11 个版本
| 0.1.10 | 2024 年 5 月 20 日 |
|---|---|
| 0.1.9 | 2024 年 4 月 15 日 |
| 0.1.8 | 2023 年 6 月 18 日 |
| 0.1.7 | 2023 年 3 月 13 日 |
| 0.1.4 | 2022 年 11 月 1 日 |
#30 in 开发工具
92 每月下载量
91KB
981 行
Ksunami
波动的 Kafka 记录!
什么是 Ksunami?
Ksunami 是一个命令行工具,用于生成针对 Kafka 集群主题的恒定、可配置、循环的(虚拟)记录流。
如果您正在尝试对 Kafka 进行可伸缩性和延迟测试,并希望以特定周期重复的交通模式重现记录流,那么 Ksunami 是您的工具。
Ksunami 提供了一种设置记录生产的方式,将场景表示为一组无限重复的“阶段”。记录内容可配置但随机:该工具的目的是帮助您进行基础设施的性能和可伸缩性测试。
功能
- 以 4 个“阶段”描述生产,这些阶段在循环中重复:
min、up、max和down - 所有阶段均可根据 秒(持续时间)和 每秒记录(工作负载)进行配置
up和down可以是许多过渡之一,每个过渡都有特定的“形状”(例如linear、ease-in、spike-out等)- 记录的
key和payload可以使用固定值、从文件生成的值或随机生成的值进行配置 - 可以为每个记录添加记录头
- 完全可配置的 Kafka 生产者,包括选择分区器
- 基于神奇的 librdkafka
入门
要安装 ksunami,您需要自己编译它。您需要 Rust 工具链,然后运行
$ cargo install ksunami
注意 我们正在努力提供 二进制发布(i#13) 和 homebrew 安装(i#14)。
在 Docker 中
Ksunami 现已作为 Docker 镜像提供:在 Docker Hub 仓库中可找到 kafkesc/ksunami。提供基于 Debian slim 镜像的两种镜像:linux/amd64 和 linux/arm64。
ENTRYPOINT 是 ksunami 二进制文件本身,因此您可以直接向容器执行传递参数。
用法
感谢 clap,Ksunami 提供开箱即用的 紧凑型 和 扩展型 用法说明支持。
紧凑型:ksunami -h
Produce constant, configurable, cyclical waves of Kafka Records
Usage: ksunami [OPTIONS] --brokers <BOOTSTRAP_BROKERS> --topic <TOPIC> --min <REC/SEC> --max <REC/SEC>
Options:
-b, --brokers <BOOTSTRAP_BROKERS> Initial Kafka Brokers to connect to (format: 'HOST:PORT,...')
--client-id <CLIENT_ID> Client identifier used by the internal Kafka Producer [default: ksunami]
--partitioner <PARTITIONER> Partitioner used by the internal Kafka Producer [default: consistent_random] [possible values: random, consistent,
consistent_random, murmur2, murmur2_random, fnv1a, fnv1a_random]
-c, --config <CONF_KEY:CONF_VAL> Additional configuration used by the internal Kafka Producer (format: 'CONF_KEY:CONF_VAL')
-t, --topic <TOPIC> Destination Topic
-k, --key <KEY_TYPE:INPUT> Records Key (format: 'KEY_TYPE:INPUT').
-p, --payload <PAYLOAD_TYPE:INPUT> Records Payload (format: 'PAYLOAD_TYPE:INPUT').
--partition <PARTITION> Destination Topic Partition
--head <HEAD_KEY:HEAD_VAL> Records Header(s) (format: 'HEAD_KEY:HEAD_VAL')
--min <REC/SEC> Minimum amount of records/sec
--min-sec <SEC> How long to produce at minimum records/sec, before ramp-up [default: 60]
--max <REC/SEC> Maximum amount of records/sec
--max-sec <SEC> How long to produce at maximum records/sec, before ramp-down [default: 60]
--up <TRANSITION_TYPE> Ramp-up transition from minimum to maximum records/sec [default: linear] [possible values: none, linear, ease-in, ease-out,
ease-in-out, spike-in, spike-out, spike-in-out]
--up-sec <SEC> How long the ramp-up transition should last [default: 10]
--down <TRANSITION_TYPE> Ramp-down transition from maximum to minimum records/sec [default: none] [possible values: none, linear, ease-in, ease-out,
ease-in-out, spike-in, spike-out, spike-in-out]
--down-sec <SEC> How long the ramp-down transition should last [default: 10]
-v, --verbose... Verbose logging.
-q, --quiet... Quiet logging.
