41个版本
| 0.8.6 | 2024年6月16日 |
|---|---|
| 0.8.4 | 2024年2月27日 |
| 0.8.3 | 2024年1月1日 |
| 0.8.2 | 2023年12月5日 |
| 0.2.1 | 2021年10月23日 |
#3 in 机器学习
175KB
3K SLoC

![]()
![]()
![]()
在云中高效实现模型服务。
简介
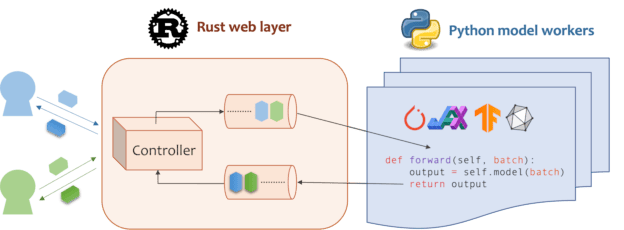
Mosec是一个高性能且灵活的模型服务框架,用于构建支持机器学习模型的后端和微服务。它弥合了您刚刚训练的任何机器学习模型和高效在线服务API之间的差距。
- 高性能:使用Rust 🦀 构建的Web层和任务协调,除了异步I/O提供的有效CPU利用率外,还提供了闪电般的速度
- 易于使用:纯Python 🐍 用户界面,用户可以使用与离线测试相同的代码以ML框架无关的方式提供他们的模型
- 动态批处理:聚合来自不同用户的请求进行批量推理,并将结果分发给用户
- 管道阶段:为管道阶段启动多个进程,以处理CPU/GPU/IO混合工作负载
- 云友好:设计用于在云中运行,具有模型预热、优雅关闭和Prometheus监控指标,可由Kubernetes或任何容器编排系统轻松管理
- 专注于一项任务:专注于在线服务部分,用户可以关注模型优化和业务逻辑
安装
Mosec需要Python 3.7或更高版本。使用以下命令安装最新版本的PyPI软件包
pip install -U mosec
# or install with conda
conda install conda-forge::mosec
要从源代码构建,安装 Rust 并运行以下命令
make package
您将在 dist 文件夹中获得一个mosec wheel文件。
用法
我们展示了Mosec如何帮助您轻松地将预训练的稳定扩散模型作为服务托管。您需要安装 diffusers 和 transformers 作为先决条件
pip install --upgrade diffusers[torch] transformers
编写服务器
点击此处获取带解释的服务器代码。
首先,我们导入库并设置一个基本的日志记录器,以便更好地观察发生了什么。
from io import BytesIO
from typing import List
import torch # type: ignore
from diffusers import StableDiffusionPipeline # type: ignore
from mosec import Server, Worker, get_logger
from mosec.mixin import MsgpackMixin
logger = get_logger()
然后,我们构建一个API,供客户端查询文本提示,并基于stable-diffusion-v1-5模型在3个步骤内获取图像。
-
将您的服务定义为一个类,该类继承自
mosec.Worker。在这里,我们还继承MsgpackMixin来使用msgpack序列化格式(a)。 -
在
__init__方法内部,初始化您的模型并将其放置到相应的设备上。可选地,您可以将self.example分配一些数据来预热(b)模型。请注意,数据应与您的处理器的输入格式兼容,我们将在下面详细说明。 -
重写
forward方法来编写您的服务处理器(c),签名如下:forward(self, data: Any | List[Any]) -> Any | List[Any]。接收/返回单个项或元组取决于是否配置了动态批量处理(d)。
class StableDiffusion(MsgpackMixin, Worker):
def __init__(self):
self.pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16
)
device = "cuda" if torch.cuda.is_available() else "cpu"
self.pipe = self.pipe.to(device)
self.example = ["useless example prompt"] * 4 # warmup (batch_size=4)
def forward(self, data: List[str]) -> List[memoryview]:
logger.debug("generate images for %s", data)
res = self.pipe(data)
logger.debug("NSFW: %s", res[1])
images = []
for img in res[0]:
dummy_file = BytesIO()
img.save(dummy_file, format="JPEG")
