1个稳定版本
| 1.0.0 | 2019年11月8日 |
|---|
#1790 in 数据结构
1.5MB
29K SLoC
MQF

![]()
近似成员查询(AMQ)数据结构使用比实际数据大小更小的内存来近似表示数据。正如其名所示,AMQ回答特定元素是否存在于给定数据集中,但可能存在错误正误。AMQ有许多示例,例如布隆过滤器,计数-最小化草图,商过滤器和计数商过滤器(CQF)。在这里,我们提出一个新的AMQ数据结构,称为混合计数商过滤器(MQF)。
CQF将项的哈希位分为两个部分:商和剩余部分。商部分用于确定目标槽位。剩余部分被插入到目标槽位。插入算法使用线性探测的变体来解决冲突。CQF允许通过使用项的余数作为计数器来计数插入的实例的数量。CQF具有相对复杂的编码方案,以便可以区分计数器和项的余数。
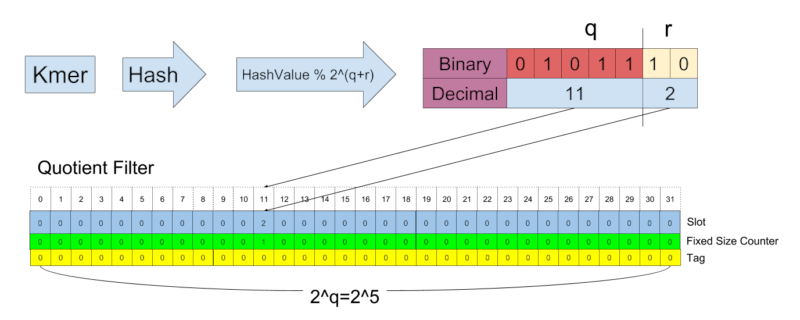
MQF,混合商过滤器,是CQF的变体。MQF使用与CQF相同的探测技术。MQF有更多的元数据,称为固定大小计数器,以及计数器的不同编码。这种改进使得mqf对于更广泛的zipifan分布具有更高的内存效率。
当一个项被插入多次时,MQF首先使用固定大小计数器来记录插入次数(count)。当固定大小计数器满时,MQF将计数存储在下一个槽位和固定大小的计数器中。MQF使用必要数量的槽位来存储计数。
换句话说,固定大小的计数器用于计数和标记用于计数的槽位。与同一项相关的所有槽位的固定大小计数器存储计数器的最大值,除了最后一个计数器应存储的最大值严格小于的值。当最后一个固定计数器的最大值达到时,会添加一个带有空固定大小计数器的新槽位。
优点
- MQF支持计数和删除项。MQF使用可变大小计数器;因此,当计数数据遵循zipfian分布时(大多数项只发生一次或两次,但少数项可以发生非常高的计数),它具有内存效率。
- MQF的每个元素比Bloom filter和Count-min sketches(参考)使用的位数更少。
- MQF具有良好的数据局部性,这使得它在运行在二级存储上时效率更高。
- MQF支持为项目添加/删除标签。
- MQF可以迭代以获取插入到过滤器中的项和计数。
- MQF支持合并功能。两个或多个过滤器可以合并为一个过滤器。
- MQF可以调整大小为更大的/更小的过滤器。
文档
构建
apt-get install make g++ cmake zlib1g-dev libbz2-dev
make NH=1
make test NH=1
./mqf_test
初始化
MQF初始化需要估计一些参数:槽位数量、键位、固定计数器大小和标签大小。
固定大小计数器大小根据数据分布的形状估计。如果大多数项都是单例。固定大小计数器应限制为1位。然而,如果一个大的部分的项目重复多次,较大的固定大小计数器将存储更多的计数,从而节省槽位。
槽位数量根据预期插入到过滤器中的项的数量估计。槽位用于插入项目的剩余部分哈希和计数。在计算所需槽位数量后,将结果乘以1.05,因为MQF不能填满其容量的超过95%。然后,将结果四舍五入到最接近的更大的2的幂。
键位等于log2(槽位数量)加上剩余部分位。剩余部分位根据以下公式从所需的精度估计。
![]()
标签大小容易估计。如果不需要标签,则可以将其设置为0。
- qf_init 初始化mqf。
void qf_init(QF *qf, uint64_t nslots, uint64_t key_bits, uint64_t label_bits,uint64_t fixed_counter_size, bool mem, const char *path, uint32_t seed);
- Qf* qf:过滤器的指针。
- uint64_t nslots:过滤器中的槽位数量。应该是2的幂。要插入的最大项目数取决于此数字。
- uint64_t key_bits:哈希值的位数。
- uint64_t label_bits:标签值的位数。
- uint64_t fixed_counter_size:固定计数器大小。必须大于0。
- bool mem:标志以在内存中创建过滤器。如果为false,则使用mmap。
- const char * path:在mmap的情况下。用于打包过滤器的文件的路径。
- uint32_t seed:无用的值。将要删除。
- qf_destroy
- estimate
支持的功能
- 插入:通过计数增加此项目的计数器。
bool qf_insert(QF *qf, uint64_t key,
uint64_t count,bool lock, bool spin);
- Qf* qf:过滤器的指针
