5 个版本
| 0.8.5 | 2022年5月18日 |
|---|---|
| 0.8.4 | 2022年3月15日 |
| 0.8.3 | 2022年3月10日 |
| 0.8.2 | 2021年10月4日 |
| 0.8.0 | 2021年9月3日 |
#422 在 编码
1,427,698 每月下载量
在 570 个crate中使用 (通过 lexical-core)
1MB
14K SLoC
lexical
用于在 no_std 环境中的高性能数值转换例程。这不需要任何标准库功能,也不需要系统分配器。
类似项目
如果您想要lexical的浮点解析算法的最小、稳定和编译时友好的版本,请参阅 minimal-lexical。如果您想要一个最小、性能良好的浮点解析器,Rust标准库的较新版本应该足够 足够。
目录
入门
将lexical添加到您的 Cargo.toml
[dependencies]
lexical = "^6.0"
开始使用lexical
// Number to string
use lexical_core::BUFFER_SIZE;
let mut buffer = [b'0'; BUFFER_SIZE];
lexical_core::write(3.0, &mut buffer); // "3.0", always has a fraction suffix,
lexical_core::write(3, &mut buffer); // "3"
// String to number.
let i: i32 = lexical_core::parse("3")?; // Ok(3), auto-type deduction.
let f: f32 = lexical_core::parse("3.5")?; // Ok(3.5)
let d: f64 = lexical_core::parse("3.5")?; // Ok(3.5), error checking parse.
let d: f64 = lexical_core::parse("3a")?; // Err(Error(_)), failed to parse.
为了在泛型代码中使用lexical,提供了 FromLexical (用于 parse) 和 ToLexical (用于 to_string) 特征约束。
/// Multiply a value in a string by multiplier, and serialize to string.
fn mul_2<T>(value: &str, multiplier: T)
-> Result<String, lexical_core::Error>
where
T: lexical_core::ToLexical + lexical_core::FromLexical,
{
let value: T = lexical_core::parse(value.as_bytes())?;
let mut buffer = [b'0'; lexical_core::BUFFER_SIZE];
let bytes = lexical_core::write(value * multiplier, &mut buffer);
Ok(std::str::from_utf8(bytes).unwrap())
}
部分/完整解析器
Lexical既有部分解析器也有完整解析器:完整解析器确保在解析时使用整个缓冲区,而不忽略尾随字符,而部分解析器解析尽可能多的字符,返回解析值和解析的数字数量。遇到错误时,lexical将返回一个错误,指示错误类型和缓冲区内部发生错误的索引。
完整解析器
// This will return Err(Error::InvalidDigit(3)), indicating
// the first invalid character occurred at the index 3 in the input
// string (the space character).
let x: i32 = lexical_core::parse(b"123 456")?;
部分解析器
// This will return Ok((123, 3)), indicating that 3 digits were successfully
// parsed, and that the returned value is `123`.
let (x, count): (i32, usize) = lexical_core::parse_partial(b"123 456")?;
no_std
lexical-core 依赖于标准库,也不依赖于系统分配器。要在 no_std 环境中使用 lexical-core,请将以下内容添加到 Cargo.toml
[dependencies.lexical-core]
version = "0.8.5"
default-features = false
# Can select only desired parsing/writing features.
features = ["write-integers", "write-floats", "parse-integers", "parse-floats"]
开始使用lexical
// A constant for the maximum number of bytes a formatter will write.
use lexical_core::BUFFER_SIZE;
let mut buffer = [b'0'; BUFFER_SIZE];
// Number to string. The underlying buffer must be a slice of bytes.
let count = lexical_core::write(3.0, &mut buffer);
assert_eq!(buffer[..count], b"3.0");
let count = lexical_core::write(3i32, &mut buffer);
assert_eq!(buffer[..count], b"3");
// String to number. The input must be a slice of bytes.
let i: i32 = lexical_core::parse(b"3")?; // Ok(3), auto-type deduction.
let f: f32 = lexical_core::parse(b"3.5")?; // Ok(3.5)
let d: f64 = lexical_core::parse(b"3.5")?; // Ok(3.5), error checking parse.
let d: f64 = lexical_core::parse(b"3a")?; // Err(Error(_)), failed to parse.
