5 个版本
| 0.8.5 | 2022 年 5 月 18 日 |
|---|---|
| 0.8.4 | 2022 年 5 月 18 日 |
| 0.8.3 | 2022 年 3 月 10 日 |
| 0.8.1 | 2021 年 9 月 3 日 |
| 0.8.0 | 2021 年 9 月 3 日 |
#79 in 值格式化
1,580,116 每月下载量
用于 866 个 Crates (5 个直接使用)
410KB
7K SLoC
lexical
为在 no_std 环境中使用而设计的高性能数值转换例程。此库不依赖任何标准库特性,也不依赖系统分配器。
类似项目
如果您需要一个最小化、稳定且编译时友好的 lexical 浮点解析算法版本,请参阅 minimal-lexical。如果您需要一个最小化、高性能的浮点解析器,Rust 标准库的最近版本应该足够 使用。
目录
入门
将 lexical 添加到您的 Cargo.toml
[dependencies]
lexical = "^6.0"
然后开始使用 lexical
// Number to string
use lexical_core::BUFFER_SIZE;
let mut buffer = [b'0'; BUFFER_SIZE];
lexical_core::write(3.0, &mut buffer); // "3.0", always has a fraction suffix,
lexical_core::write(3, &mut buffer); // "3"
// String to number.
let i: i32 = lexical_core::parse("3")?; // Ok(3), auto-type deduction.
let f: f32 = lexical_core::parse("3.5")?; // Ok(3.5)
let d: f64 = lexical_core::parse("3.5")?; // Ok(3.5), error checking parse.
let d: f64 = lexical_core::parse("3a")?; // Err(Error(_)), failed to parse.
为了在泛型代码中使用 lexical,提供了 FromLexical(用于 parse)和 ToLexical(用于 to_string)特性边界。
/// Multiply a value in a string by multiplier, and serialize to string.
fn mul_2<T>(value: &str, multiplier: T)
-> Result<String, lexical_core::Error>
where
T: lexical_core::ToLexical + lexical_core::FromLexical,
{
let value: T = lexical_core::parse(value.as_bytes())?;
let mut buffer = [b'0'; lexical_core::BUFFER_SIZE];
let bytes = lexical_core::write(value * multiplier, &mut buffer);
Ok(std::str::from_utf8(bytes).unwrap())
}
部分/完整解析器
部分解析器/完整解析器
完整解析器
// This will return Err(Error::InvalidDigit(3)), indicating
// the first invalid character occurred at the index 3 in the input
// string (the space character).
let x: i32 = lexical_core::parse(b"123 456")?;
部分解析器
// This will return Ok((123, 3)), indicating that 3 digits were successfully
// parsed, and that the returned value is `123`.
let (x, count): (i32, usize) = lexical_core::parse_partial(b"123 456")?;
no_std
lexical-core 不依赖于标准库或系统分配器。要在 no_std 环境中使用 lexical-core,请在 Cargo.toml 中添加以下内容
[dependencies.lexical-core]
version = "0.8.5"
default-features = false
# Can select only desired parsing/writing features.
features = ["write-integers", "write-floats", "parse-integers", "parse-floats"]
然后开始使用 lexical
// A constant for the maximum number of bytes a formatter will write.
use lexical_core::BUFFER_SIZE;
let mut buffer = [b'0'; BUFFER_SIZE];
// Number to string. The underlying buffer must be a slice of bytes.
let count = lexical_core::write(3.0, &mut buffer);
assert_eq!(buffer[..count], b"3.0");
let count = lexical_core::write(3i32, &mut buffer);
assert_eq!(buffer[..count], b"3");
// String to number. The input must be a slice of bytes.
let i: i32 = lexical_core::parse(b"3")?; // Ok(3), auto-type deduction.
let f: f32 = lexical_core::parse(b"3.5")?; // Ok(3.5)
let d: f64 = lexical_core::parse(b"3.5")?; // Ok(3.5), error checking parse.
let d: f64 = lexical_core::parse(b"3a")?; // Err(Error(_)), failed to parse.