- uint64_t key:要插入的项目的哈希值。
- uint64_t count:要添加的计数
- bool lock:对于多线程,锁定当前线程使用的*槽位,以便其他线程无法更改值
- bool spin:对于多线程,如果目标槽位上存在锁定。等待直到锁定释放并插入计数。
- 如果插入成功,则返回True。
- 计数:返回key被插入到qf的次数,无论值为何。
uint64_t qf_count_key(const QF *qf, uint64_t key);
- Qf* qf:过滤器的指针
- uint64_t key:要计数的项目的哈希值。
- 返回项目插入的次数。
- 删除:通过计数减少此项目的计数器。
bool qf_remove(QF *qf, uint64_t hash, uint64_t count, bool lock, bool spin);
- Qf* qf:过滤器的指针
- uint64_t key:要删除的项目的哈希值
- uint64_t count:要删除的计数
- bool lock:对于多线程,锁定当前线程使用的槽位,以便其他线程无法更改值
- bool spin:对于多线程,如果目标槽位上存在锁定。等待直到锁定释放并插入计数。
- 向元素添加/删除标签
uint64_t qf_add_label(const QF *qf, uint64_t key, uint64_t label, bool lock, bool spin);
uint64_t qf_get_label(const QF *qf, uint64_t key);
uint64_t qf_remove_label(const QF *qf, uint64_t key, bool lock, bool spin);
- Qf* qf:过滤器的指针
- uint64_t key : 项目的哈希值。
- uint64_t label: 项目的标签。
- bool lock:对于多线程,锁定当前线程使用的槽位,以便其他线程无法更改值
- bool spin:对于多线程,如果目标槽位上存在锁定。等待直到锁定释放并插入计数。
- Resize: 将过滤器调整为更大或更小的过滤器。
QF* qf_resize(QF* qf, int newQ, const char * originalFilename=NULL, const char * newFilename=NULL);
- Qf* qf:过滤器的指针
- uint64_t newQ: 新的槽位数量(Q)。将重新计算槽位大小以保持范围不变。
- string originalFilename(optional): 将当前过滤器存盘以为新过滤器腾出空间。文件名作为字符串内容提供。
- string newFilename(optional): 新过滤器在磁盘上创建。文件名作为字符串内容提供。
- 返回新过滤器的指针。
- Merge: 将多个过滤器合并成一个最终的过滤器。
void qf_merge(QF *qfa, QF *qfb, QF *qfc);
void qf_multi_merge(QF *qf_arr[], int nqf, QF *qfr);
- 可逆合并:可逆合并为普通合并提供额外的功能。可以针对每个键查询原始源过滤器。可逆合并函数为每个键添加标签并创建索引结构。索引是整数到整数向量的映射,其中整数是标签的值,整数向量是源过滤器的ID。
void qf_invertable_merge(QF *qf_arr[], int nqf, QF *qfr,std::map<uint64_t, std::vector<int> > *inverted_index_ptr);
- Qf* qf_arr : 过滤器输入数组。
- int nqf: 过滤器数量。
- QF* qfr: 输出过滤器的指针。
- map (uint64_t,vector(int) ) inverted_index_ptr: 输出索引的指针。
- Compare: 检查两个过滤器是否具有相同的项、计数和标签。
bool qf_equals(QF *qfa, QF *qfb);
- Intersect: 计算两个过滤器之间的交集。
void qf_intersect(QF *qfa, QF *qfb, QF *qfc);
- Subtract: 从第一个过滤器中减去第二个过滤器。
void qf_subtract(QF *qfa, QF *qfb, QF *qfc);
- Space: 返回插入项占用的空间百分比。
int qf_space(QF *qf);
其他函数
- 容量
- 复制
- 序列化/反序列化
- MMap读取