-h, --help Print help information (use `--help` for more detail)
-V, --version Print version information
扩展型:ksunami --help
Produce constant, configurable, cyclical waves of Kafka Records
Usage: ksunami [OPTIONS] --brokers <BOOTSTRAP_BROKERS> --topic <TOPIC> --min <REC/SEC> --max <REC/SEC>
Options:
-b, --brokers <BOOTSTRAP_BROKERS>
Initial Kafka Brokers to connect to (format: 'HOST:PORT,...').
Equivalent to '--config=bootstrap.servers:host:port,...'.
--client-id <CLIENT_ID>
Client identifier used by the internal Kafka Producer.
Equivalent to '--config=client.id:my-client-id'.
[default: ksunami]
--partitioner <PARTITIONER>
Partitioner used by the internal Kafka Producer.
Equivalent to '--config=partitioner:random'.
[default: consistent_random]
Possible values:
- random:
Random distribution
- consistent:
CRC32 hash of key (Empty and NULL keys are mapped to single partition)
- consistent_random:
CRC32 hash of key (Empty and NULL keys are randomly partitioned)
- murmur2:
Java Producer compatible Murmur2 hash of key (NULL keys are mapped to single partition)
- murmur2_random:
Java Producer compatible Murmur2 hash of key (NULL keys are randomly partitioned): equivalent to default partitioner in Java Producer
- fnv1a:
FNV-1a hash of key (NULL keys are mapped to single partition)
- fnv1a_random:
FNV-1a hash of key (NULL keys are randomly partitioned)
-c, --config <CONF_KEY:CONF_VAL>
Additional configuration used by the internal Kafka Producer (format: 'CONF_KEY:CONF_VAL').
To set multiple configurations keys, use this argument multiple times. See: https://github.com/edenhill/librdkafka/blob/master/CONFIGURATION.md.
-t, --topic <TOPIC>
Destination Topic.
Topic must already exist.
-k, --key <KEY_TYPE:INPUT>
Records Key (format: 'KEY_TYPE:INPUT').
The supported key types are:
* 'string:STR': STR is a plain string
* 'file:PATH': PATH is a path to an existing file
* 'alpha:LENGTH': LENGTH is the length of a random alphanumeric string
* 'bytes:LENGTH': LENGTH is the length of a random bytes array
* 'int:MIN-MAX': MIN and MAX are limits of an inclusive range from which an integer number is picked
* 'float:MIN-MAX': MIN and MAX are limits of an inclusive range from which a float number is picked
-p, --payload <PAYLOAD_TYPE:INPUT>
Records Payload (format: 'PAYLOAD_TYPE:INPUT').
The supported payload types are:
* 'string:STR': STR is a plain string
* 'file:PATH': PATH is a path to an existing file
* 'alpha:LENGTH': LENGTH is the length of a random alphanumeric string
* 'bytes:LENGTH': LENGTH is the length of a random bytes array
* 'int:MIN-MAX': MIN and MAX are limits of an inclusive range from which an integer number is picked
* 'float:MIN-MAX': MIN and MAX are limits of an inclusive range from which a float number is picked
--partition <PARTITION>
Destination Topic Partition.
If not specified (or '-1'), Producer will rely on the Partitioner. See the '--partitioner' argument.
--head <HEAD_KEY:HEAD_VAL>
Records Header(s) (format: 'HEAD_KEY:HEAD_VAL').
To set multiple headers, use this argument multiple times.
--min <REC/SEC>
Minimum amount of records/sec
--min-sec <SEC>
How long to produce at minimum records/sec, before ramp-up
[default: 60]
--max <REC/SEC>
Maximum amount of records/sec
--max-sec <SEC>
How long to produce at maximum records/sec, before ramp-down
[default: 60]
--up <TRANSITION_TYPE>
Ramp-up transition from minimum to maximum records/sec
[default: linear]
Possible values:
- none: Immediate transition, with no in-between values
- linear: Linear transition, constant increments between values
- ease-in: Slow increment at the beginning, accelerates half way through until the end
- ease-out: Fast increment at the beginning, decelerates half way through until the end
- ease-in-out: Slow increment at the beginning, accelerates half way, decelerates at the end
- spike-in: Fastest increment at the beginning, slowest deceleration close to the end
- spike-out: Slowest increment at the beginning, fastest acceleration close to the end
- spike-in-out: Fastest increment at the beginning, slow half way, fastest acceleration close to the end
--up-sec <SEC>
How long the ramp-up transition should last
[default: 10]
--down <TRANSITION_TYPE>
Ramp-down transition from maximum to minimum records/sec
[default: none]
Possible values:
- none: Immediate transition, with no in-between values
- linear: Linear transition, constant increments between values
- ease-in: Slow increment at the beginning, accelerates half way through until the end
- ease-out: Fast increment at the beginning, decelerates half way through until the end
- ease-in-out: Slow increment at the beginning, accelerates half way, decelerates at the end
- spike-in: Fastest increment at the beginning, slowest deceleration close to the end
- spike-out: Slowest increment at the beginning, fastest acceleration close to the end
- spike-in-out: Fastest increment at the beginning, slow half way, fastest acceleration close to the end
--down-sec <SEC>
How long the ramp-down transition should last
[default: 10]
-v, --verbose...
