2个版本
| 0.1.1 | 2021年12月15日 |
|---|---|
| 0.1.0 | 2021年12月14日 |
在编程语言类别中排名757
1.5MB
2K SLoC

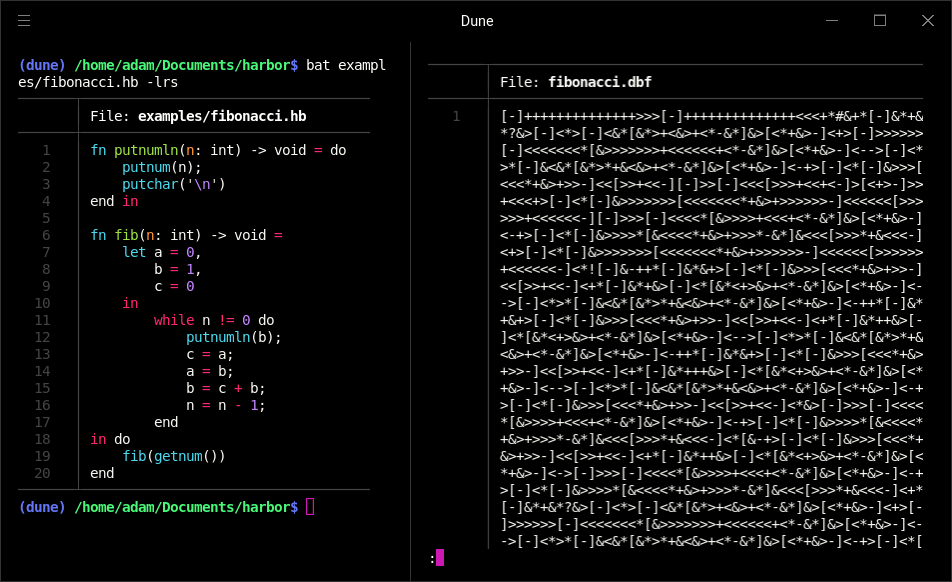
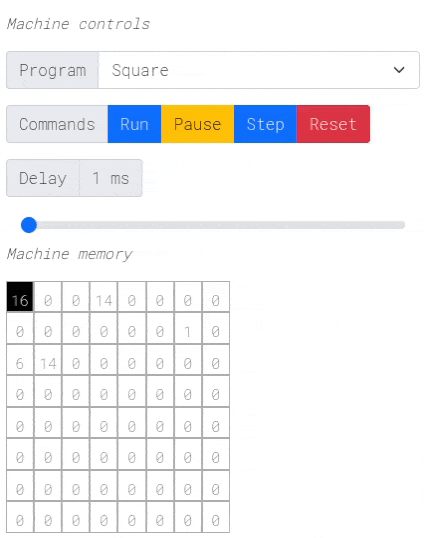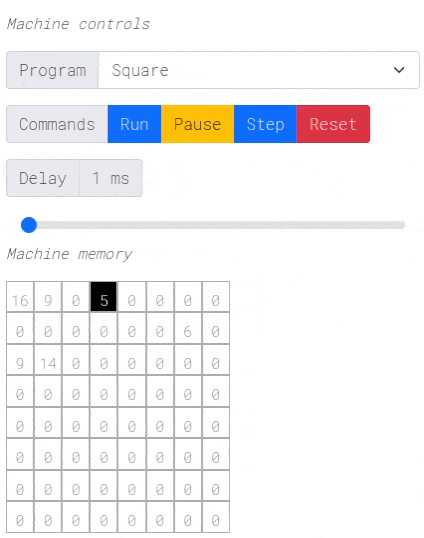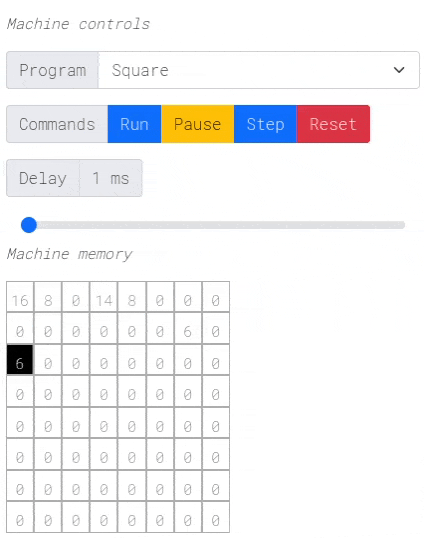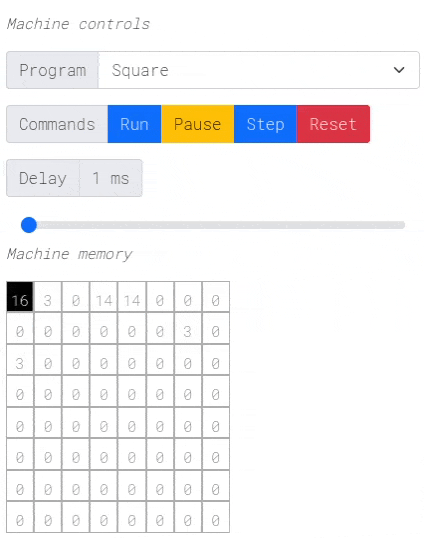
注意:点击上面的图片进行交互式演示!
关于作者
我是一名19岁的大学二年级学生,正在做一些项目来打发时间。如果你喜欢我的工作,请考虑通过买我一杯咖啡来支持我!

