尚未实现。我们并不是试图让您失望,只是开发一种编程语言并在同时建立一个社区并不是一件容易的事情。如果您想为 Passerine 添加一些功能,请打开一个问题或拉取请求,或查看路线图。
常见问题解答(FAQ)
问:Passerine 是否适合用于生产环境?
答:目前还不适合。Passerine 还处于开发的早期阶段,经常发生破坏性的变化。请参阅项目路线图(见下文 👇)以了解正在开发的内容。
问:Passerine 是否是静态类型?
答:目前 Passerine 是强类型和动态类型(技术上为结构化类型)。这部分是出于必要 – 类型由模式定义,而模式可以在任何地方进行断言。然而,我已经对 Hindley-Milder 类型系统及其各种扩展进行了大量研究。
我正在努力为语言开发一个基于 Hindley-Milner 类型推理的编译时类型检查器。有了这个系统,我可以做一些假设来进一步加快解释器的速度,也许可以单态化/生成 LLVM IR / WASM。
这个类型检查器将是下一个版本的目标,所以请耐心等待!
问:关于代数效应和基于类型的宏呢?
答:我最终有兴趣将这两者都添加到语言中,但首先我需要实现一个良好的类型检查器并做更多的研究。代数效应将填补纤维的设计空间,基于类型的宏将为 Passerine 的宏系统提供一个更坚实的基础。您认为有哪些新的语言特性可以补充 Passerine 的设计理念?请告诉我们!
问:什么是汽化内存管理?
答:在我最初设计 Passerine 时,我非常热衷于自动编译时内存管理。目前,有几种方式可以实现这一点:从 Rust 的借用检查器,到 µ-Mitten 的 Proust ASAP,到 Koka 的 Perceus,有大量新的和令人兴奋的方法来解决这个问题。
汽化是一种自动内存管理系统,允许进行 功能但在原地 编程。为了让汽化工作,必须保持以下三个不变性:
- 所有函数参数通过写时复制的引用按值传递。这意味着只需要保留返回对象的生存期,所有其他对象将在它们超出作用域时被删除。
- 执行了一种形式的 SSA(静态单赋值),其中任何值的最后一个使用不是该值的副本。
- 所有闭包引用是不可变值的副本。这些副本可以以循环无关的方式引用计数。
有了这些不变性,汽化确保以下两点:
- 值只有在它们仍然 有用 时才存活。
- 代码可以以函数式风格编写,但所有突变都按照规则 2 在原地发生。
最有趣的是,当与虚拟机配合使用时,该系统对编译器的干扰最小。编译器只需注释任何变量的最后使用值;其余的可以在运行时自动且非常高效地完成。
为什么不使用这个呢?主要是因为第三条规则:“闭包引用是不可变的”。Passerine 是按值传递的,但当前允许按 let 样式在当前作用域中进行修改。但这可能有所改变;一旦改变,那就完全消失了,宝贝!
问:编程语言不是已经足够多了吗?
答:坦白说,我认为我们对编程语言设计的理解还刚刚触及表面。说编程语言设计已经饱和并且达到了局部最大值,这是对软件开发本质的不理解。Passerine 大部分是一个测试,看看我是否能构建一个现代编译器管道。但我更感兴趣的是围绕开发环境的工具。
举例来说:基于文本的编程语言输入已经存在很长时间了,因为这种方式很快。然而,它并不总是语义正确的。正确的程序数量远远小于可能的文本文件数量。但仍然可以创建确保语义正确性的基于文本的输入系统,同时鼓励探索。未来,我们需要开发新的工具,使语言和环境之间的界限更加模糊。Pharo 是正确方向的步骤,Unison 和类似的努力也是如此。
我将来会更多地关注这一点。一个有趣的项目是为一个小的最小化语言,如 Scheme,或甚至 Passerine,开发一个像 Pharo/Unison 一样的编辑器/环境。
安装
Passerine 仍然是一个非常正在进行的工程项目。我们已经做了很多,但还有更多的事情要做!
对于你们这些先锋,了解 Passerine 的最佳方式是安装 Aspen¹,Passerine 的包管理器和 CLI。
如果您使用的是 *nix 风格² 系统,运行³
sh <(curl -sSf https://www.passerine.io/install.sh)
- 如果您在开始时遇到困难,请向社区 Discord 服务器 寻求帮助。
- 已在 Arch (btw) 和 macOS 上测试。
- 现在在 Windows™ 上也进行了测试!
- (此外,实验性地 支持 Wasm。)
- 未来,我们计划提供预构建的二进制文件,但到目前为止,需要 Git 和 Cargo。
贡献
欢迎贡献!阅读我们的 贡献指南 并加入 Discord 服务器 以开始!
如果您想为项目做出贡献但没有太多时间,请考虑 捐赠。谢谢!
路线图
查看 项目路线图 了解当前正在开发的内容。