4个版本
| 0.1.4 | 2020年4月8日 |
|---|---|
| 0.1.3 | 2019年11月18日 |
| 0.1.2 | 2019年9月23日 |
| 0.1.1 | 2019年9月22日 |
| 0.1.0 |
|
#1312 在 数据结构 中
175KB
861 行
nanoset.py 
为可能为空的Python集合提供内存优化的包装器。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
⏱️ TL;DR
通过一行代码,将代码中空set实例使用的内存减少85%
from nanoset import PicoSet as set
🚩 目录
🗺️ 概述
🐏 关于Python内存使用
Python是一种优秀的编程语言(辩论我吧),但有时你会质疑为什么它会以某种方式行事。自Python 2.3以来,标准库提供了set集合,这是一个专门用于成员资格测试的容器。与无处不在的list集合相反,set是无序的(或者更准确地说,不允许你访问它存储元素的方式)。set的另一个特性是,就像它的数学对应物一样,它不允许重复,这对于某些算法非常有用。然而,集合是内存密集型的
>>> import sys
>>> sys.getsizeof(list())
72
>>> sys.getsizeof(set())
232
一个空集合比一个空列表多占用三倍以上的内存!对于具有大量set属性的某些数据结构或对象,它们可以迅速导致大量内存被用于无意义的事情。这在你习惯了Rust时尤其令人沮丧,因为Rust中的大多数集合都按需分配。这正是nanoset发挥作用的时刻:
>>> import nanoset
>>> sys.getsizeof(nanoset.NanoSet())
56
>>> sys.getsizeof(nanoset.PicoSet())
24
实际上,这是一个谎言,但请继续阅读.
💡 简单示例用例
让我们假设我们正在构建一个有序图数据结构,我们可能想要存储分类数据或任何其他类型的层次结构。我们可以简单地使用以下两个类定义图及其节点
class Graph:
root: Node
nodes: Dict[str, Node]
class Node:
neighbors: Set[node]
这使得在两个节点之间添加边和查询边是否存在成为一个O(1)操作,遍历所有节点是一个O(n)操作,这可能是我们在这里想要的。我们使用set而不是list,因为我们想避免重复存储边,这是一个明智的选择。但现在让我们来看看术语的统计信息,这是美国国家生物技术信息中心开发的用于有机体分类的数据库NCBITaxon项目。
Metrics
Number of classes*: 1595237
Number of individuals: 0
Number of properties: 0
Classes without definition: 1595237
Classes without label: 0
Average number of children: 12
Classes with a single child: 40319
Maximum number of children: 41761
Classes with more than 25 children: 0
Classes with more than 1 parent: 0
Maximum depth: 38
Number of leaves**: 1130671
根据这些,我们总共将有1,130,671个叶子节点,总共有1,595,237个节点,这意味着有70.8%是空集。现在你可能认为
好吧,我明白了。但在这种情况下,我只需要一个特殊案例,对于叶子节点,当这个集合为空时,我存储对
None的引用,而不是存储一个空的neighbors集合。然后我可以在想要从该节点添加新边时,将这个引用替换为实际的集合。问题解决了!
很高兴我们看法一致:这正是nanoset为你做的事情!
🔨 实现
实际上,这根本不是什么魔法。想象一个名为NanoSet的类,它作为一个代理,代表它所包装的真实的Python set,但只有在实际需要存储数据时才会分配
class NanoSet(collections.abc.Set):
def __init__(self, iterable=None):
self.inner = None if iterable is None else set(iterable)
def add(self, element):
if self.inner is None:
self.inner = set()
self.inner.add(element)
# ... the rest of the `set` API ...
就是这样!然而,在Python中以这种方式做并不会特别高效,因为生成的对象将会占用64字节。使用slots,这可以减少到56字节,与NanoSet的效果相当。
注意,这些值仅在内部集合为空时适用!当实际分配集合以存储我们的值时,我们还需要额外分配232字节数据。这意味着使用NanoSet会引入一些开销,因为非空集合现在将占用288字节(PicoSet为256字节)。
好吧,我之前的方法更好,我到处存储
Optional[Set],我不想为非空集合支付任何额外的成本!
当然。但这意味着你需要改变整个代码。实际上,与使用nanoset相比,你从这样做中获得的内存提升可能并不多,因为包装器性能不佳的唯一情况是负载因子超过90%。此外,为了给你一个参考,sys.getsizeof(1)也是24字节。
顺便说一下,你没有提到
PicoSet。你是如何将其减少到24字节的,当一个带有slots的Python对象不能小于56字节吗?
简单:PicoSet基本上是NanoSet,但没有实现垃圾收集器协议。这为我们节省了32字节的对象内存,但有一个缺点:垃圾收集器无法看到分配在PicoSet内部的集合。这不会改变执行结果,但使用内存分析器进行调试会更困难。以下是一个示例,我们首先使用NanoSet分配了1,000,000个单例,然后使用PicoSet,使用guppy3来检查堆
>>> l = [nanoset.NanoSet({x}) for x in range(1000000)]
>>> guppy.hpy().heap()
Partition of a set of 3034170 objects. Total size = 328667393 bytes.
