1个不稳定版本
使用旧的Rust 2015
| 0.1.0 | 2018年1月15日 |
|---|
在文本处理中排名#1402
75KB
1K SLoC
优化匹配广义摇摆变换格式 — 8位
此包实现了“OMG-WTF-8”编码,使其可以通过“模式1.5”API作为模式使用,因此不需要从“模式2.0”的两个单独的PatternAPI。
背景
WTF-8的缺点
WTF-8通过允许使用类似于CESU-8的常规UTF-8编码算法使用孤立的代理代码点来扩展UTF-8,例如,U+D800编码为3字节序列ed a0 80。与CESU-8不同,WTF-8将非BMP字符编码为4字节序列,因此从有效的UTF-8序列转换是零成本的。
这两个决定意味着我们无法在代理对中间分割一个良好的WTF-8字符串,这使得无法实现一些常见的字符串API,如split()。
let haystack = OsString::from_wide(&[0xd800, 0xdc00, 0xd800, 0xdc01, 0xd800, 0xdc02]);
let needle = OsString::from_wide(&[0xd800]);
for part in haystack.split(&needle) {
println!("{:?}", part); // <-- how could we represent `part` as an `&OsStr`?
}
// should print "", "\u{dc00}", "\u{dc01}", "\u{dc02}".
分割代理对
修改后的WTF-8编码通过允许将4字节序列分割成两半,表示代理代码点在开始或末尾的孤立代码点来解决此问题。为了了解为什么这是可能的,让我们检查UTF-8、-16和-32中非BMP字符的编码。
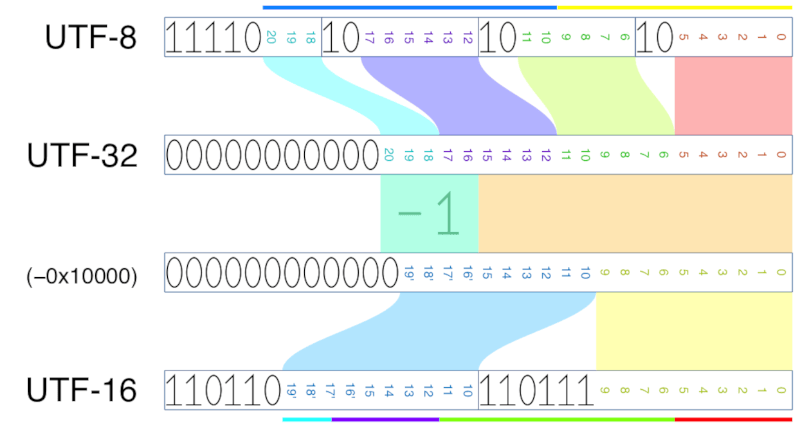
在UTF-8中,第一个字节编码3位,接下来的三个字节每个编码6位。在UTF-16中,每个代码单元编码10位。因此,UTF-8 4字节序列的前3个字节足以确定对应UTF-16编码中的高代理,最后2个字节足以确定低代理。
因此,我们可以将4字节序列f0 9f 98 82分割成两个重叠的子字符串f0 9f 98和98 82,每个子字符串都足以确定相应的代理代码点,从而能够与适当的WTF-8编码进行比较。
为了保持一致性,我们将使用3字节子字符串而不是2个字节来编码低代理。
定义
术语
OMG-WTF-8中使用的术语遵循WTF-8的术语。
Unicode 码点 是 Unicode 码空间中的任何值。它写成“U+XXXX”,其中 XXXX 是一个十六进制数。有效的码点范围是从 U+0000 到 U+10FFFF,包括两者。
高代理 是范围在 U+D800 到 U+DBFF 之间的码点。
低代理 是范围在 U+DC00 到 U+DFFF 之间的码点。
代理 是高代理或低代理,即范围在 U+D800 到 U+DFFF 之间的码点。
代理对 是两个码点,其中第一个码点是高代理,第二个码点是低代理。
字符串中的 未配对高代理 是一个没有紧接着低代理的高代理。
字符串中的 未配对低代理 是一个没有前面有高代理的低代理。
未配对代理 是未配对高代理或未配对低代理。
4字节序列 是范围在 U+10000 到 U+10FFFF 之间的字符的 UTF-8 编码,它占用4个字节。
3字节序列 是3个连续的字节序列。
代理的 规范表示 是一个3字节序列,通过通用 UTF-8 编码该码点生成。
| 规范表示 | 字节0 | 字节1 | 字节2 |
|---|---|---|---|
| 高代理 | ed |
a0–af |
80–bf |
| 低代理 | ed |
b0–bf |
80–bf |
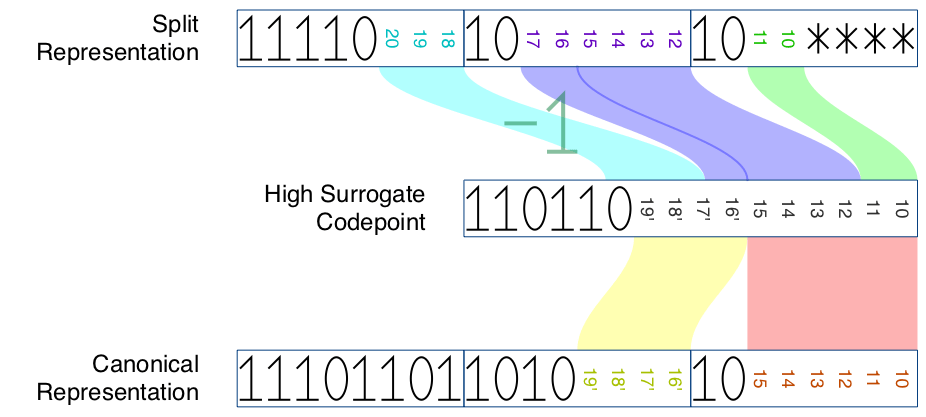
