10 个版本 (6 个破坏性更新)
| 0.7.1 | 2024 年 4 月 17 日 |
|---|---|
| 0.7.0 | 2024 年 4 月 16 日 |
| 0.6.1 | 2024 年 4 月 2 日 |
| 0.5.1 | 2024 年 3 月 22 日 |
| 0.1.0 | 2024 年 2 月 23 日 |
#168 在 数据结构 中
每月下载量 3,843
87KB
1.5K SLoC
fastbloom
![]()
![]()
![]()
![]()
![]()
在 Rust 中速度最快的 Bloom 过滤器。无精度妥协。兼容任何哈希器。
概述
fastbloom 是一个在 Rust 中实现的 SIMD 加速 Bloom 过滤器。默认情况下,fastbloom 使用基于随机密钥的 SipHash-1-3 哈希器,但可以初始化或配置为使用任何哈希器。与现有的 Bloom 过滤器实现相比,fastbloom 的速度提高了 50-10000%。
使用方法
由于 0.7.x 中的不同(改进的!)算法,0.6.x 版本的 BloomFilter 的序列化和反序列化不兼容!
# Cargo.toml
[dependencies]
fastbloom = "0.7.1"
基本用法
use fastbloom::BloomFilter;
let mut filter = BloomFilter::with_num_bits(1024).expected_items(2);
filter.insert("42");
filter.insert("🦀");
使用目标错误正率进行实例化
use fastbloom::BloomFilter;
let filter = BloomFilter::with_false_pos(0.001).items(["42", "🦀"]);
assert!(filter.contains("42"));
assert!(filter.contains("🦀"));
使用任何哈希器
use fastbloom::BloomFilter;
use ahash::RandomState;
let filter = BloomFilter::with_num_bits(1024)
.hasher(RandomState::default())
.items(["42", "🦀"]);
背景