images.append(dummy_file.getbuffer())
return images
[!NOTE]
(a) 在此示例中,我们以二进制格式返回图像,JSON不支持(除非使用base64编码,这会使有效载荷更大)。因此,msgpack更适合我们的需求。如果我们不继承
MsgpackMixin,则默认使用JSON。换句话说,服务请求/响应的协议可以是msgpack、JSON或任何其他格式(请参阅我们的混合)。(b) 预热通常有助于提前分配GPU内存。如果指定了预热示例,则服务将在示例通过处理器转发后才能准备就绪。然而,如果没有提供示例,则第一个请求的延迟预期会更长。《code>example应根据
forward期望接收的内容设置为单个项或元组。此外,如果您想要使用多个不同的示例进行预热,则可以设置multi_examples(示例见此处)。(c) 此示例显示了一个单阶段服务,其中
StableDiffusion工作直接接收客户端的提示请求并响应图像。因此,forward可以被视为完整的服务处理器。但是,我们也可以设计多阶段服务,其中工作在不同阶段的作业(例如,下载图像、模型推理、后处理)在管道中执行。在这种情况下,整个管道被视为服务处理器,第一个工作接收请求,最后一个工作发送响应。工作之间的数据流通过进程间通信完成。(d) 在本例中启用了动态批处理,因此
forward方法将希望接收一个字符串 列表,例如,['a cute cat playing with a red ball', 'a man sitting in front of a computer', ...],这是从不同的客户端聚合用于 批推理 的,从而提高了系统吞吐量。
最后,我们将工作进程添加到服务器中,构建一个 单阶段 工作流程(可以通过 流水线 将多个阶段进一步串联以提高吞吐量,见 此示例),并指定并行运行的进程数(num=1),以及最大批处理大小(max_batch_size=4,动态批处理在超时之前将累积的最大请求数量;超时通过 max_wait_time=10(毫秒)定义,这意味着 Mosec 等待将批处理发送给 Worker 的最长时间)。
if __name__ == "__main__":
server = Server()
# 1) `num` specifies the number of processes that will be spawned to run in parallel.
# 2) By configuring the `max_batch_size` with the value > 1, the input data in your
# `forward` function will be a list (batch); otherwise, it's a single item.
server.append_worker(StableDiffusion, num=1, max_batch_size=4, max_wait_time=10)
server.run()
运行服务器
点击此处查看如何运行和查询服务器。
上述片段已合并到我们的示例文件中。您可以直接在项目根目录下运行。我们首先查看 命令行参数(解释见 此处)
python examples/stable_diffusion/server.py --help
然后以调试日志启动服务器
python examples/stable_diffusion/server.py --log-level debug --timeout 30000
在浏览器中打开 http://127.0.0.1:8000/openapi/swagger/ 以获取 OpenAPI 文档。
然后在另一个终端中测试它
python examples/stable_diffusion/client.py --prompt "a cute cat playing with a red ball" --output cat.jpg --port 8000
您将在当前目录中获得一个名为 "cat.jpg" 的图像。
您可以检查指标
curl http://127.0.0.1:8000/metrics
这就完成了!您刚刚将您的 stable-diffusion 模型 作为服务托管!😉
示例
更多现成示例可以在 示例 部分找到。它包括
- 流水线:一个简单的无任何 ML 模型的回显演示。
- 请求验证:使用类型注解验证请求。
- 多路由:在一个服务中提供多个模型。
- 嵌入服务:与 OpenAI 兼容的嵌入服务。
- 重排序服务:根据查询重排序一系列段落。
- 共享内存 IPC:使用共享内存进行进程间通信。
- 自定义 GPU 分配:部署多个副本,每个副本使用不同的 GPU。
- 自定义指标:记录您自己的指标以进行监控。
- Jax jitted 推理:即时编译加速推理。
