6 个版本
| 0.11.5 | 2021年10月21日 |
|---|---|
| 0.11.4 | 2021年2月7日 |
| 0.11.2 | 2020年5月19日 |
#209 in 进程宏
250KB
2.5K SLoC
modus_ponens.
内容
简介
modus_ponens 是一个内存数据存储,其中数据的结构(包括数据库模式和查询)由一个 解析表达式语法(PEG) 提供。因此,定义PEG的语言在RDBMS中取代了SQL。例如,JSON可以通过PEG定义;因此,如果我们为modus_ponens提供JSON的PEG,我们就可以创建JSON存储库,并使用JSON查询从中提取任何特定信息。请注意,我们不是提供任何特定的JSON模式,只是JSON。
除了存储数据之外,modus_ponens 还提供了一个规则引擎(一个 前向链 推理引擎),通过它可以对显式存储的数据进行整理和组合,以实现数据智能。这些规则的语法是混合的,部分由 modus_ponens (逻辑连接词:合取和蕴涵,以及全称量词变量)规定,部分由用户(规则中的条件和结果对应于数据查询的语法)提供。
我们可以从不同的传统、成熟的视角来理解 modus_ponens
- 可以从(外部)领域特定语言(DSL)的角度来考虑。可以将 modus_ponens 看作是一个 DSL 引擎,其中用户通过PEG指定语言的语法,而 modus_ponens 则添加了生成根据提供的PEG形成的条件和结果的规则的能力;
- 可以从知识表示和推理(KRR)的角度来考虑;
- 可以从逻辑编程的角度来理解 modus_ponens,并将其与 CLIPS 或 Jess(或者甚至 Prolog,尽管 Prolog 是反向链)进行比较;
- 它也可以被视为数据分析工具,与SQL引擎和其他数据结构方案进行比较。从这个意义上说,我们可能会回想起JSON存储的初始示例,并考虑在SQL中定义JSON的难度,并将其与定义PEG中的JSON进行比较;
- 它可以与业务规则管理系统背后的规则引擎(如Drools或JRules)进行比较。
我已经将modus_ponens的性能与几款工具进行了比较(到目前为止,与CLIPS和内存中的SQLite),它们处于同一级别,各自具有某些优势和劣势,这取决于数据的形状和查询。
待办事项:添加待完成的工作,为每个提供的视角提供完成的工具。
从DSL的角度来看。
modus_ponens可以被视为生成DSL的工具。使用模型驱动工程的术语,可以说modus_ponens是元模型,由PEG引擎和逻辑连接词及变量的实现组成。然后,modus_ponens加上一个特定的PEG对应于一个模型,建立在给定PEG之上的知识库对应于原始模型。这意味着可以从中作为元模型推导出的模型空间仅受PEG描述语言的限制,从而使modus_ponens成为一个真正的强大DSL引擎。
从KRR的角度来看。
由于任何结构化语言都可以用PEG描述,实际上,modus_ponens可以以任何可能的形式保存结构化的知识,因此,它允许用户以最有效的方式表示任何类型的知识,并施加适当的规则来进行推理。
从逻辑编程的角度来看。
如果我们从逻辑编程的角度来看,并将其与CLIPS编程语言(也是一个正向链引擎)进行比较,我们可能会注意到:
- 速度快。当系统中加载了数百或数千条规则时,它与CLIPS的速度相当,而当有数十万甚至数百万条规则时,它比CLIPS快得多(例如,当系统中存在200,000条规则时,modus_ponens在添加另一个规则时比CLIPS快4个数量级,详见下文的结果)。