特性
Lexical 对每个数字转换例程使用功能门,如果某些数字转换,这将导致编译时间更快。这些功能可以针对 lexical-core(不需要系统分配器)和 lexical 启用或禁用。默认情况下,所有转换都启用。
- parse-floats:启用字符串到浮点数的转换。
- parse-integers:启用字符串到整数的转换。
- write-floats:启用浮点数到字符串的转换。
- write-integers:启用整数到字符串的转换。
Lexical 可高度自定义,并包含许多其他可选功能
- std:启用使用 Rust 标准库(默认启用)。
- power-of-two:启用到和从非十进制字符串的转换。
启用 power_of_two 后,基数
{2, 4, 8, 10, 16, 和 32}是有效的,否则只有 10 是有效的。这允许常见的十六进制整数/浮点数到和从的转换,而不需要为其他基数创建大型预计算的表。 - radix:允许到和从非十进制字符串的转换。
启用 radix 后,2 到 36(含)之间的任何基数都有效,否则只有 10 有效。
- format:自定义数字解析和写入可接受的数字格式。
启用 format 后,数字格式通过位标志和掩码打包到
u128中。这些指定了解析和写入数字的有效语法,包括启用数字分隔符、要求整数或小数位数,以及切换大小写敏感的指数字符。 - compact:以性能为代价优化二进制大小。
这最小化了预计算表的使用,产生了显著更小的二进制文件。
- safe:要求所有数组索引都要进行边界检查。
对于数字解析器,这实际上是一个无操作,因为它们除了可以轻易证明无边界索引是正确的位置之外,都使用安全索引。数字写入器经常使用不安全的索引,因为我们很容易高估输出中数字的数量,这是由于输入是固定长度的。
- f16:添加对 16 位浮点数的数字转换支持。
添加了
f16,这是一个半精度 IEEE-754 浮点类型,以及bf16,这是一个 Brain Float 16 类型,以及到和从这些浮点数的数字转换。请注意,由于这些是存储格式,因此没有本地的算术运算,所有转换都使用中间的f32。
为了确保在禁用边界检查时的安全性,我们对所有数字转换例程进行了广泛的模糊测试。有关更多信息,请参阅下面的 安全性 部分。
Lexical 还非常重视代码膨胀:使用既优化性能又优化大小的算法。默认情况下,这侧重于性能,但是,通过使用 compact 功能,您也可以选择以性能为代价减小代码大小。紧凑算法以性能为代价最小化了预计算表和其他优化的使用。
自定义
⚠ 警告: 如果更改写入的位数、禁用指数表示法或更改指数表示法阈值,
BUFFER_SIZE可能不足以存储结果输出。WriteOptions::buffer_size将提供写入字节数的正确上限。如果提供了不足长度的缓冲区,lexical-core 将引发恐慌。
每种语言都有针对有效数值输入的竞争性规范,这意味着 Rust 的数值解析器可能对不同编程或数据语言接受或拒绝输入。例如
// Valid in Rust strings.
// Not valid in JSON.
let f: f64 = lexical_core::parse(b"3.e7")?; // 3e7
// Let's only accept JSON floats.
const JSON: u128 = lexical_core::format::JSON;
let options = ParseFloatOptions::new();
let f: f64 = lexical_core::parse_with_options::<JSON>(b"3.0e7", &options)?; // 3e7
let f: f64 = lexical_core::parse_with_options::<JSON>(b"3.e7", &options)?; // Errors!
由于不同编程和数据语言中数值语法的极高可变性,我们提供了 2 个不同的 API,以简化不同语法要求的数值转换。
- 数值格式 API(通过
format或power-of-two特性启用)。这是一个打包的 struct,包含用于指定编译时数值解析或写入语法规则的标志。这包括数值字符串的基数、数字分隔符、大小写敏感的指数字符、可选的基数前缀/后缀等。
- 选项 API。
这包含了解析和写入数值的运行时规则。这包括指数断点、舍入模式、指数和十进制点字符,以及 NaN 和 Infinity 的字符串表示。
以下文档中记录了功能的一部分子集,但完整的规范可以在 API 参考文档中找到。
数字格式 API
数值格式类提供了许多标志,用于在解析或写入时指定数值语法。当启用 power-of-two 特性时,还会添加额外的标志
- 有效数字的基数(默认
10)。 - 指数基数的基数(默认
10)。 - 指数数字的基数(默认
10)。
当启用 format 特性时,还会启用许多其他语法和数字分隔符标志,包括
- 一个数字分隔符字符,用于分组数字以提高可读性。
- 是否允许前导、尾随、内部和连续的数字分隔符。
- 切换所需的浮点组件,如小数点前的数字。
- 切换是否允许特殊浮点数或是否区分大小写。
因此存在许多预定义的常量,以简化常见用例,包括
- JSON、XML、TOML、YAML、SQLite 等。
- Rust、Python、C#、FORTRAN、COBOL 字面量和字符串等。
以下是一个构建自定义数值格式的示例
const FORMAT: u128 = lexical_core::NumberFormatBuilder::new()
// Disable exponent notation.