功能
Lexical为每个数值转换例程提供特性门,如果某些数值转换,则结果编译时间更快。这些功能可以针对 lexical-core (不要求系统分配器) 和 lexical 启用/禁用。默认情况下,所有转换都启用。
- parse-floats: 启用字符串到浮点数的转换。
- parse-integers: 启用字符串到整数的转换。
- write-floats: 启用浮点数到字符串的转换。
- write-integers: 启用整数到字符串的转换。
Lexical高度可定制,并包含许多其他可选功能
- std: 启用Rust标准库的使用(默认启用)。
- power-of-two: 启用非十进制字符串之间的转换。
启用power_of_two后,以下基数有效:2、4、8、10、16、32。否则,只有10有效。这允许常见的十六进制整数/浮点数之间的转换,无需为其他基数创建大型预计算表。
- radix: 允许非十进制字符串之间的转换。
启用radix后,2到36(包括)之间的任何基数都有效,否则只有10有效。
- format: 自定义数字解析和写入时接受的数字格式。
启用format后,数字格式由位标志和掩码组成,这些位标志和掩码打包成一个
u128。这些指定了解析和写入数字的有效语法,包括启用数字分隔符、要求整数或分数位,以及切换大小写敏感的指数字符。 - compact: 以性能为代价优化二进制大小。
这最小化了预计算表的使用,生成显著较小的二进制文件。
- safe: 要求所有数组索引都要进行边界检查。
对于数字解析器来说,这实际上是一个无操作,因为它们除了可以轻易证明无需边界检查的索引是正确的外,都使用安全索引。数字写入器通常使用不安全索引,因为我们容易高估输出中的数字数量,因为输入是固定长度的。
- f16: 添加对16位浮点数进行数字转换的支持。
添加了
f16,这是一个半精度IEEE-754浮点类型,以及bf16,Brain Float 16类型,以及这些浮点数之间的数字转换。注意,由于这些是存储格式,因此没有本地算术运算,所有转换都使用中间的f32。
为确保在禁用边界检查时的安全性,我们对所有数字转换例程进行了广泛的模糊测试。有关更多信息,请参阅下面的安全性部分。
Lexical还非常注重代码膨胀:既优化性能又优化大小。默认情况下,这侧重于性能,但是,通过使用compact功能,您还可以以性能为代价选择更小的代码大小。紧凑算法以性能为代价最小化了预计算表和其他优化。
自定义
⚠ 警告:如果更改要写入的有效数字位数、禁用指数表示法或更改指数表示法阈值,
BUFFER_SIZE可能不足以存储结果输出。WriteOptions::buffer_size将提供正确写入字节数的上限。如果提供的缓冲区长度不足,lexical-core将引发恐慌。
每种语言都有自己的有效数值输入规范,这意味着Rust的数字解析器可能会错误地接受或拒绝来自不同编程或数据语言的输入。例如
// Valid in Rust strings.
// Not valid in JSON.
let f: f64 = lexical_core::parse(b"3.e7")?; // 3e7
// Let's only accept JSON floats.
const JSON: u128 = lexical_core::format::JSON;
let options = ParseFloatOptions::new();
let f: f64 = lexical_core::parse_with_options::<JSON>(b"3.0e7", &options)?; // 3e7
let f: f64 = lexical_core::parse_with_options::<JSON>(b"3.e7", &options)?; // Errors!
由于不同编程和数据语言中数值语法的巨大差异,我们提供了两个不同的API来简化具有不同语法要求的数值转换。
- 数字格式API(通过
format或power-of-two启用)。这是一个包含指定编译时数值解析或写入语法规则的标志的打包结构。这包括诸如数值字符串的基数、数字分隔符、大小写敏感的指数字符、可选的前缀/后缀基数等特性。
- 选项API。
这包含了解析和写入数字的运行时规则。这包括指数断点、舍入模式、指数和十进制点字符,以及NaN和Infinity的字符串表示。
以下示例中记录了功能的一个有限子集,但完整的规范可以在API参考文档中找到。
数字格式API
数字格式类提供了许多标志来指定解析或写入时使用的数字语法。当启用power-of-two功能时,会添加额外的标志
- 有效数字的基数(默认
10)。 - 指数基数的基数(默认
10)。 - 指数数字的基数(默认
10)。
当启用format功能时,还会启用许多其他语法和数字分隔符标志,包括
- 一个数字分隔符字符,用于分组数字以增强可读性。
- 是否允许前导、尾随、内部和连续的数字分隔符。
- 切换所需的浮点组成部分,例如小数点前的数字。
- 切换是否允许特殊浮点数或它们是否区分大小写。
因此存在许多预定义的常量,以简化常见用例,包括
- JSON、XML、TOML、YAML、SQLite等。
- Rust、Python、C#、FORTRAN、COBOL字面量和字符串等。
以下是一个构建自定义数字格式的示例
const FORMAT: u128 = lexical_core::NumberFormatBuilder::new()
// Disable exponent notation.
