4个版本
| 新增 0.2.2 | 2024年8月19日 |
|---|---|
| 0.2.1 | 2024年8月19日 |
| 0.2.0 | 2024年8月15日 |
| 0.1.0 | 2024年8月9日 |
在算法类别中排名第420
每月下载量207次
71KB
1.5K SLoC
![]()
![]()
![]()
HyperTwoBits 是一种概率数据结构,用于估计集合中不同元素的数量。它具有与 HyperLogLog 相同的使用场景,但使用更少的内存,在达到大致相似的精度的情况下速度更快。在数值上,当 HyperLogLog 使用每个子流六个比特时,正如其名称所示,HyperTwoBits 使用两个比特。
为了说明链接的论文页面14中的表4
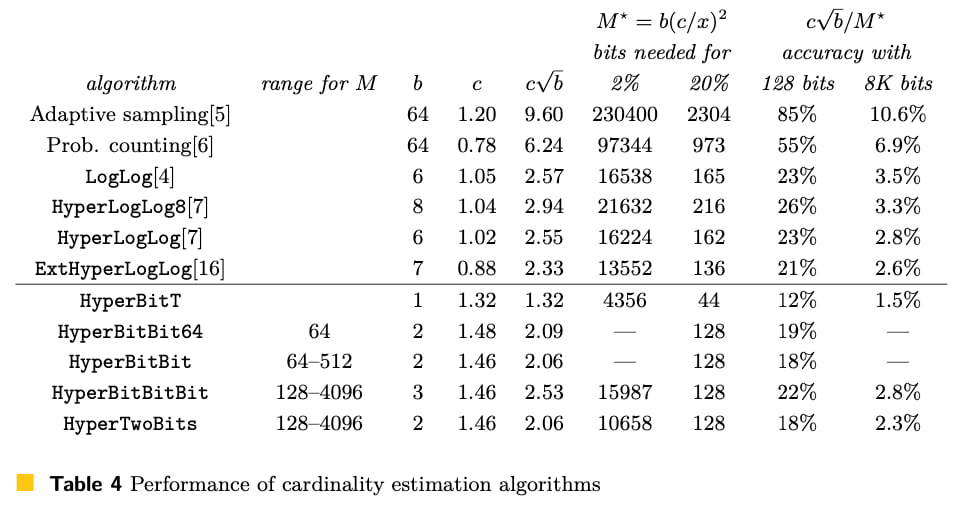
本实现以几种方式改进了所提出的算法。
- 它在栈中保留整个草图,而不进行堆分配。
- 它默认使用
ahash进行哈希,但您可以使用任何实现了std::hash::AHasherBuilder的哈希器。 - 它使用特质来从运行时执行中删除分支。
- 它将尽可能多的计算移动到常量或编译时评估。
- 它移除了浮点比较,改为整数运算。它使用128位整数以尽可能利用宽寄存器。
- 它使用内建函数来计数1,而不是在二进制逻辑中计算它们。
- 它更改了草图中的高/低位寄存器布局,以便将每个区域的内存放置在一起。
- 它添加了微批量函数,当同时提供两个或四个值时可以提高性能。
示例