- 可定制。向modus_ponens生成的推理引擎提供的语法事实是自由的,因为这种语法是由用户以PEG的形式提供的。
- 可扩展。添加新事实和新规则到系统中的算法成本(时间和空间)与已经存在的数量有很大独立性。(见下文的一些基准测试)。在这方面,必须指出,它使用了一种新颖的算法,与RETE算法(CLIPS和大多数业务规则系统背后的算法)几乎没有相似之处。
从数据分析的角度来看。
modus_ponens可以帮助处理数据。这里的要点是,没有必要将数据转换为将其输入到modus_ponens中;只需为modus_ponens提供一个描述要分析的数据结构的PEG即可,然后数据可以直接添加到modus_ponens知识库中。然后可以在知识库中添加规则或查询任何指定在PEG中的结构细节级别。
例如,为了分析和从一组日志中提取信息,PEG将规定反映日志条目结构的事实,然后每个日志条目都会被作为事实输入到知识库中。
推理引擎
推理引擎的简要介绍,以建立一些术语的共同基础。
推理机处理两种基本类型的对象:事实和规则。在正向链接系统中,这些对象的根本操作语义有三层
- 事实和规则由用户添加到系统中;
- 事实可以与规则匹配,从而产生用户未直接提供的新事实(或等价地,触发某些其他任意操作);
- 系统可以根据某种查询语言查询事实的存在。
正向链接推理机的流行例子包括CLIPS中的那个,或者Drools业务规则管理系统背后的那个。
不同的引擎为它们的事实提供不同的语法。例如,CLIPS使用Lisp样式的s表达式,而Drools使用一些自定的专用语法。
规则基本上由一组条件和动作组成,其中条件是可以包含量化、有界变量的事实,动作可以在规则的条件匹配时触发任何操作;尽管在这里,为了我们的目的,我们只考虑将新事实的断言作为动作,这些事实可能包含条件中使用的变量(并在断言中用匹配提供的赋值替换)。
从逻辑角度来看,这些系统提供的是,首先,事实和Horn子句的语法;然后,在此基础上,实现 conjunction(合取)、implication(蕴涵)和量化变量,就像它们出现在Horn子句中一样。这使得这些系统能够根据modus ponens扩展任何事实和Horn子句集到其完备集。
modus_ponens
modus_ponens提供的是逻辑合取和蕴涵以及量化变量的实现,并且它是基于PEG解析树,而不是某些特定的事实合取、蕴涵或包含变量的语法。对于modus_ponens,一个事实就是由Pest PEG解析器产生的解析树。因此,库的用户可以提供任何她选择的PEG来定义她的事实空间。在某种意义上,库的用户提供了事实的语法,而modus_ponens提供了从这些事实构建规则的语法。作为modus_ponens规定的内容和用户即兴创作的桥梁,用户需要标记哪些组成她的事实的生产可以落在modus_ponens规定的变量的范围内。否则,提供事实的生产结构没有限制。
示例
例如,我们将开发一个表示简单分类学的系统。在这个系统中,句子有两种基本形式
- 分类A是分类B的子分类
- 个体A属于分类B
我们希望系统提供我们分类学的完整视图;所以,例如,如果我们告诉系统Bobby属于狗,并且狗是哺乳动物的子分类,然后我们查询系统中的哺乳动物,我们希望获得Bobby作为响应。为此,我们将添加两条规则
- A是B的子分类且B是C的子分类 -> A是C的子分类
- A属于B且B是C的子分类 -> A属于C
首先,我们必须向我们的Cargo.toml添加一些依赖项
[dependencies]
modus_ponens = "0.11.3"