这个项目是什么?
Harbor是一种具有类型检查(支持无符号整数、布尔值、字符、指针、元组)和手动内存管理的面向高级的编程语言。这意味着什么?Harbor基本上是C语言的简化版本。Harbor有什么特别之处?Harbor可以将代码编译成Brainf***方言,称为Dynamic Brainf***。
Brainf***程序完全由以下操作符组成仅此而已

| 操作符 | 描述 |
|---|---|
| < | 将指针移动到左侧的单元格。 |
| > | 将指针移动到右侧的单元格。 |
| + | 将当前单元格的值增加1。 |
| - | 将当前单元格的值减少1。 |
| [ | 如果指针指向的单元格的值不为零,开始循环。 |
| ] | 标记循环体的结束。 |
| , | 将当前单元格的值设置为输入的下一个字节的值。 |
| . | 将当前单元格的值作为字节输出。 |
Dynamic Brainf***提供了六个额外的操作符:两个用于内存管理,两个用于指针操作,以及两个用于更好的I/O。有了这些新操作符,可以编译常见的抽象,如引用、栈操作和复合数据类型。
| 操作符 | 描述 |
|---|---|
| ? | 读取当前单元格的值,并在磁带末尾分配那么多单元格。然后,将当前单元格的值设置为该分配块中第一个单元格的索引。 |
| ! | 读取当前单元格的值,并从该索引开始释放分配的单元格。 |
| * | 将指针推入栈中,并将指针设置为当前单元格的值。 |
| & | 从引用的栈中弹出旧指针,并将指针设置为它。 |
| # | 将当前单元格设置为输入缓冲区中的下一个整数(类似于scanf("%d", &tape[pointer]))。 |
| $ | 将当前单元格作为整数输出(类似于printf("%d", tape[pointer]))。 |
为了让您了解Dynamic Brainf***添加的内容有多么少,在这个编译器中,负责组装Dynamic Brainf***的代码仅有24行!您只需使用字符串替换就能为其编写一个编译器!
它是如何工作的?
Harbor源代码在输出代码之前需要经过三个阶段:HIR、MIR和LIR。
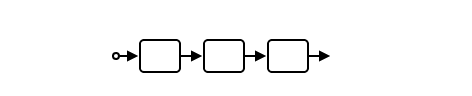
HIR提供类型系统并执行类型检查,MIR提供一个小型无类型逆波兰表示汇编语言,而LIR是针对生成代码优化的Dynamic Brainf***的内部表示。
编译过程最有趣的部分是从Harbor MIR到Dynamic Brainf***的转换。Harbor MIR看起来是这样的


内存布局
MIR提供14个寄存器
SP:栈指针。FP:帧指针。TMP0到TMP5:6个临时寄存器,用于帮助进行算术操作。这些是编译器专用的。R0到R5:6个通用寄存器,供用户使用。
寄存器由编译器在最初的14个单元格中静态分配,栈紧随其后。