.no_exponent_notation(true)
// Disable all special numbers, such as Nan and Inf.
.no_special(true)
.build();
// Due to use in a `const fn`, we can't panic or expect users to unwrap invalid
// formats, so it's up to the caller to verify the format. If an invalid format
// is provided to a parser or writer, the function will error or panic, respectively.
debug_assert!(lexical_core::format_is_valid::<FORMAT>());
选项 API
选项 API 允许在运行时自定义数值解析和写入,例如指定最大有效数字位数、指数字符等。
以下是一个构建自定义选项 struct 的示例
use std::num;
let options = lexical_core::WriteFloatOptions::builder()
// Only write up to 5 significant digits, IE, `1.23456` becomes `1.2345`.
.max_significant_digits(num::NonZeroUsize::new(5))
// Never write less than 5 significant digits, `1.1` becomes `1.1000`.
.min_significant_digits(num::NonZeroUsize::new(5))
// Trim the trailing `.0` from integral float strings.
.trim_floats(true)
// Use a European-style decimal point.
.decimal_point(b',')
// Panic if we try to write NaN as a string.
.nan_string(None)
// Write infinity as "Infinity".
.inf_string(Some(b"Infinity"))
.build()
.unwrap();
文档
Lexical 的 API 参考可以在 docs.rs 上找到,同样 lexical-core 也可以。这里可以找到使用的算法的详细描述
此外,还记录了 lexical 如何处理 数字分隔符 以及实现 大整数算术。
验证
浮点数解析
正确执行浮点数解析很困难,从 libstdc++ 的 strtod 到 Python 的实现都发现了重大错误。为了验证 lexical 的准确性,我们采用了以下外部测试
- Hrvoje Abraham的 strtod 测试用例。
- Rust的 test-float-parse 单元测试。
- Testbase的将十进制转换为二进制的 压力测试。