Verbose logging.
* none = 'WARN'
* '-v' = 'INFO'
* '-vv' = 'DEBUG'
* '-vvv' = 'TRACE'
Alternatively, set environment variable 'KSUNAMI_LOG=(ERROR|WARN|INFO|DEBUG|TRACE|OFF)'.
-q, --quiet...
Quiet logging.
* none = 'WARN'
* '-q' = 'ERROR'
* '-qq' = 'OFF'
Alternatively, set environment variable 'KSUNAMI_LOG=(ERROR|WARN|INFO|DEBUG|TRACE|OFF)'.
-h, --help
Print help information (use `-h` for a summary)
-V, --version
Print version information
示例
以下是您可以使用 Ksunami 做的一些示例。这不是一个详尽的集合,但它可以为您提供一个良好的起点,也许还能给您一些灵感。
注意 示例中的参数以
{{ PARAMETER_NAME }}的形式表示。
连接到需要 SASL_SSL 的 Kafka 集群
$ ksunami \
--brokers {{ BOOTSTRAP_BROKERS or BROKER_ENDPOINT }} \
--config security.protocol:SASL_SSL \
--config sasl.mechanisms=PLAIN \
--config sasl.username:{{ USERNAME or API_KEY }} \
--config sasl.password:{{ PASSWORD or API_SECRET }} \
--topic {{ TOPIC_NAME }} \
...
最小/最大 日志详细程度
# Set logging to TRACE level
$ ksunami ... -vvv
# Set logging to OFF level
$ ksunami ... -qq
# Set logging to ERROR level, via env var
KSUNAMI_LOG=ERROR ksunami ...
每秒记录数低,但每天一次爆发,持续 60 秒
$ ksunami \
--topic {{ ONCE_A_DAY_SPIKE_TOPIC }} \
... \
--min-sec 86310 \ # i.e. 24h - 90s
--min 10 \ # most of the day, this topics sees 10 rec/sec
\
--up-sec 10 \ # transitions from min to max within 10 sec
--up spike-in \ # sudden jump: 10k rec/sec
\
--max-sec 60 \ # a spike of just 60s
--max 10000 \ # producing at 10k rec/sec
\
--down-sec 20 \ # transitions from max to min within 20 sec
--down spike-out \ # sudden drop: back to just 10 rec/sec
...
在 24 小时周期内以波浪模式记录
$ ksunami \
--topic {{ WAVY_TOPIC }} \
... \
--min-sec 21600 \ # first quarter of the day
--min 1000 \ # 1k rec/sec
\
--up-sec 21600 \ # second quarter of the day
--up ease-in-out \ # stable rise
\
--max-sec 21600 \ # third quarter of the day
--max 3000 \ # 3k rec/sec
\
--down-sec 21600 \ # fourth quarter of the day
--down ease-in-out \ # stable decline
...
无论键如何,都向 随机分区 生成
$ ksunami \
--topic {{ RANDOMLY_PICKED_PARTITION_TOPIC }} \
... \
--partitioner random
使用随机字母数字 key 生成记录,但固定来自文件的 payload
$ ksunami \
--topic {{ RANDOM_KEYS_FIXED_PAYLOADS_TOPIC }} \
... \
--key alpha:{{ RANDOM_ALPHANUMERIC_STRING_LENGTH }} \
--payload file:{{ PATH_TO_LOCAL_FILE }} \
...
生产从 min 切换到 max(以及返回)而没有 过渡
$ ksunami \
--topic {{ NO_TRANSITON_TOPIC }} \
... \
--min-sec 120 \
--min 100 \
\
--up none \ # switch from min to max after 120s
\
--max-sec 60 \
--max 1000 \
\
--down none \ # switch from max to min after 60s
...