您可能会注意到FP奇怪地位于TMP0和TMP1之后,但在TMP2之前。这有一个很好的原因:在Brainf***方言中复制内存单元格是一个非常昂贵(并且非常频繁)的操作。当复制内存时,它使用TMP0作为缓冲区
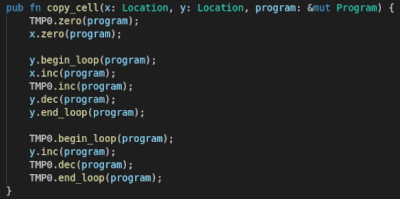
因此,TMP0被放置在FP之前以提高局部性(移动到TMP0的指针需要更少的周期),但我想效果微乎其微。TMP1也被放置在FP之前,原因类似:它几乎在所有的算术操作中都被频繁使用。TMP2到TMP5是更专门的寄存器,主要用于整数除法、乘法以及设置函数的栈帧和活动记录。
MIR操作码
| 操作码 | 描述 |
|---|---|
set123 |
弹出地址并在该地址存储值 |
=(内部称为 |
弹出地址并将值弹出至该地址。还可以选择一个大小参数,用于指定存储在地址中的单元格数量,例如:%int、%(%int, %bool)或%char。 |
@(内部称为 |
弹出地址并从该地址加载值。还可以使用可选的大小参数从地址加载,例如:%int,%(%int, %int),或%char。 |
get %int(在内部称为 Stalloc) |
将给定大小的内存块推入堆栈。%int 分配一个单元格,%(%int, %int) 分配 2,等等。 |
dump %int(在内部称为 Stfree) |
根据给定大小释放堆栈上的内存块(%int 为一个单元格)。 |
123 |
整型文字被推入堆栈。 |
+ |
从堆栈中弹出两个数字并推入它们的和。 |
- |
从堆栈中弹出两个数字并推入它们的差。 |
* |
从堆栈中弹出两个数字并推入它们的乘积。 |
/ |
从堆栈中弹出两个数字并推入它们的商。 |
== |
从堆栈中弹出两个数字并推入它们的相等性。 |
!= |
从堆栈中弹出两个数字并推入它们的不等性。 |
| |
从堆栈中弹出两个数字并推入它们的逻辑或(任何非零值都是真)。 |
& |
从堆栈中弹出两个数字并推入它们的逻辑与。 |
! |
从堆栈中弹出数字并推入它的逻辑补码。 |
alloc |
从堆栈中弹出数字,在磁带末尾分配那么多单元格,并推入分配块的地址。 |
free |
从堆栈中弹出地址并释放该块中的单元格。 |
dup |
复制堆栈顶部的单元格。 |
frame%int-> %(%int, %int) do ...end |
为接受参数并返回值的代码块创建堆栈帧。FP 指向第一个参数,当代码块在帧被销毁后结束,返回值被留在堆栈上。 |
if (2 4 *) do ...end |
执行 if 语句。不支持 else 子句:这很复杂,但本质上嵌套的 if-else 语句会覆盖彼此在堆栈中保存的条件。 |
$R0,$R1,...,$R5 |
将寄存器的值推入堆栈。 |
&R0,&R1,...,&R5 |
将寄存器的地址推入堆栈。 |
此外,MIR 还定义了 6 个预定义宏。宏 putnum 和 putchar 都会从堆栈中弹出一个单元格并打印它。宏 getchar 从用户输入中检索一个字节并将其推送到堆栈。宏 getnum 从用户输入中检索一个整数并将其推送到堆栈。最后,宏 inc 和 dec 会增加或减少堆栈顶部值所指向的值。
MIR 操作码由一种有趣的“微码”组成,编写和优化起来都很有趣。加法操作码的代码生成器很好地说明了这一点。
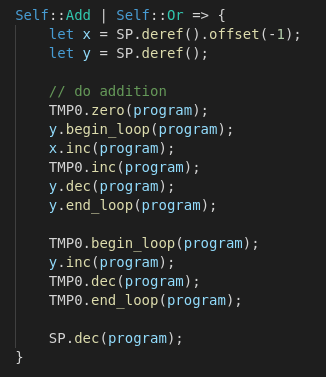

最初,我通过将两个值弹出放入临时寄存器(TMP1 和 TMP2)来执行加法,然后将结果推送到堆栈来实现加法。这种解决方案效率更高,因为所有操作都是在原地完成的,而不是在内存中移动值!
看到优化后的输出代码的结果也非常令人满意:因为 Brainf*** 中实现的似乎都是 O(n^2) 的级别,所以任何内存使用的减少似乎都有显著的影响。
这些微码块也可以非常长:除法操作多达 60 条指令!
Harbor 前端
与 MIR 相比,Harbor 的前端要舒适得多;看它你会认为它是一种糟糕的语言!
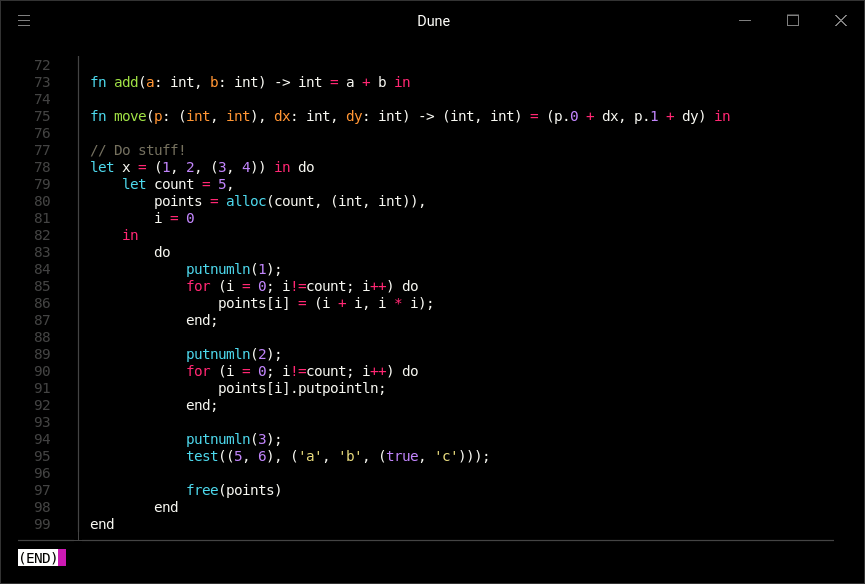
Harbor 支持函数调用时的方法语法,let 类型推断,带索引的指针 [] 和解引用 * 操作符,元组,堆分配的字符串字面量以及严格的类型系统。
它的语法受到了 Rust 的启发,但有一些小问题。由于 MIR 内部表示作用域和帧的方式,以显式链式方式实现表达式变得简单得多。
let z = 11 in
putnum((let x = 5,
y = 6 in x + y * z))
使用这种语法,作用域会在每个单独的表达式上显式创建和销毁:通过为每个 let 表达式创建一个框架,并在 let 体结束时销毁它来管理。