.no_exponent_notation(true)
// Disable all special numbers, such as Nan and Inf.
.no_special(true)
.build();
// Due to use in a `const fn`, we can't panic or expect users to unwrap invalid
// formats, so it's up to the caller to verify the format. If an invalid format
// is provided to a parser or writer, the function will error or panic, respectively.
debug_assert!(lexical_core::format_is_valid::<FORMAT>());
选项API
选项API允许在运行时自定义数字解析和写入,例如指定最大有效数字位数、指数字符等。
以下是一个构建自定义选项结构的示例
use std::num;
let options = lexical_core::WriteFloatOptions::builder()
// Only write up to 5 significant digits, IE, `1.23456` becomes `1.2345`.
.max_significant_digits(num::NonZeroUsize::new(5))
// Never write less than 5 significant digits, `1.1` becomes `1.1000`.
.min_significant_digits(num::NonZeroUsize::new(5))
// Trim the trailing `.0` from integral float strings.
.trim_floats(true)
// Use a European-style decimal point.
.decimal_point(b',')
// Panic if we try to write NaN as a string.
.nan_string(None)
// Write infinity as "Infinity".
.inf_string(Some(b"Infinity"))
.build()
.unwrap();
文档
Lexical的API参考可以在docs.rs上找到,同样可以在lexical-core上找到。有关使用的算法的详细描述,请参阅此处
此外,还记录了Lexical如何处理数字分隔符以及如何实现大整数算术的描述。
验证
浮点数解析
浮点数解析很难做正确,从libstdc++的strtod到Python的实现中发现了重大错误。为了验证lexical的准确性,我们采用了以下外部测试
- Hrvoje Abraham的strtod测试用例。
- Rust的test-float-parse单元测试。
- Testbase的将十进制转换为二进制的压力测试。