use hypertwobits::{HyperTwoBits, M512};
let mut htb = HyperTwoBits::<M512>::default();
htb.insert(&"foo");
htb.insert(&"bar");
htb.count();
带种子哈希与不带种子哈希
默认情况下,HyperTwoBits 使用 ahash 作为哈希器。此哈希器默认情况下没有使用随机值进行种子。这意味着相同的输入将始终产生相同的输出。
与HashMap不同,这种做法暴露的攻击面很小。唯一利用这种方法的方式是构建一个会故意返回不精确结果的输入。这对于大多数用例来说都不是问题。
然而,我们提供了 AHasherBuilder,它创建用于种子哈希器的随机状态。这种权衡是这将会更慢,使用更多的内存,并且意味着草图不能再合并。
基准测试
基于基准测试,它比HyperLogLogPlus快约2倍,比HyperBitBit快1.5倍,或者当使用非种子哈希函数时分别快4倍和2.5倍。
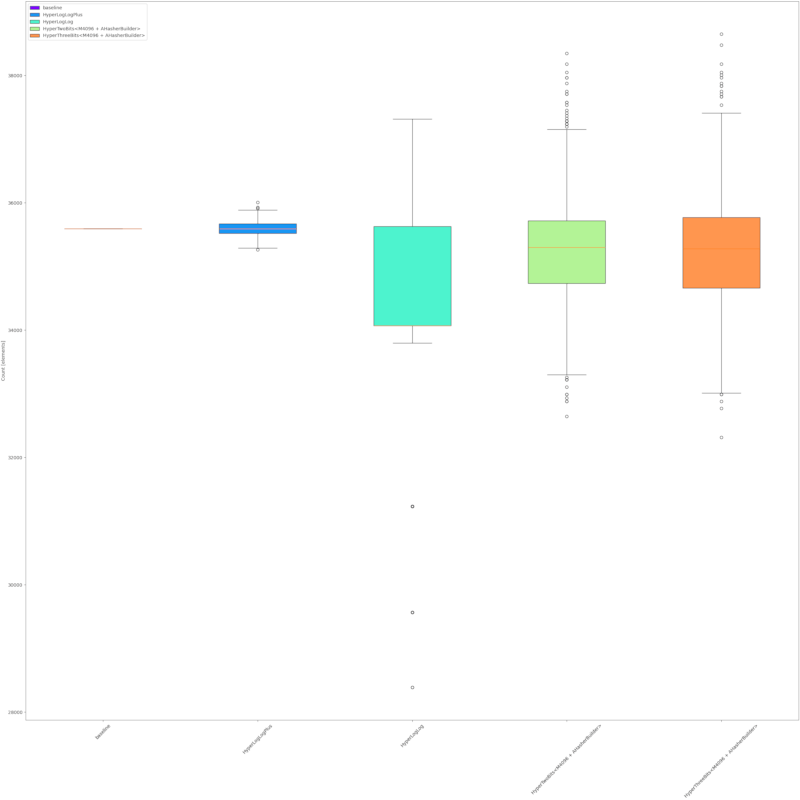
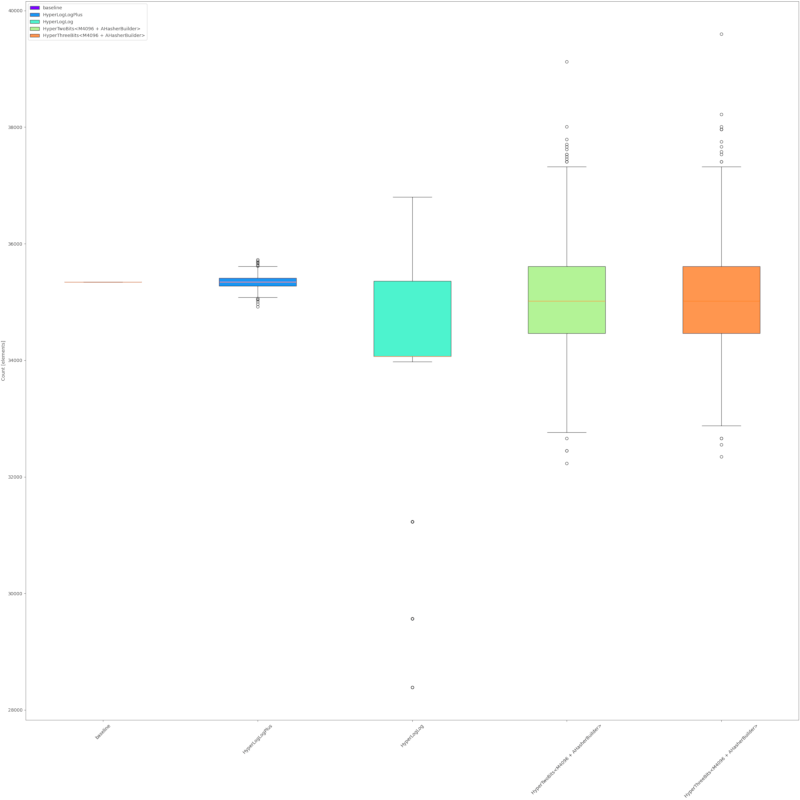
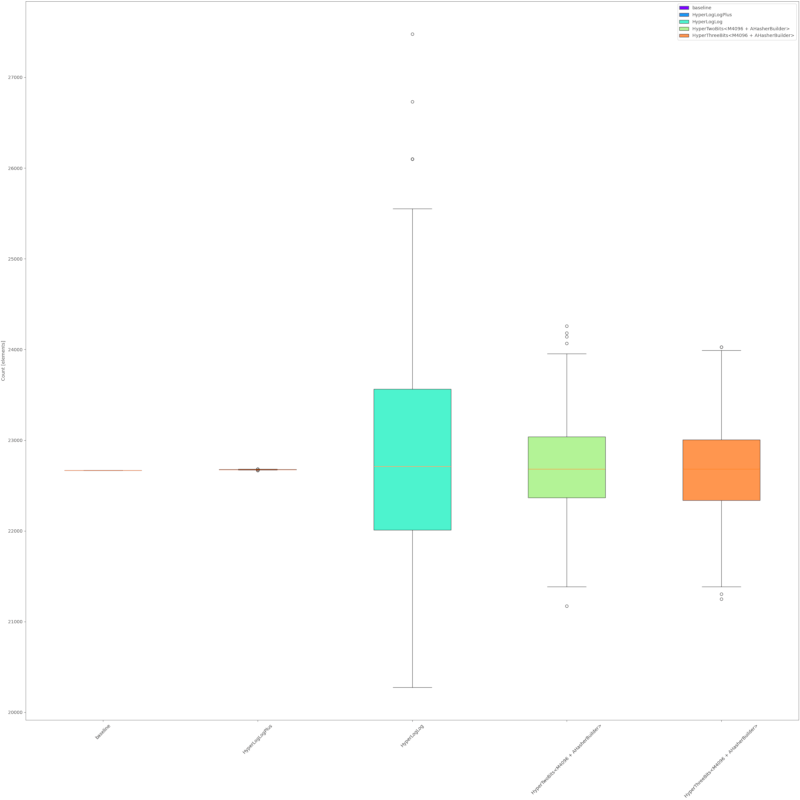
准确性
HyperTwoBits的准确性与HyperLogLog大致相似,但明显低于HyperLogLogPlus。以下是基于示例输入的一些测量结果
莎士比亚
尤利西斯
战争与和平
依赖项
~0.9–1.3MB
~20K SLoC