Bloom 过滤器是一种空间高效的大致成员集数据结构,由底层的位数组支持以跟踪项目成员资格。要插入/检查成员资格,会在基于项目哈希的位置设置/检查一定数量的位。从成员资格检查中可能存在错误正例,但不会出现错误负例。一旦构建完成,Bloom 过滤器的底层内存使用量以及每项的位数都不会改变。更多信息请参阅 这里。
hash(4) ──────┬─────┬───────────────┐
↓ ↓ ↓
0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 1 0
↑ ↑ ↑
└───────────┴───────────┴──── hash(3) (not in the set)
实现
fastbloom 比现有的 Bloom 过滤器快几倍,并且与每项的哈希数量具有很好的可扩展性。在所有情况下,fastbloom 都保持了具有竞争力的错误正率。由于它使用 L1 缓存友好的块、有效地从每个项目的“仅一个实际哈希”中推导出许多索引位、采用 SIMD 加速以及利用 Bloom 过滤器的其他研究成果,因此 fastbloom 非常快。
fastbloom 实现为一个部分阻塞布隆过滤器。阻塞布隆过滤器将底层位数组划分为子数组“块”。从项目哈希中设置和检查的位被限制在单个块内,而不是整个位数组。这允许更好地缓存效率,并在生成项目哈希的位时利用 SIMD 和 SWAR 操作。有关阻塞布隆过滤器的更多信息。fastbloom 的一半哈希索引跨越整个位数组,而其他索引则限制在单个块内。
运行时性能
fastbloom 比现有的 Rust 实现的布隆过滤器快 50-10000%。
SipHash
与其他使用 SipHash 的布隆过滤器crate的运行时比较。注意
- 所有布隆过滤器的哈希数量都经过优化以优化准确性,这意味着布隆过滤器中的项目越少,每个项目的哈希就越多,通常性能越慢。
- 随着项目数量(输入)的增加,布隆过滤器的准确性会降低。
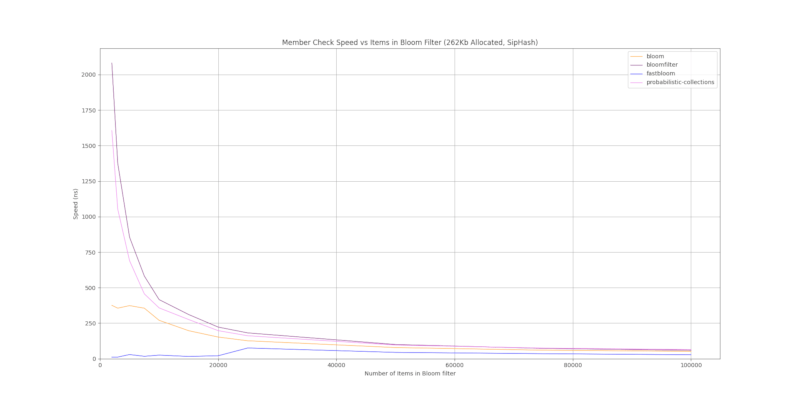
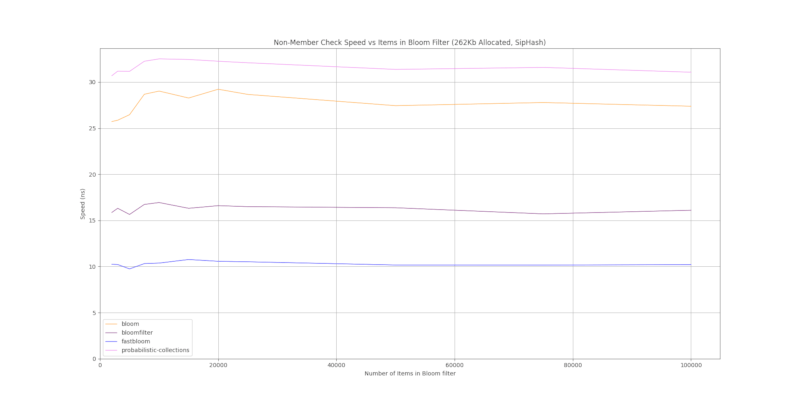
结果是基于 1000 个随机字符串的平均值
XXHash
这些crate使用xxhash。fastbloom 也配置为使用 xxhash。
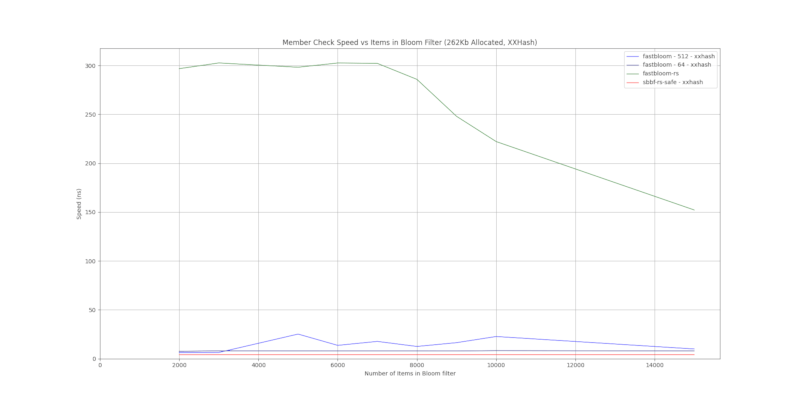
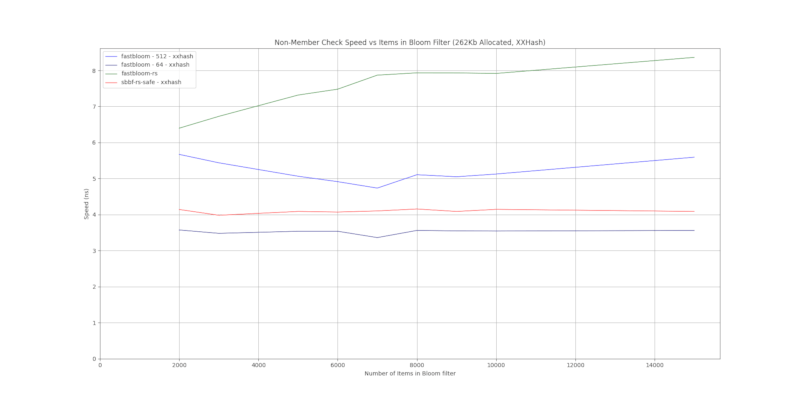
结果是基于 1000 个随机字符串的平均值。
sbbf-rs-safe 为每个项目硬编码 8 指数位,这解释了恒定和快速的性能,但如下一节“假阳性性能”所示,这会导致准确性降低。