核心概念
4 个阶段
Ksunami 是围绕用户对 Kafka 集群有一个特定的“工作负载模式”进行设计的,他们希望对其进行复制。这可能是一个稳定且从未改变的,或者它可以是定期波动的记录,与定期发生的剧烈峰值交错。或者,您可能有一个新客户,这将带来更多流量到您的 Kafka 集群。
我们决定将此类工作负载描述为 4 个阶段,即 min, up, max, down,这些阶段无限期地重复。
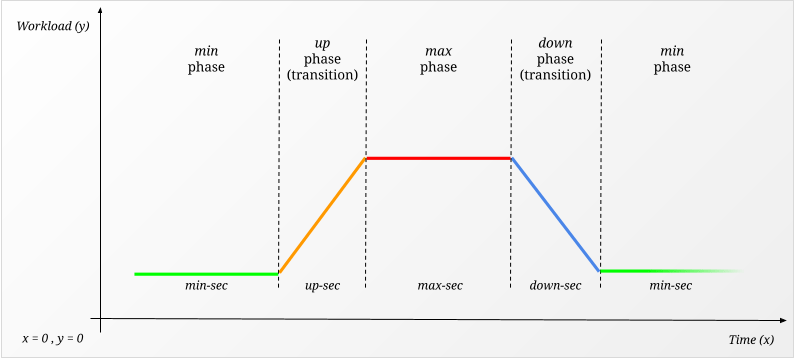
每个阶段都与一个 *-sec 持续时间参数相关联,以选择每个阶段应该有多长时间。此外,min 和 max 与每秒记录数(即 工作负载)相关联,而 up 和 down 与一个 过渡 相关联。
过渡
在 min 和 max 阶段之间移动时,会遍历 up 和 down 阶段。这些阶段是“过渡性的”:Ksunami 允许描述阶段之间如何过渡。每个过渡都有一个 名称,并且对应于一个 三次贝塞尔曲线:留给读者去了解这类曲线,简而言之,三次贝塞尔曲线描述了穿过 4 个控制点 的 插值,即 P0, P1, P2, P3。
想象一下,我们想在笛卡尔平面上,在 min 和 max 阶段之间绘制一个 up 转变。时间用 x 表示,我们考虑的变换区间为 x = [0..1],作为变换的开始和结束。而产生的记录量用 y 表示,也考虑在区间 y = [0..1]。
基于这个前提,P0=(0,0) 和 P3=(1,1) 代表 up 转变的开始和结束;P0=(0,1) 和 P3=(1,0) 则代表 down 转变的开始和结束。
我们的转变曲线被 包围 在边界框内 (0,0), (1,0), (1,1), (0,1),我们可以通过在这个边界框内放置 P1 和 P2 来描述各种类型的曲线。以下是目前 Ksunami 支持的转变名称列表,绘制了 up 和 down 阶段的图表
| 转变 | --up<TRANSITION_TYPE> |
--down<TRANSITION_TYPE> |
|---|---|---|
none |
- | - |
linear |
||
ease-in |
||
ease-out |
||
ease-in-out |
||
spike-in |
||
spike-out |
||
spike-in-out |
请注意:在上面的图片中,P0 和 P3 没有改变,但所有变化都是通过移动 P1 和 P2 生成的。
是的! 可以通过选择新的 P1 和 P2 点,并将这些添加到新的 Transition 枚举 值中来定义额外的变化。欢迎提交 PR。
深度配置
首先,先看一下 使用 部分。如果还不够,在本节中我们将更深入地探讨 Ksunami 最重要的配置方面。
配置生产者
除了明显的 -b, --brokers 用于引导代理,以及 --client-id 用于客户端标识符之外,还可以通过 --partitioner 和 -, --config 对提供者进行微调。
分区器
--partitioner 参数的可能值
| 分区器名称 | 描述 |
|---|---|
random |
随机分布 |
consistent |
CRC32散列键(空和NULL键映射到单个分区) |
consistent_random(默认) |
CRC32散列键(空和NULL键随机分区) |
murmur2 |
Java生产者兼容的Murmur2散列键(NULL键映射到单个分区) |
murmur2_random |
Java生产者兼容的Murmur2散列键(NULL键随机分区):相当于Java生产者中的默认分区器 |
fnv1a |
FNV-1a散列键(NULL键映射到单个分区) |
fnv1a_random |
FNV-1a散列键(NULL键随机分区) |
注意:基于 librdkafka 的 Ksunami 只提供了该库提供的分区器。
例如,要使用一个 完全随机的分区器
$ ksunami ... --partitioner random ...
附加配置
根据 -, --config,Ksunami 的生产者支持由 librdkafka 提供的所有配置值。
例如,要设置一个 200ms 生产者挂起 并将 生产者发送重试次数限制为 5
$ ksunami ... -c linger.ms:200 ... --config message.send.max.retries:5 ...