- Nigel Tao从Freetype、Google的double-conversion库、IBM的IEEE-754R兼容性测试以及众多其他精心挑选的示例中提取的 测试用例。
- 博客上报道的各种 困难 情况。
尽管词法分析可能包含导致舍入误差的错误,但它已针对随机数据和近一半的表示进行了全面测试,并且应该对绝大多数用例来说是快速且正确的。
度量
这里展示了各种基准、二进制大小和编译时间。
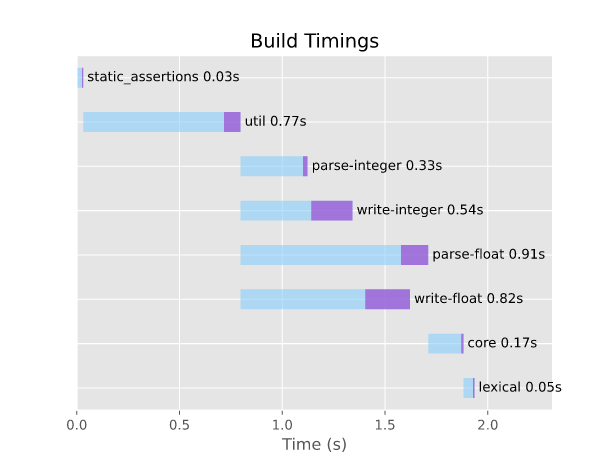
构建时间
启用所有数字转换时的编译时间。有关更详细的分解,请参阅构建时间。
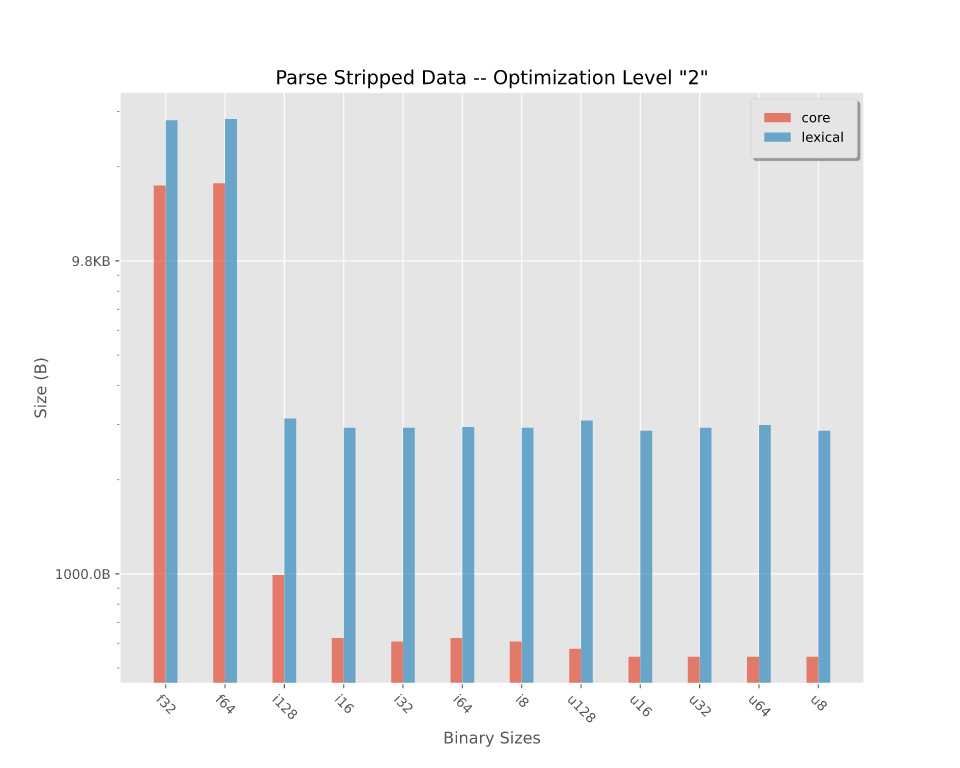
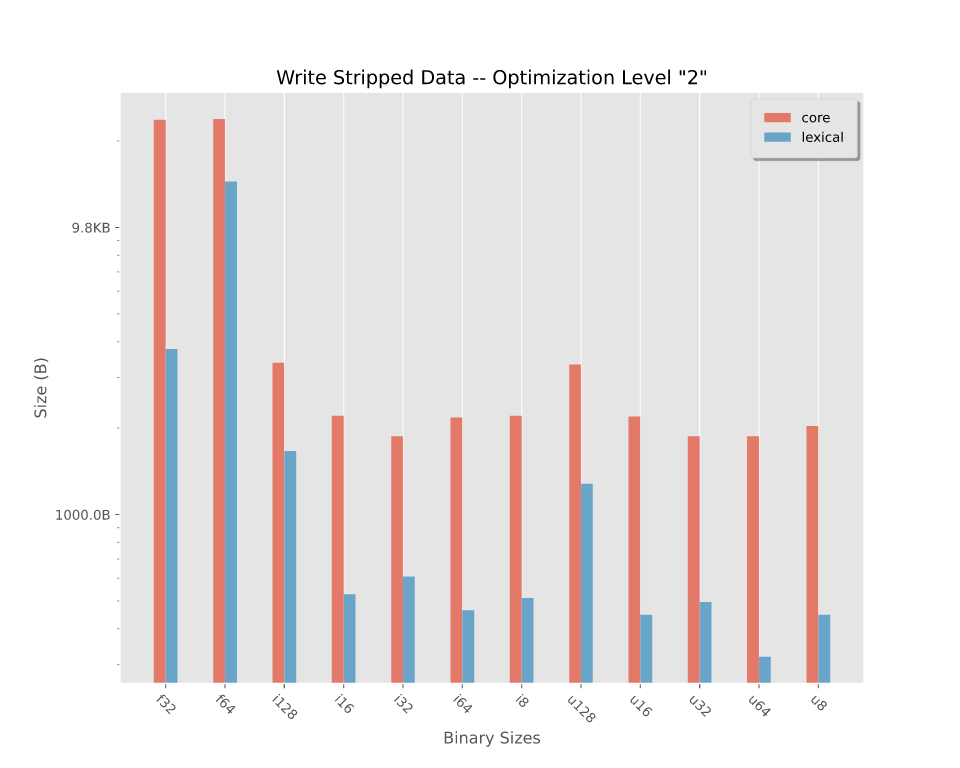
二进制大小
在优化级别"2"下编译的剥离二进制文件的大小。有关更详细的分解,请参阅二进制大小。
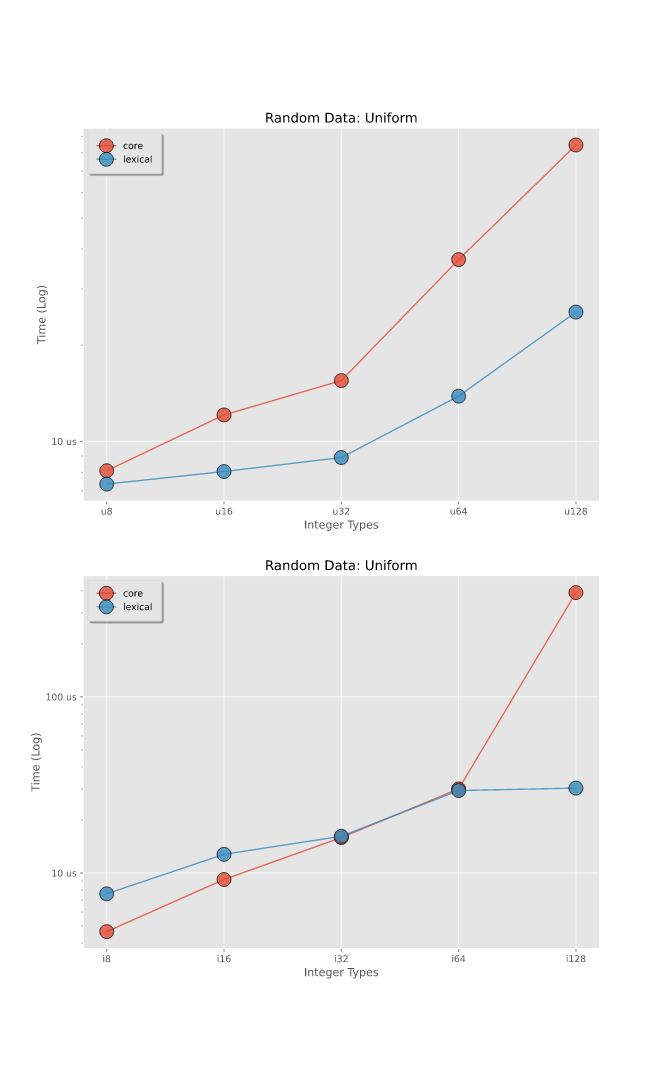
基准 -- 解析整数
在随机生成的整数上进行的基准测试,这些整数在整个范围内均匀分布。有关更详细的分解,请参阅基准测试。
基准 -- 解析浮点数
解析来自各种现实数据集的浮点数的基准测试。有关更详细的分解,请参阅基准测试。
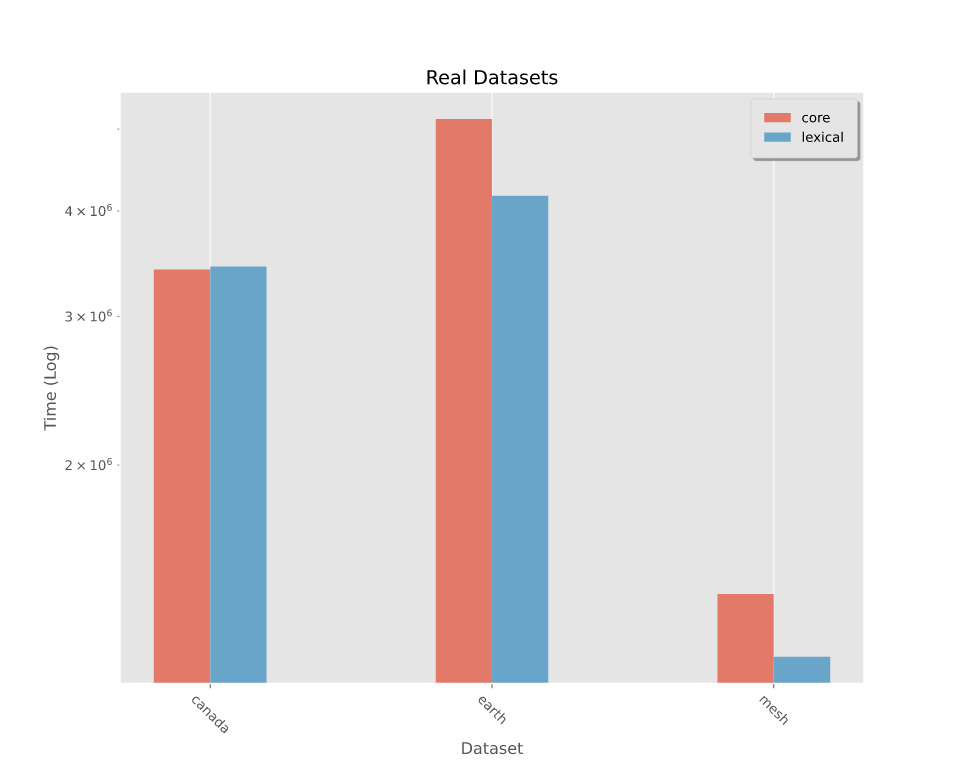
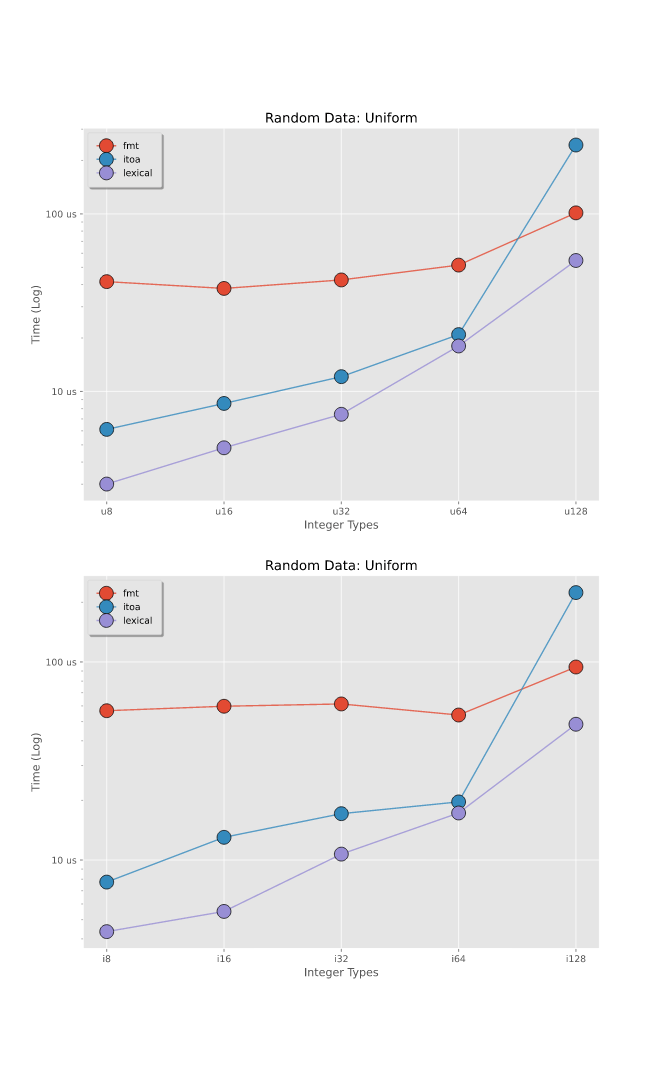
基准 -- 写入整数
在写入随机整数上进行的基准测试,这些整数在整个范围内均匀分布。有关更详细的分解,请参阅基准测试。