假阳性性能
fastbloom 不妥协准确性。以下是与其他布隆过滤器crate的假阳性率比较
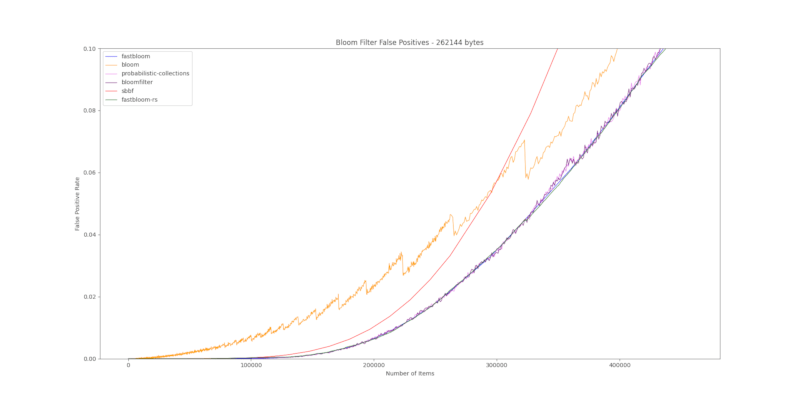
将布隆过滤器和控制哈希集填充了不同数量的随机 64 位整数(“项目数量”)。然后检查了 100,000 个随机 64 位整数:假阳性是那些不存在于控制哈希集中但在布隆过滤器中报告为存在的数字。
比较块大小
fastbloom 提供 4 种不同的块大小:64、128、256 和 512 位。
use fastbloom::BloomFilter;
let filter = BloomFilter::with_num_bits(1024).block_size_128().expected_items(2);
512 位是默认值。较大的块大小通常性能较慢,但准确性更高,例如,具有 64 位块的布隆过滤器非常快,但稍微不那么准确。
运行时性能
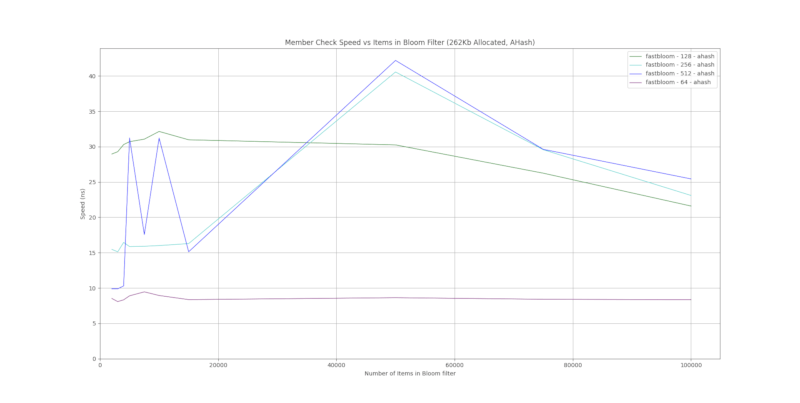
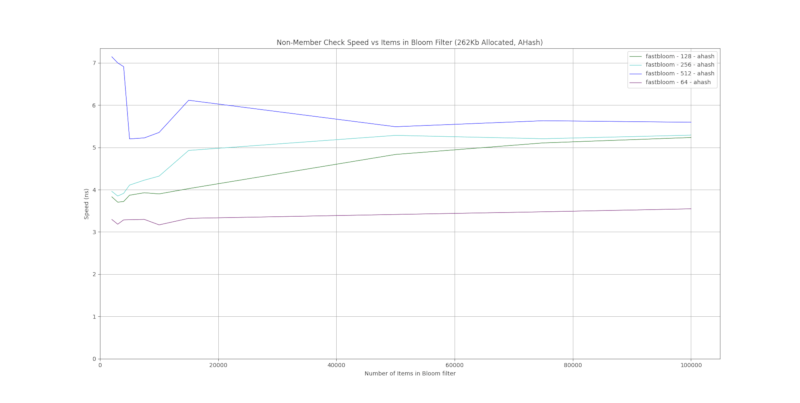
结果是基于 1000 个随机字符串的平均值。使用的布隆过滤器是 ahash。
准确性
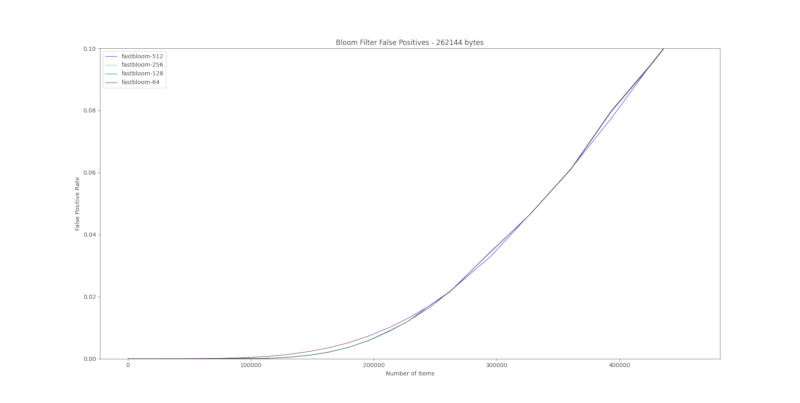
工作原理
fastbloom 将其性能归因于两个见解
- 每个项目只需要一个真实哈希,后续的哈希可以通过“哈希组合”便宜地导出
- 可以通过 SIMD 和 SWAR 类操作从几个后续哈希中导出许多位位置
每个项目一个真实哈希
fastbloom 在原始 64 位哈希的两个 32 位半部分上使用“哈希组合”。每个后续哈希都是通过将原始哈希值与不同的常数结合使用模运算和位运算来导出的。这产生了一系列实际上独立且均匀分布的哈希函数,尽管它们是从同一个原始哈希函数导出的。计算两个原始哈希的组合比重新计算具有不同种子的哈希要快。这种技术在 这篇论文中进行了深入解释。
从后续哈希中导出许多位位置
不是为每个哈希导出单个位位置,而是可以通过对后续哈希进行链式位与和位或操作来形成一个具有 ~N 个 1 位被设置的哈希。
示例
对于大小为64位的位向量 Bloom 过滤器和期望的24个哈希(可能重叠)的位置,每个项在插入或成员检查时分别设置或检查位向量中的位置。
其他传统的 Bloom 过滤器根据24个哈希值确定24个位置
hash0(item) % 64hash1(item) % 64- ...