因为方法调用只是函数调用的语法糖,所以用户需要一种替代方法来以指针的形式传递“self”参数。为此,我将 & 的优先级提高,使其在 . 和 -> 操作符之前执行。所以,在上面的例子中,表达式 &n.inc.square->putnumln 会扩展为 putnumln(*square(inc(&n)))。我知道这个语法对熟悉指针的人来说看起来很混乱,但由于严格的类型系统,它不可能被误用。
递归问题
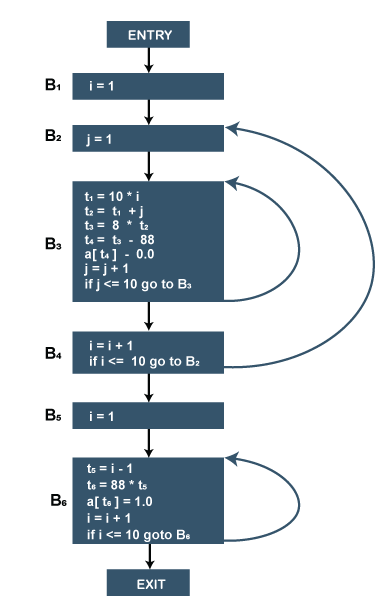
这似乎是 Harbor 在其领域真正缺少的地方。由于编译器的设计方式,基本上不可能以合理的方式实现递归。
在像Brainf***这样的语言中,唯一的控制流方法是循环,实现具有作用域的函数已经足够困难:没有跳转到任意指令的机制,模拟函数调用和栈帧是非常困难的。
这可以通过一种方法来实现,即将代码块划分为“基本块”:代码块中没有跳转,从开始到结束。这简化了程序的结构,使得执行过程中不会出现跳转:控制流只需要在基本块之间监控和管理,这可以通过传统的if语句和while循环轻松完成!
然而,不幸的是,在我实现编译器的大部分功能时,我不知道这个解决方案,而且实现它可能需要花费太长时间。需要注意的是,可以将递归的函数式代码编译为Dynamic Brainf***。
读者练习
- LLVM或x86 Dynamic Brainf***编译器:Harbor将其输出编译为C语言,但针对LLVM或x86的其他编译器将是一个重大的改进。
- 反向工程优化Dynamic Brainf***编译器:由于Harbor编译代码的方式,可以通过反向工程输出代码轻松应用优化。例如:每个MIR算术栈操作总是编译成相同的结果。为了优化编译的Dynamic Brainf***代码,只需将负责操作码的代码编译为实际操作码操作,而不是执行数百个小的Brainf***操作来实现相同的效果!有了这样的编译器,Harbor可以像未优化的C语言一样高效(这句话让我感到羞愧)!
- 硬件实现:想象一下在本地运行这种可怕的语言!所有的调试都很有趣,但用示波器代替shell!
- Minecraft Brainf***实现:实现一个5或6位的Dynamic Brainf***机器(最小可能的地址大小是5位,因为4位只留下2个栈单元)是完全可能的(而且非常困难),可能还有简化的IO,可以在本地运行这个编译器的输出代码!
使用方法
要安装和使用,您必须下载Rust编程语言。
开发构建
# Install directly from git with cargo
cargo install --git https://github.com/adam-mcdaniel/harbor
# Or, alternatively, the repo and install from source
git clone https://github.com/adam-mcdaniel/harbor
cd harbor
cargo install -f --path .
发布版本
要获取当前发布版本,请从crates.io安装。
# Also works for updating harbor
cargo install -f harborc
安装后
# Just run the harbor executable!
harbor
依赖关系
~9–18MB
~249K SLoC