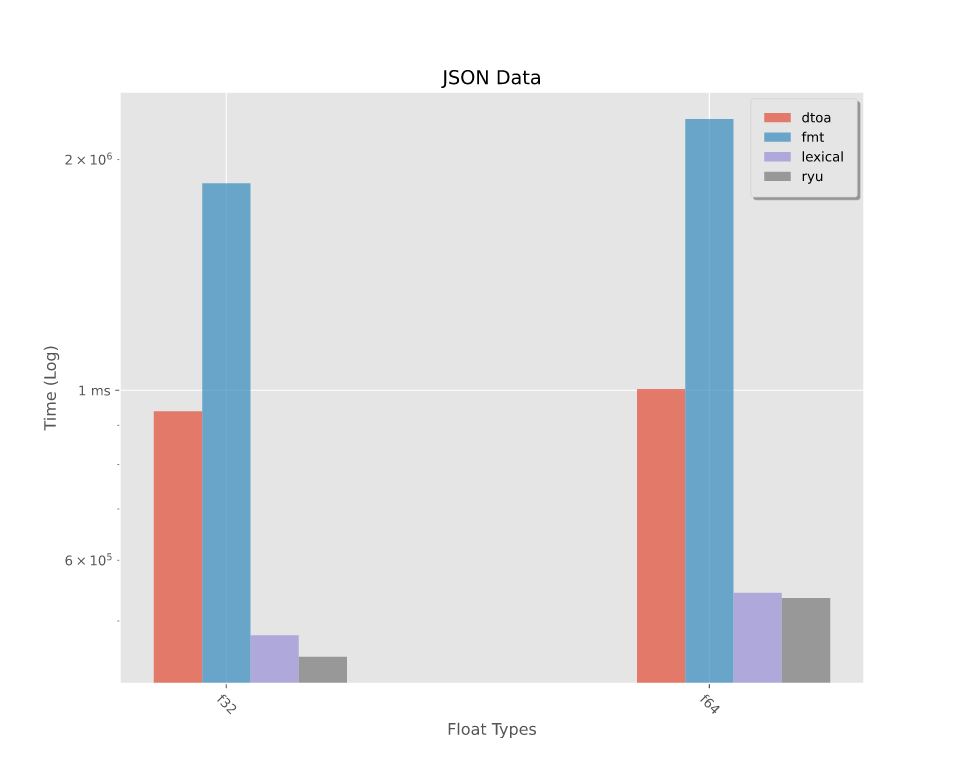
基准 -- 写入浮点数
通过随机数生成器和从JSON文档解析生成的浮点数进行的基准测试。有关更详细的分解,请参阅基准测试。
安全性
由于整数和浮点数写入器使用了内存不安全代码,我们广泛地对浮点数写入器和解析器进行了模糊测试。模糊测试 harness 可以在 fuzz 下找到,并且持续运行。到目前为止,我们已经解析和写入超过720亿个浮点数。
由于整数写入器的简单逻辑和整数解析器中缺乏内存安全性,我们对两者都进行了最小化模糊测试,并使用边缘情况进行了测试,至今尚未发现内存安全性问题。
平台支持
lexical-core在包括大端和小端系统在内的各种平台上进行了测试,以确保代码的可移植性。支持的架构包括
- x86_64 Linux、Windows、macOS、Android、iOS、FreeBSD和NetBSD。
- x86 Linux、macOS、Android、iOS和FreeBSD。
- aarch64 (ARM8v8-A) Linux、Android和iOS。
- armv7 (ARMv7-A) Linux、Android和iOS。
- arm (ARMv6) Linux和Android。
- mips (MIPS) Linux。
- mipsel (MIPS LE) Linux。
- mips64 (MIPS64 BE) Linux。
- mips64el (MIPS64 LE) Linux。
- powerpc (PowerPC) Linux。
- powerpc64 (PPC64) Linux。