Index Count % Size % Cumulative % Kind (class / dict of class)
0 1000041 33 232100648 71 232100648 71 set
1 1000000 33 56000000 17 288100648 88 nanoset.NanoSet
...
3 96 0 8712752 3 324838712 99 list
...
>>> l = [nanoset.PicoSet({x}) for x in range(1000000)]
>>> guppy.hpy().heap()
Partition of a set of 2034285 objects. Total size = 300668995 bytes.
Index Count % Size % Cumulative % Kind (class / dict of class)
0 1000000 97 24000000 65 24000000 65 nanoset.PicoSet
1 96 0 8712752 24 32712752 89 list
...
在第二次运行时,分配的内存量大致相同,节省了28 MB(通过将NanoSet切换到PicoSet并乘以1,000,000个实例,节省了28字节)。然而,垃圾收集器并不知道一些内存在哪里,因为PicoSet隐藏了它分配的集合(这是可以的:它将与PicoSet一起释放)。
因此,我建议在调试时避免使用PicoSet,这可以通过Python的__debug__标志轻松实现
if __debug__:
from nanoset import NanoSet as set
else:
from nanoset import PicoSet as set
这将导致在带有-O标志运行Python时使用PicoSet而不是NanoSet。
📈 统计信息
好的,让我们来做一些数学计算。假设分配的集合大小为S = 232,包装器的大小为s(对于NanoSet为56,对于PicoSet为24),数据结构中非空集合的百分比为x,则我们集合的相对大小为
- 如果我们使用
set: S * x / (S * x) = 100%(我们将其用作参考) - 如果我们使用
nanoset: ((S + s) * x + s * (100 - x)) / (S * x)
这给出了以下图表,显示了根据运行时空集合的比例可以节省多少内存
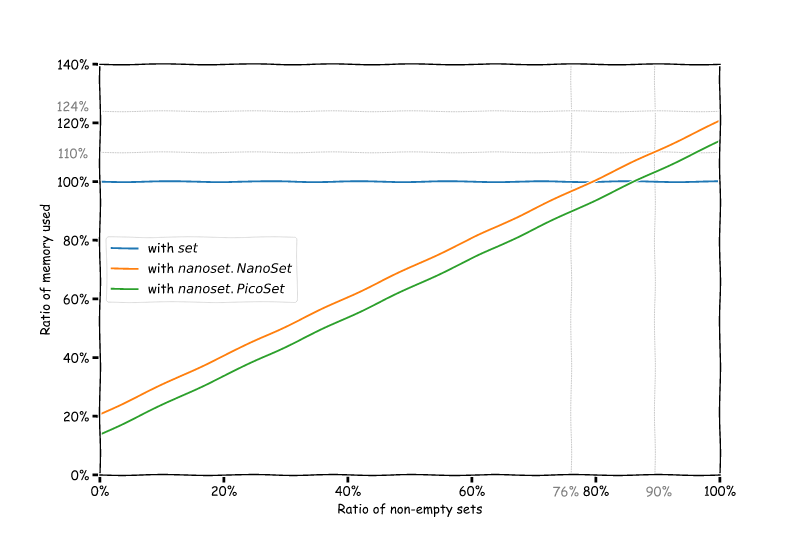
回到我们的NCBITaxon示例,我们有总共1,595,237个节点和1,130,671个叶子,这意味着通过使用集合,我们在整个分类加载后仅为了set就分配了1,595,237 * 232 = 353.0 MiB的内存。然而,如果我们使用NanoSet,我们可以将其减少到188.0 MiB,或者使用PicoSet甚至减少到139.3 MiB! 我们仅通过将NanoSet用于set就节省了大约50%的内存。
🔧 安装
此模块是用Rust编写的,但为以下平台编译了本机Python wheel
- Windows x86-64:CPython 3.5, 3.6, 3.7, 3.8
- Linux x86-64:CPython 3.5, 3.6, 3.7, 3.8
- OSX x86-64:CPython 3.5, 3.6, 3.7, 3.8
如果您的平台不在这之中,您将需要一个有效的Rust nightly工具链以及已安装的setuptools-rust库来构建扩展模块。
然后,只需使用pip进行安装
$ pip install --user nanoset
📖 API参考
嗯,这是一个针对 set 的综合封装器,因此您只需阅读 标准库文档。除了某些非常特殊的边缘情况外,NanoSet 和 PicoSet 都通过了 set 测试套件,该测试套件由 CPython 提供。
然而,有些事情您 不能 做
- 将
PicoSet或NanoSet作为子类。 - 将
PicoSet或NanoSet弱引用。 - 检查普通
set或frozenset的成员资格,并隐式转换为frozenset。 - 从
PicoSet或NanoSet创建dict 而不重新散列键。
📜 许可证
此库根据开源 MIT 许可证 提供。
依赖关系
~4MB
~89K SLoC