modus_ponens_derive = "0.1.1"
pest = "2.1.3"
pest_derive = "2.1.0"
log = "0.4"
env_logger = "0.7.1"
现在,语法部分。这个语法是由Pest解释的,所以请查阅Pest文档了解其语法。由于我们可以使用Unicode字符,我们将这样做。对于“子分类”谓词,我们将使用⊆,而对于属于,使用∈。我们还需要为个体和分类命名,我们将使用小写拉丁字母的字符串。
var = @{ "<" ~ "__"? ~ "X" ~ ('0'..'9')+ ~ ">" }
fact = { name ~ pred ~ name }
pred = @{ "∈" | "⊆" }
v_name = @{ ASCII_ALPHANUMERIC+ }
name = _{ v_name | var }
WHITESPACE = { " " | "\t" | "\r" | "\n" }
在这个语法中,WHITESPACE和var的产生式由modus_ponens指定。在它们之上,用户必须提供一个fact的产生式。因此,作为“用户”,我们提供name、v_name和pred,以组成fact。在这里,我们允许非常简单的命题,即主语-谓语-宾语的三元组。
注意我们如何标记可以匹配变量的产生式v_name,前面加上前缀“v_”,并将其与var混合在另一个name产生式中。我们称之为逻辑产生式。在这种情况下,v_name是一个终端产生式,但它不必是;并且可以有多个标记为逻辑的产生式。因此,可以完美地表示高阶逻辑。
我们将这个语法存储在一个名为grammar.pest的文件中。
然后,我们根据这个语法构建我们的知识库。首先是一些模板代码
extern crate modus_ponens;
#[macro_use]
extern crate modus_ponens_derive;
extern crate pest;
#[macro_use]
extern crate pest_derive;
#[derive(KBGen)]
#[grammar = "grammar.pest"]
pub struct KBGenerator;
这为我们提供了一个struct KBgenerator,其唯一职责是创建能够根据grammar.pest存储事实和规则的知识库。因此,我们可以构建一个知识库
let kb = KBGenerator::gen_kb();
我们可以向其中添加规则
kb.tell("<X0> ⊆ <X1> ∧ <X1> ⊆ <X2> → <X0> ⊆ <X2>.");
kb.tell("<X0> ∈ <X1> ∧ <X1> ⊆ <X2> → <X0> ∈ <X2>.");
添加一些内容
kb.tell("human ⊆ primate.");
kb.tell("primate ⊆ animal.");
kb.tell("susan ∈ human.");
然后查询系统
assert_eq!(kb.ask("susan ∈ animal."), true);
assert_eq!(kb.ask("susan ⊆ animal."), false);
assert_eq!(kb.ask("primate ∈ animal."), false);
这完成了对modus_ponens的第一种方法的尝试。要尝试此示例中的代码,您可以按照以下步骤操作
$ git clone <modus_ponens mirror>