- powerpc64le (PPC64LE) Linux。
- s390x (IBM Z) Linux。
lexical-core也应该在各种其他架构和ISA上工作。如果您在某个架构上编译lexical-core时遇到任何问题,请提交错误报告。
版本和版本支持
版本支持
当前支持的版本包括
- v0.8.x
- v0.7.x(维护状态)
- v0.6.x(维护状态)
Rustc 兼容性
- v0.8.x 支持 1.51+,包括稳定版、beta版和nightly版。
- v0.7.x 支持 1.37+,包括稳定版、beta版和nightly版。
- v0.6.x 支持 Rustc 1.24+,包括稳定版、beta版和nightly版。
请报告在兼容的 Rustc 版本上编译支持的 lexical-core 版本时出现的任何错误。
版本控制
lexical 使用 语义版本控制。移除对最新稳定 Debian 或 Ubuntu 版本之后的新 Rustc 版本的支持被视为不兼容的 API 变更,需要进行主要版本更改。
变更日志
所有更改均在 CHANGELOG 中记录。
许可证
Lexical 采用 Apache 2.0 许可证以及 MIT 许可证双许可。有关完整的许可证详情,请参阅 LICENSE.md 文件。
贡献
除非您明确声明,否则您提交给 lexical 的任何有意包含的贡献,根据 Apache-2.0 许可证定义,将按上述方式双许可,不附加任何额外条款或条件。向仓库贡献意味着遵守 行为准则。
有关如何向 lexical 贡献的流程,请参阅 开发快速入门指南。