- Nigel Tao从Freetype、Google的double-conversion库、IBM的IEEE-754R合规性测试以及许多其他精心挑选的示例中提取的测试。
- 各种 困难 情况 在博客上报告。
尽管lexical可能包含导致舍入错误的错误,但它已针对一系列随机数据和近一半的表示进行测试,应该对大多数用例快速且正确。
度量
这里显示了各种基准、二进制大小和编译时间
构建时间
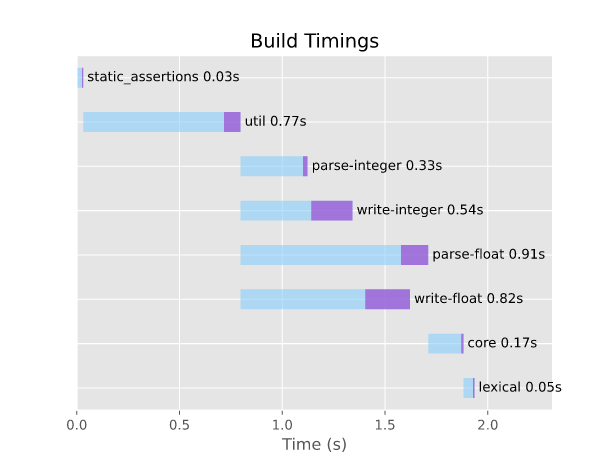
启用所有数字转换时的编译时间。有关更详细的分解,请参阅构建时间。
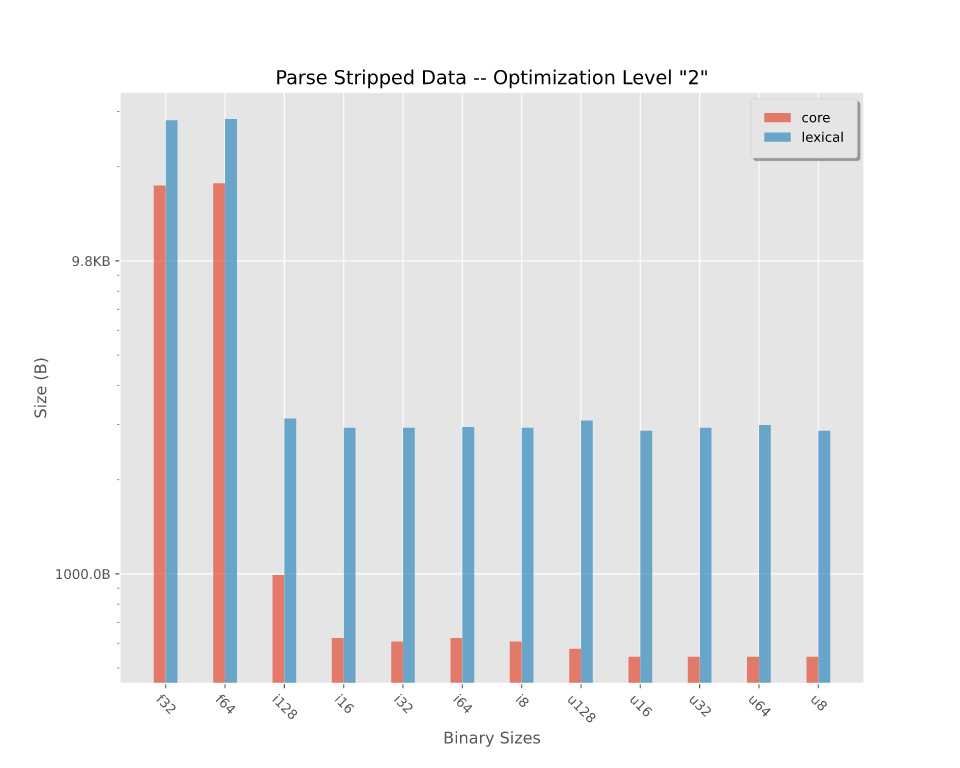
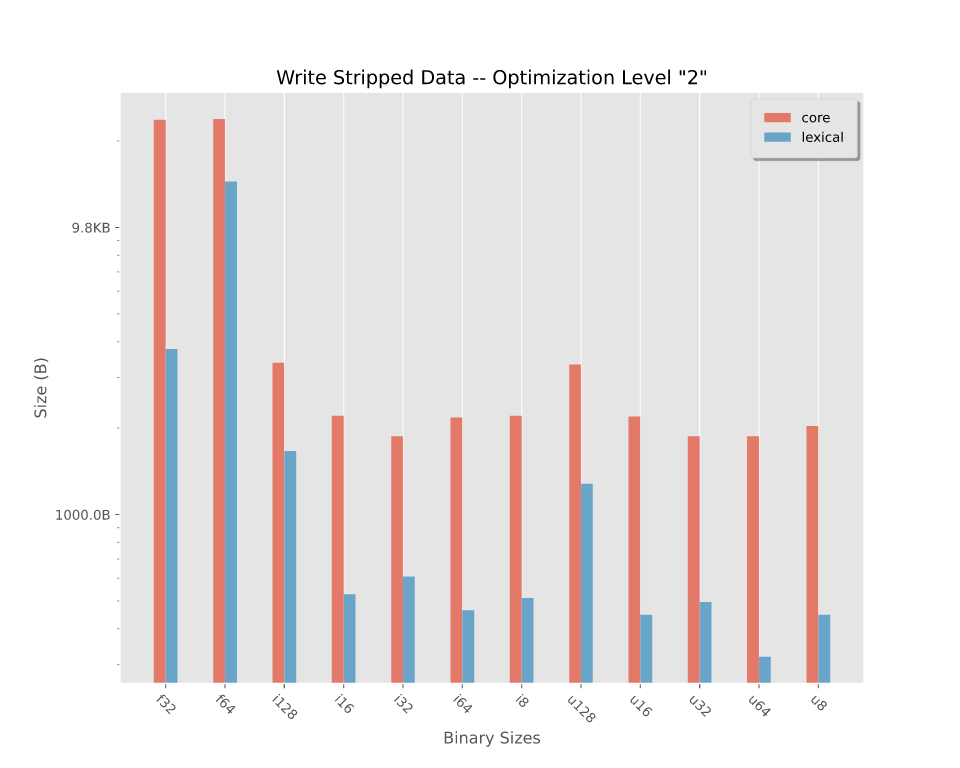
二进制大小
在优化级别"2"编译的剥离二进制文件的二进制大小。要查看更详细的拆分,请参阅二进制大小。
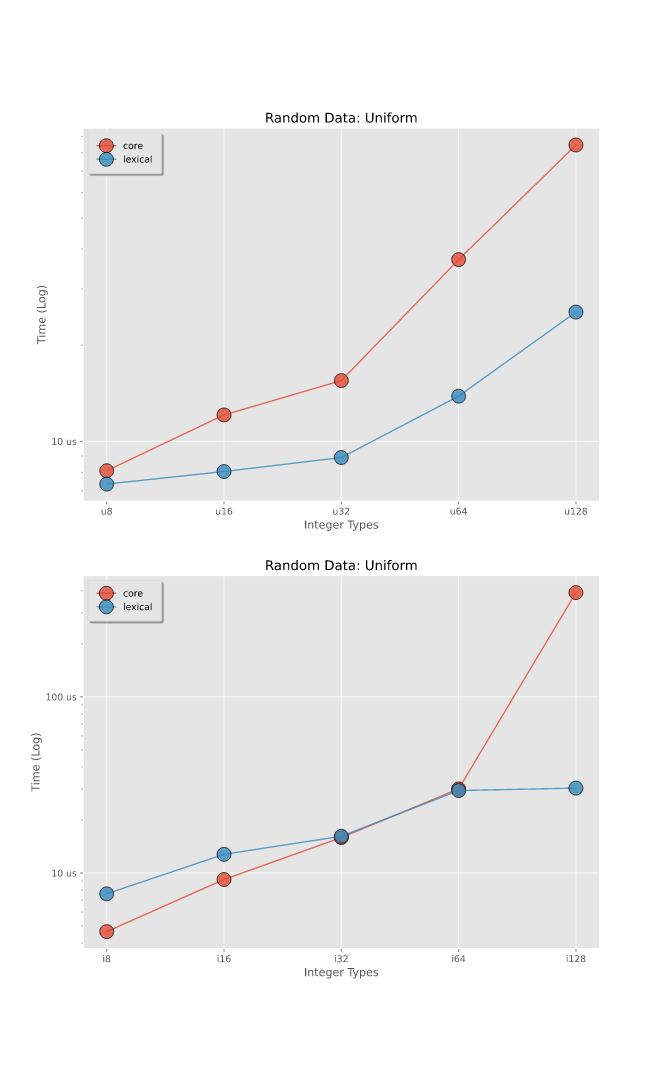
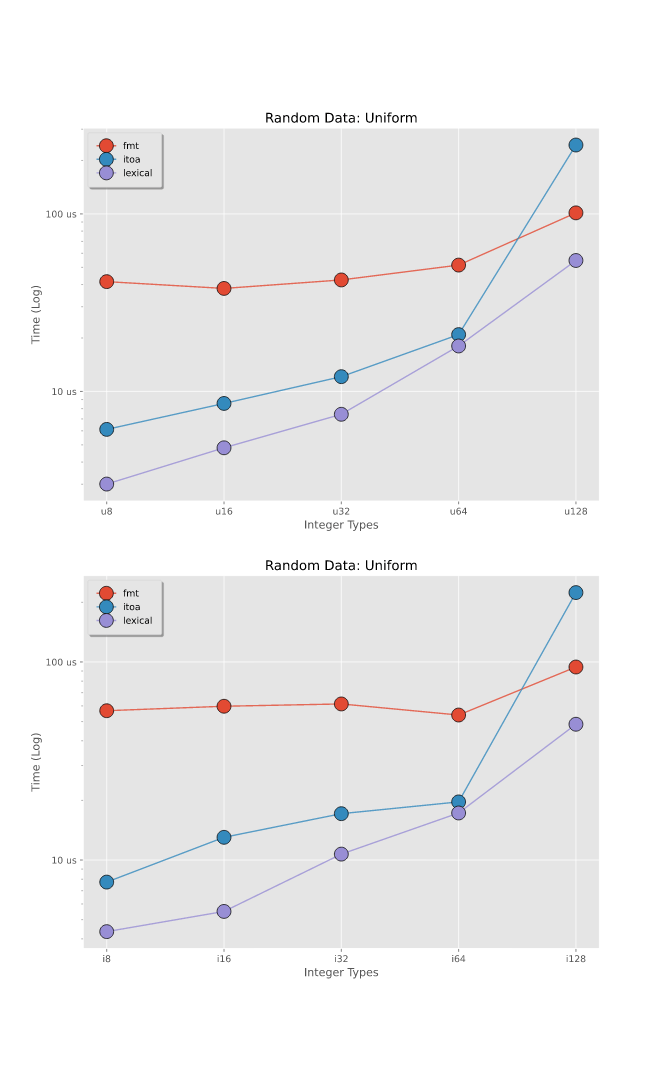
基准测试 -- 解析整数
在随机生成的整数上进行基准测试,这些整数在整个范围内均匀分布。要查看更详细的拆分,请参阅基准测试。
基准测试 -- 解析浮点数
在解析来自各种实际数据集的浮点数上进行基准测试。要查看更详细的拆分,请参阅基准测试。
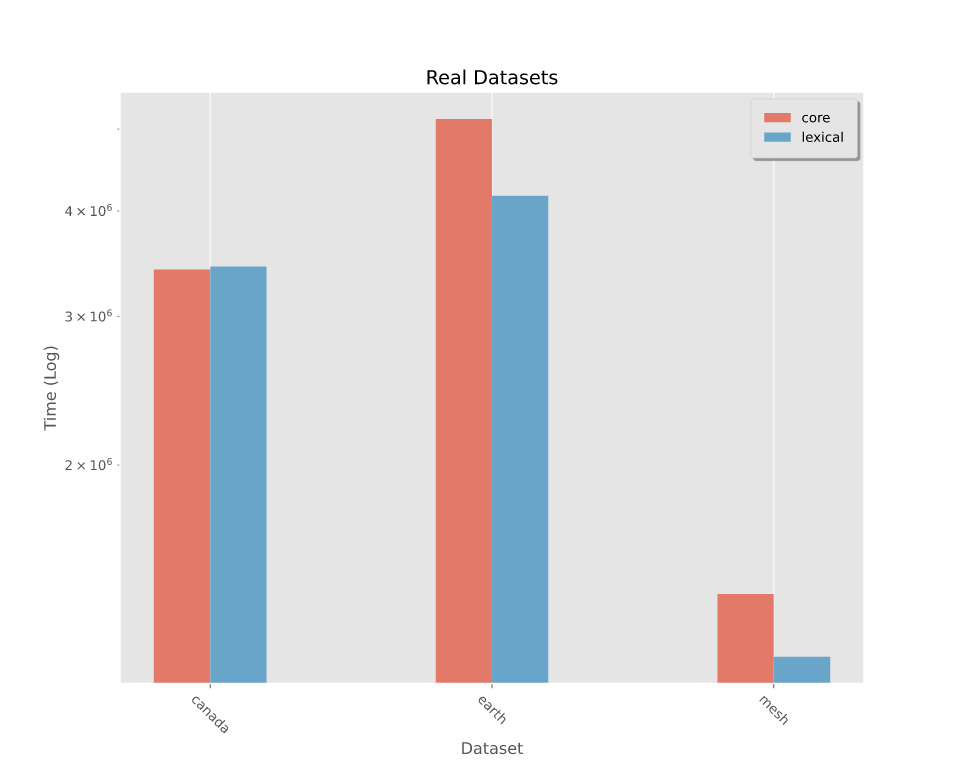
基准测试 -- 写入整数
在写入整个范围内均匀分布的随机整数上进行基准测试。要查看更详细的拆分,请参阅基准测试。