- PyTorch 深度学习模型
配置
- 动态批处理
- 在调用
append_worker时配置max_batch_size和max_wait_time (毫秒)。 - 确保使用
max_batch_size值进行推理时不会导致 GPU 内存溢出。 - 通常情况下,
max_wait_time应该小于批量推理时间。 - 如果启用,则在累积请求数量达到
max_batch_size或max_wait_time已经过去时,会收集一个批次。在流量高峰时,该服务将受益于此功能。
- 在调用
- 有关其他配置,请参阅参数文档。
部署
- 如果您正在寻找已安装
mosec的 GPU 基础镜像,可以查看官方镜像mosecorg/mosec。对于复杂用例,请参阅envd。 - 此服务不需要 Gunicorn 或 NGINX,但在必要时当然可以使用入口控制器。
- 由于它控制多个进程,因此此服务应该是容器中的 PID 1 进程。如果您需要在单个容器中运行多个进程,则需要一个监督器。您可以选择Supervisor 或 Horust。
- 请记住收集 指标。
mosec_service_batch_size_bucket显示批量大小的分布。mosec_service_batch_duration_second_bucket显示每个阶段(从接收第一个任务开始)中每个连接的动态批处理持续时间。mosec_service_process_duration_second_bucket显示每个阶段中每个连接的处理持续时间(包括 IPC 时间,但不包括mosec_service_batch_duration_second_bucket)。mosec_service_remaining_task显示当前正在处理的任务数量。mosec_service_throughput显示服务吞吐量。
- 由于具有优雅的关闭逻辑,请使用
SIGINT(CTRL+C)或SIGTERM(kill {PID})停止服务。
性能调整
- 找出适合您的推理服务的最佳
max_batch_size和max_wait_time。指标将显示实际批大小和批处理持续时间的直方图。这些是调整这两个参数的关键信息。 - 尝试将整个推理过程分成独立的 CPU 和 GPU 阶段(参考 DistilBERT)。不同的阶段将在 数据管道 中运行,这将保持 GPU 忙碌。
- 您还可以调整每个阶段的工人数。例如,如果您的管道由一个用于预处理的 CPU 阶段和一个用于模型推理的 GPU 阶段组成,则增加 CPU 阶段工人的数量可以帮助在 GPU 阶段生成更多要批量处理的数据;增加 GPU 阶段工人的数量可以充分利用 GPU 内存和计算能力。这两种方法都可能有助于提高 GPU 利用率,从而提高服务吞吐量。
- 对于多阶段服务,请注意,通过不同阶段传递的数据将由
serialize_ipc/deserialize_ipc方法进行序列化/反序列化,因此非常大的数据可能会使整个管道变慢。默认情况下,序列化数据通过 rust 传递到下一阶段,您可以通过启用共享内存来潜在地降低延迟(参考 RedisShmIPCMixin)。 - 您应选择适当的
序列化//反序列化方法,这些方法用于解码用户请求并编码响应。默认情况下,两者都使用 JSON。然而,JSON 对图像和嵌入物的支持并不好。您可以选择 msgpack,它速度更快且与二进制兼容(参考 Stable Diffusion)。 - 配置 OpenBLAS 或 MKL 的线程。它可能无法选择当前 Python 进程使用的最合适的 CPU。您可以通过使用 环境变量(参考 自定义 GPU 分配)为每个工作进程进行配置。
采用者
以下是使用 Mosec 的一些公司和个人用户
- Modelz:ML 推理的无服务器平台。
- MOSS:类似于 ChatGPT 的开源对话语言模型。
- 腾讯云:腾讯云机器学习平台,使用 Mosec 作为 核心推理服务器框架。
- TensorChord:云原生 AI 基础设施公司。
引用
如果您发现此软件对您的研究有用,请考虑引用
@software{yang2021mosec,
title = {{MOSEC: Model Serving made Efficient in the Cloud}},
author = {Yang, Keming and Liu, Zichen and Cheng, Philip},
url = {https://github.com/mosecorg/mosec},
year = {2021}
}
贡献
我们欢迎任何形式的贡献。请通过 提出问题 或在 Discord 上讨论来给我们反馈。您还可以直接 贡献 代码和拉取请求!
要开始开发,您可以使用 envd 创建一个隔离且干净的 Python & Rust 环境。有关更多信息,请查看 envd 文档 或 build.envd。
依赖关系
~12–23MB
~303K SLoC