$ cd modus_ponens/examples/readme-example
$ cargo build --release
$ RUST_LOG=trace ./target/release/readme-example
RUST_LOG=trace将记录系统中添加的所有事实和规则到stdout;RUST_LOG=info将只记录事实。
API
使用此库有三个步骤:提供语法、使用语法构建知识库,以及向知识库中添加和检索数据。
语法
modus_ponens中的语法由Pest解释,所以请查阅Pest文档了解其语法。
modus_ponens语法必须提供一个顶级产生式称为fact。原则上,事实可以具有任何可能的结构,即,它们可以由任何数量的终端或非终端子产生式构建。
modus_ponens为事实提供了一个终止符号◊,所以要将事实添加到知识库中,您可以使用类似以下字符串:
<fact1> ◊
modus_ponens还提供了将事实组合成规则的符号;它提供了∧表示合取,以及→表示蕴涵。因此,一个规则可能如下所示:
<fact1> ∧ <fact2> → <fact3> ◊
在规则中可以使用逻辑变量,既在条件中也在结论中。变量的形式可以自定义,但默认是由小于号、一个大写字母、任何数量的小写字母或数字以及大于号组成。例如,<Var1>,或者<X2>。
要使用变量,用户需要标记位于变量范围内的生成式,在modus_ponens中称为逻辑生成式。为此,逻辑生成式的名称必须以v_开头,然后与var生成式混合使用。例如:
v_name = @{ ASCII_ALPHANUMERIC+ }
var_range = _{ v_name | var }
在规则中还可以添加所谓的非逻辑条件,这些条件通过使用多个数值或字符串谓词来测试算术或字符串条件(待办:列出可用的谓词)。这些条件被包围在{?{和}?}之间。
在规则中还可以添加转换,包括算术和字符串转换,这些转换被包围在{={和}=}之间,使用字符串和数值运算符(待办:列出所有可用的运算符)。我们使用转换来从逻辑条件匹配的值中获得新值。
最后,还可以添加生成新规则的规则(而不是仅生成新事实)。这可以通过在规则中使用多个蕴涵符号简单地实现,例如:
<fact1> ∧ <fact2> → <fact3> → <fact4> ◊
一旦匹配到事实<fact1>和<fact2>,将添加规则<fact3> → <fact4>◊,其中任何在<fact1>和<fact2>中绑定的变量都将用匹配的值替换。
构建知识库
开发了一种语法后,库的用户将希望在它之上构建知识库。这只需要一点样板代码。
extern crate modus_ponens;
#[macro_use]
extern crate modus_ponens_derive;
extern crate pest;
#[macro_use]
extern crate pest_derive;
#[derive(KBGen)]
#[grammar = "path/to/grammar.pest"]
pub struct KBGenerator;
let kb = KBGenerator::gen_kb();
"path/to/gammar.pest"相对于项目的src/目录是相对的。
使用知识库。
modus_ponens知识库有2个方法,tell和ask。tell方法接收一个包含事实和/或规则的字符串切片,并将它们放入其内部树中。ask方法接收一个可能包含变量的事实,并返回True或False(如果查询不包含变量),或变量赋值的向量(如果查询包含变量)。在后一种情况下,空向量表示否定响应。