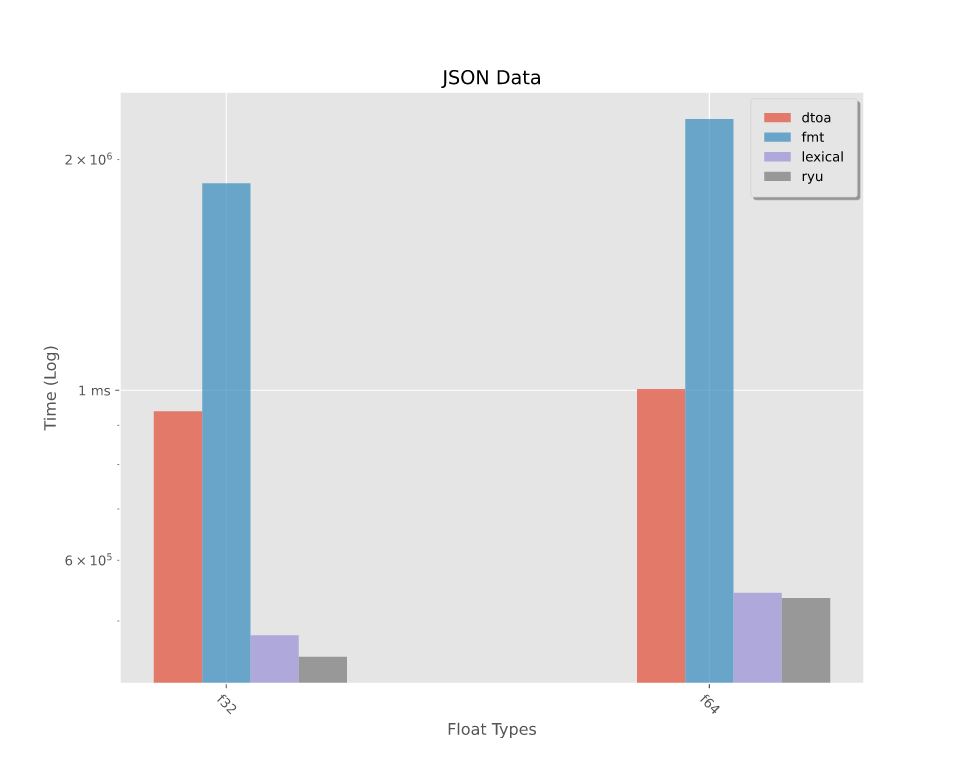
基准测试 -- 写入浮点数
在写入通过随机数生成器生成的浮点数和从JSON文档中解析的浮点数上进行基准测试。要查看更详细的拆分,请参阅基准测试。
安全性
由于整数和浮点数写入器使用了内存不安全代码,我们对浮点数写入器和解析器进行了广泛的模糊测试。模糊测试工具可以在fuzz下找到,并且正在持续运行。迄今为止,我们已经解析和写入超过720亿个浮点数。
由于整数写入器的简单逻辑和整数解析器中缺乏内存安全性,我们对两者都进行了最小程度的模糊测试,并用边缘情况进行了测试,迄今为止没有出现内存安全问题。
平台支持
lexical-core在各种平台上进行了测试,包括大端和小端系统,以确保代码可移植性。支持的架构包括
- x86_64 Linux、Windows、macOS、Android、iOS、FreeBSD和NetBSD。
- x86 Linux、macOS、Android、iOS和FreeBSD。
- aarch64 (ARM8v8-A) Linux、Android和iOS。
- armv7 (ARMv7-A) Linux、Android和iOS。
- arm (ARMv6) Linux和Android。
- mips (MIPS) Linux。
- mipsel (MIPS LE) Linux。
- mips64 (MIPS64 BE) Linux。
- mips64el (MIPS64 LE) Linux。
- powerpc (PowerPC) Linux。