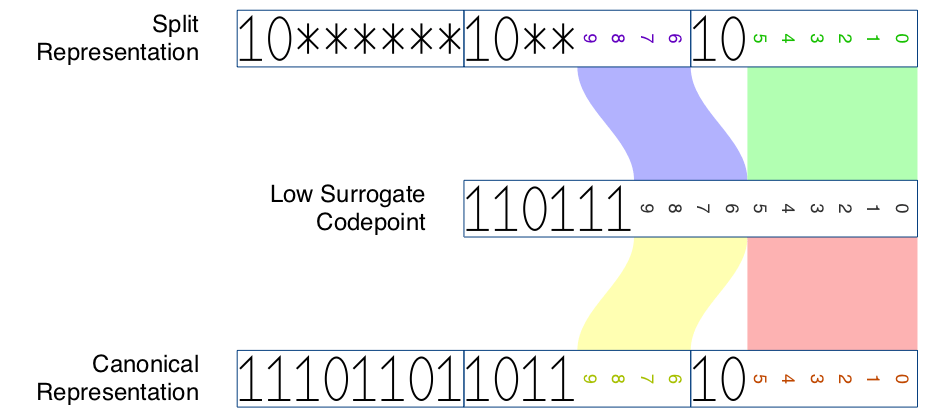
代码点范围 U+10000 到 U+10FFFF 中的每个字符都可以编码为 UTF-16 中的代理对,以及 UTF-8 中的4字节序列。对于此字符,4字节序列的前3个字节是高代理的 分割表示。同样,4字节序列的最后3个字节是低代理的分割表示。
| 分割表示 | 字节0 | 字节1 | 字节2 |
|---|---|---|---|
| 高代理 | f0 |
90–bf |
80–bf |
| 高代理 | f1–f3 |
80–bf |
80–bf |
| 高代理 | f4 |
80–8f |
80–bf |
| 低代理 | 80–bf |
80–bf |
80–bf |
OMG-WTF-8
有效的 OMG-WTF-8 序列按顺序由以下组成
- 字符串开头可能有一个3字节序列,这是低代理的分割表示,
- 一个有效的 WTF-8 序列,以及
- 字符串结尾可能有一个3字节序列,这是高代理的分割表示。
因此,任何有效的 WTF-8 字符串都是有效的 OMG-WTF-8 序列。
分割表示的代理永远不会出现在 OMG-WTF-8 序列的中间。分割表示的高代理只能出现在字符串的末尾,分割表示的低代理只能出现在字符串的开头。
规范化 是将分割表示的3字节序列转换为规范表示的过程。这个过程可以在原地完成。
任何有效的 OMG-WTF-8 序列都可以通过规范化转换为有效的 WTF-8 序列。由于分割表示的代理只能出现在字符串的两端,规范化是 O(1) 并且非常便宜。
OMG-WTF-8 字符串通过其规范化进行哈希和比较。OMG-WTF-8 字符串的顺序应与有效的 UTF-8 顺序兼容。当出现未配对代理时,实际的顺序是不确定的。尽管如此,OMG-WTF-8 应该是完全有序的。
存储时必须将 OMG-WTF-8 转换为 WTF-8。
切片
可以切片一个有效的 OMG-WTF-8 字符串 s[i..j]。为了保持有效性,结果字符串可能比 j - i 更长。
索引可以指向4字节序列的中间,例如:
let s = OmgWtf8::from_str("\u{10000}");
let first_half = &s[..2]; // valid, returns the 3-byte sequence "\xf0\x90\x80".
let second_half = &s[2..]; // valid, returns the 3-byte sequence "\x90\x80\x80".
let empty_str = &s[2..2]; // valid, returns an empty string "".
指向3字节序列的中间始终是错误。
由于重叠,拆分可变的OMG-WTF-8字符串是不安全的。我们建议只在不可变的情况下使用OMG-WTF-8,如果需要可变访问,则将其转换为WTF-8。
匹配
OMG-WTF-8序列可以用作字符串匹配的针。在匹配时,将开头(无论以何种形式表示)的任何未配对的低代理转换为正则表达式,例如:
(\xed\xb0\x80|[\x80-\xbf][\x80\x90\xa0\xb0]\x80)
并将结尾的任何未配对的高代理转换为正则表达式,例如:
(\xed\xa0\x80|\xf0\x90[\x80-\x8f])
中间的WTF-8序列按字节逐字节匹配。
找到匹配后,光标可能指向4字节序列的第1个或第3个字节。在这种情况下,需要重新调整索引以指向第2个字节。光标本身也可能需要向后移动2个字节以进行下一个匹配,例如,在以下代码中搜索 \u{dc00}\u{d800} 应该在 2..6 和 6..10 产生2个匹配。
此包
omgwtf8包是一个展示概念可行的演示。这不是为了性能或功能完整性而实现的。
依赖关系
~3.5MB
~72K SLoC