记录:目的地和内容
您可以配置 Ksunami 生成的每个记录的内容
-, --topic <TOPIC>:要发送记录的目的地主题-, --key <KEY_TYPE:INPUT>(可选):记录的键-, --payload <PAYLOAD_TYPE:INPUT>(可选):记录的有效载荷--partition <PARTITION>(可选):目的地主题内的特定分区--head <HEAD_KEY:HEAD_VAL>(可选):一个或多个要装饰记录的头信息
对于 --topic、--partition 和 --head,输入相当直观,而 --key 和 --payload 支持更丰富的选项集。
支持的 key 和 payload 类型
| 格式 | 描述 |
|---|---|
string:STR |
STR 是一个普通字符串 |
file:PATH |
PATH 是指向现有文件的路径 |
alpha:LENGTH |
LENGTH 是随机字母数字字符串的长度 |
bytes:LENGTH |
LENGTH 是随机字节数组的长度 |
int:MIN-MAX |
MIN 和 MAX 是一个包含范围的限制,从该范围中选取一个整数 |
浮点数:MIN-MAX |
MIN 和 MAX 是一个包含范围的限制,从该范围中选取一个浮点数 |
这允许在记录内部放置的内容有一定的灵活性。
例如,要生成记录,其中 键是介于 1 和 1000 之间的整数,且 有效载荷是 100 个字节的随机序列
$ ksunami ... --key int:1-1000 --payload bytes:100
记录:数量和持续时间
如上所述,当我们引入 4 个阶段 时,Ksunami 将工作负载模式视为一系列持续时间、工作负载量和转换。
最小值和最大值
min 和 max 阶段表示用户想要描述的工作负载范围,一旦设置,Ksunami 将循环地从 min 到 max 再到 min 等等。工作负载以 每秒记录数 表示,每个阶段的持续时间为秒。
为什么是秒? 因为它足够小,可以描述任何有意义的 Kafka 工作负载。使用更小的单位不会带来真正的益处。而使用更大的单位,会导致工作负载描述过于粗糙。
用于配置 min 和 max 的参数
| 参数 | 描述 | 默认值 |
|---|---|---|
--min<每秒记录数> |
每秒记录数的最小值 | |
--min-sec<秒> |
在提升之前,以最小记录数每秒生产的时间长度 | 60 |
--max<每秒记录数> |
每秒记录数的最大值 | |
--max-sec<秒> |
在减少之前,以最大记录数每秒生产的时间长度 | 60 |
(提升) 上和下
再次,如 上文所示,在 min 和 max 阶段之间有 2 个过渡阶段:up 和 down。
它们存在是为了描述随着时间的推移工作负载的变化。Ksunami 提供了一系列 转换,它们作为参数提供:Ksunami 会将上文中显示的 [0..1] 曲线转换成用户想要的实际每秒记录数工作负载。
用于配置 up 和 down 的参数
| 参数 | 描述 | 默认值 |
|---|---|---|
--up<TRANSITION_TYPE> |
从最小记录数每秒到最大记录数每秒的提升转换 | linear |
--up-sec<秒> |
提升转换应持续多长时间 | 10 |
--down<TRANSITION_TYPE> |
从最大记录数每秒到最小记录数每秒的减少转换 | none |
--down-sec<秒> |
减少转换应持续多长时间 | 10 |
日志详细程度
Ksunami 遵循了 -v/-q 的长传统来控制其日志的详细程度
| 参数 | 日志详细程度级别 | 默认值 |
|---|---|---|
-qq... |
关闭 |
|
-q |
错误 |
|
| none | 警告 |
x |
-v |
信息 |
|
-vv |
调试 |
|
-vvv... |
跟踪 |
它使用 log 和 env_logger,因此可以通过环境变量 KSUNAMI_LOG 来配置和微调日志。请参阅 env_logger 文档 了解更多详情。
许可证
根据您选择许可以下之一
- Apache License,版本 2.0 (LICENSE-APACHE 或 https://apache.ac.cn/licenses/LICENSE-2.0)
- MIT 许可证 (LICENSE-MIT 或 https://open-source.org.cn/licenses/MIT)
任选其一。
贡献
除非您明确说明,否则根据Apache-2.0许可证定义,您有意提交以包含在作品中的任何贡献,应按上述方式双重许可,不附加任何额外条款或条件。
谢谢
- 感谢这个页面在Desmos图形计算器上,提供了绘制三次贝塞尔曲线的简单方法。
- 感谢flo_curves提供易于操作的Rust crate来处理贝塞尔曲线。
- 感谢librdkafka作为出色的Kafka库,几乎所有Kafka客户端都在使用它,并感谢Rust绑定rdkafka。
- 感谢clap,它是最棒的命令行参数解析器。
依赖项
~36–51MB
~880K SLoC