- powerpc64 (PPC64) Linux。
- powerpc64le (PPC64LE) Linux。
- s390x (IBM Z) Linux。
lexical-core也应该能在各种其他架构和指令集中工作。如果您在任何架构上编译lexical-core有问题,请提交一个错误报告。
版本和版本支持
版本支持
目前支持的版本包括
- v0.8.x
- v0.7.x(维护)
- v0.6.x(维护)
Rustc 兼容性
- v0.8.x 支持 1.51+,包括稳定版、beta版和nightly版。
- v0.7.x 支持 1.37+,包括稳定版、beta版和nightly版。
- v0.6.x 支持 Rustc 1.24+,包括稳定版、beta版和nightly版。
请报告任何在兼容的Rustc版本上编译支持版本的lexical-core时的错误。
版本号
lexical使用语义版本控制。移除对比最新稳定版Debian或Ubuntu版本更新的Rustc版本的支持被认为是API不兼容的变更,需要修改主版本号。
变更日志
所有更改都在CHANGELOG中记录。
许可
Lexical同时受Apache 2.0许可和MIT许可的双重许可。有关完整许可详情,请参阅LICENSE.md文件。
贡献
除非您明确说明,否则根据Apache-2.0许可定义,您有意提交以包含在词汇表中的任何贡献,应如上双许可,不附加任何额外条款或条件。向存储库贡献意味着遵守行为准则。
有关如何向lexical贡献的流程,请参阅开发快速入门指南。