复杂性
我们认为,在正向链推理引擎中,最先进的技术是RETE算法变体的实现,具有不同类型的启发式改进,但基本复杂性没有显著变化。我们使用CLIPS 6.30作为RETE的参考实现,由PyCLIPS管理。有CLIPS 6.31和6.4beta,但根据它们的变更日志,这些新版本没有算法改进,将改变下面的结果,PyCLIPS对于基准测试CLIPS非常方便——并且只了解CLIPS 6.30。
现在,使用modus_ponens,向系统中添加一个新事实(或规则)的成本仅取决于所添加的事实(或规则的条件的语法复杂性),以及与事实匹配的规则数量(或添加规则时匹配规则条件的事实数量)。特别是,这些成本与系统中事实的总数和规则的总数无关。
这是因为系统中表示事实和规则集的结构中的所有搜索都是通过哈希表查找完成的;没有涉及任何单个过滤迭代节点。
对于RETE来说并非如此:在RETE中,添加事实或规则的成本会随着系统中规则总数的增加而增加。至少,下方的数字显示是这样的。Doorenboss在他的论文中将一个多项式于事实数量(WMEs)且小于线性于规则数量的高效匹配算法设定为目标。他声称这是可以通过他的RETE/UL对RETE的增强来实现的。我在CLIPS中观察到的是与事实数量无关且与规则数量线性相关的性能。
下方的基准测试包括添加200,000条规则和600,000个事实,其中每2条规则会被6个事实匹配以产生4个额外的断言。每添加1000条规则,我们就会测量添加更多规则和事实的时间成本。我们展示了3次运行的结果。每次运行modus_ponens大约需要2分钟,而CLIPS在我的i5-8250U @1.60GHz笔记本电脑上大约需要7小时。这是CLIPS基准测试的代码和这是modus_ponens的代码。
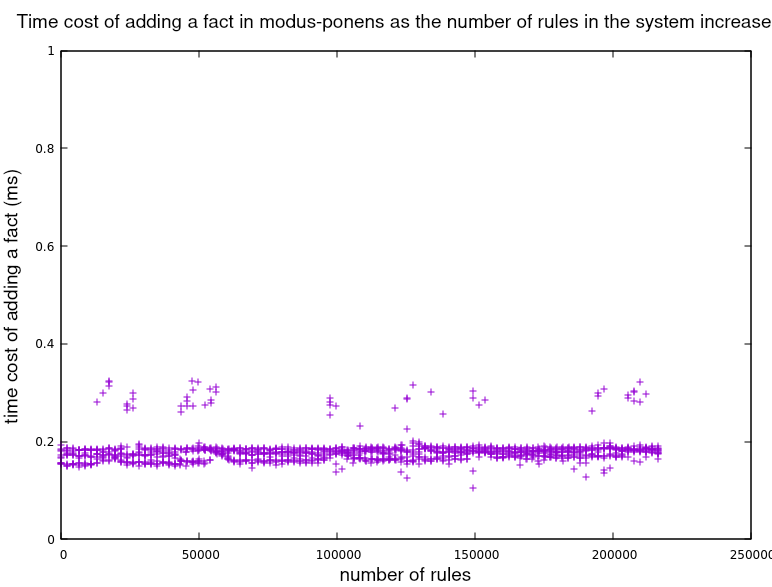
首先我们看到系统处理每个新事实所需的时间随着系统中规则数量的增加而变化。CLIPS显示成本似乎不断增加,而modus_ponens对每个事实持续花费相同的时间。
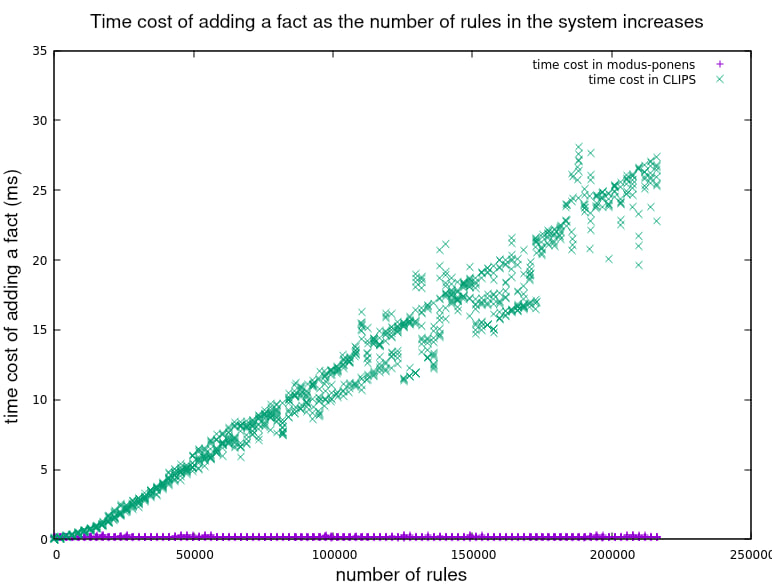
放大modus_ponens数据
我们没有绘制的某些结果提供了证据,表明在维持规则数量的同时,增加系统中的事实数量对添加新事实或规则的成本没有影响,对于任何系统都是如此。事实上,在modus_ponens的情况下,上述图表可以被视为成本不依赖于事实数量的证据,因为事实的数量随着规则的数量的增加而增加。
接下来的结果显示了增加规则总数对添加新规则成本的影响。同样,在CLIPS中,成本似乎持续增加,而在modus_ponens中,成本似乎与规则数量无关。
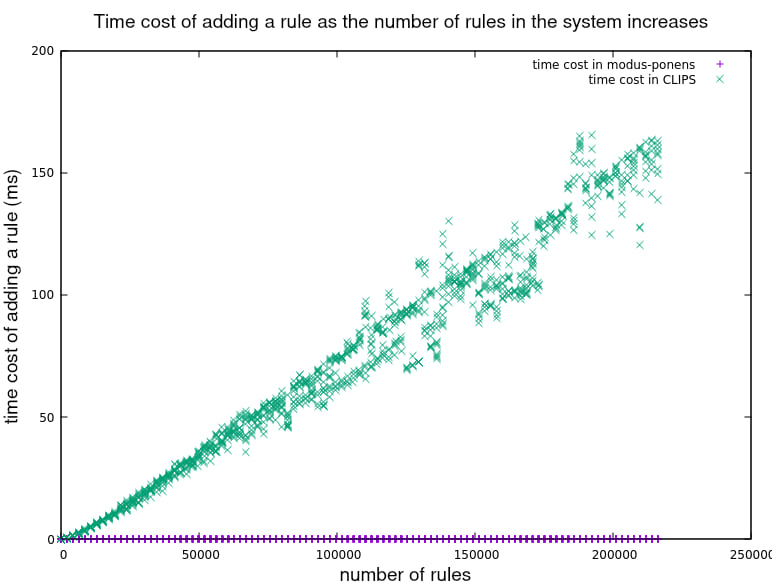
放大modus_ponens数据
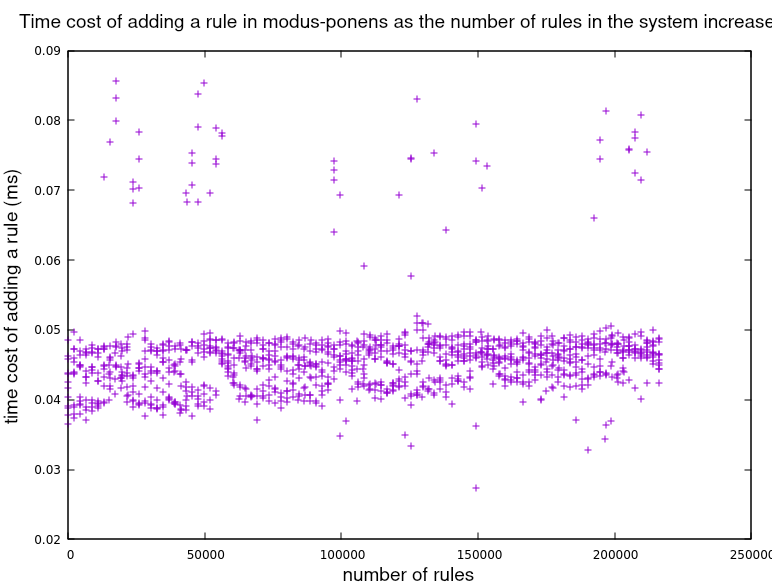
值得注意的是,与CLIPS相反,在modus_ponens中添加规则比添加事实便宜得多。
我还使用heaptrack测量了进程分配的峰值内存,使用了不同数量的事实和规则。我没有足够的数据来绘制它,但初步结果表明,每个事实的空间成本约为1KB,与系统中事实和规则的数量无关。在这方面还有改进的空间,因为1KB/事实远远超过了严格需要的量。
© Enrique Pérez Arnaud <enrique at cazalla.net> 2021
依赖关系
~5–14MB
~174K SLoC