hash23(item) % 64
相反,fastbloom使用“稀疏哈希”,这是一种预期设置少于32位位的组合哈希。在这种情况下,从项中导出一个约20位设置的稀疏哈希,并通过位或运算将其添加到位向量中
hash0(item) & hash1(item) | hash2(item) & hash3(item)
这是4个哈希值与24个哈希值!
注意
- 给定64位和24个哈希值,一个位在24次哈希后未设置的几率是 (63/64)^24,即0。一个项预期设置的位数是 64 - (64 * (63/64)^24) ~ = 20。
- 一个64位的
hash0(item)提供了大约32位设置的二项分布。hash0(item) & hash1(item)给出大约16位设置,hash0(item) | hash1(item)给出大约48位设置,等等。
实际上,Bloom 过滤器可能具有超过64位的存储空间。在这种情况下,块中的许多底层 u64 使用 SIMD 内部函数进行操作。哈希值的数量调整为块中每个 u64 的哈希值数量。此外,可能以传统方式在整个位向量中设置一些位,以弥补稀疏哈希的截断错误。这也降低了误报率并提高了非成员检查速度。
可用功能
rand- 默认启用,此功能使用thread_rng()从DefaultHasher获取随机状态,而不是使用硬件来源。从用户空间源获取熵要快得多,但需要额外的依赖项才能实现。使用default-features = false禁用此功能会使DefaultHasher使用getrandom获取熵,这将以牺牲速度为代价拥有更简单的代码。
参考文献
- Bloom 过滤器 - 维基百科
- Bloom 过滤器 - 精彩
- Bloom 过滤器交互式演示
- 缓存-哈希和空间高效 Bloom 过滤器
- 减少哈希,保持性能:构建更好的 Bloom 过滤器
- 快速替代模数减少
许可证
根据您的要求,许可方式为以下之一
- Apache 许可证2.0版本(LICENSE-APACHE 或 https://apache.ac.cn/licenses/LICENSE-2.0)
- MIT 许可证(LICENSE-MIT 或 https://open-source.org.cn/licenses/MIT)
任选其一。
贡献
除非您明确表示,否则您有意提交给工作并包含在内的任何贡献,根据 Apache-2.0 许可证的定义,将按上述方式双许可,不附加任何额外的条款或条件。
依赖项
~2MB
~37K SLoC