5个版本
| 0.1.0 | 2022年8月1日 |
|---|---|
| 0.0.4-alpha | 2022年7月24日 |
| 0.0.0 |
|
#319 在 并发 分类中
999 每月下载量
565KB
1.5K SLoC
无锁的、部分无等待的、最终一致性并发哈希表。
此映射实现允许在某些平台上始终无等待地执行读取,并且几乎与从Arc<HashMap<K, V>>中读取一样便宜。此外,如果执行频率足够低,则从单个线程执行写入将有效地无等待,并且读者不会长时间持有守卫。
为了实现极低的读取成本,写入只能从单个线程执行,并且最终一致性。换句话说,当执行写入时,所有读取线程只有在完成最后一次读取并开始新的读取之后才会观察到写入。
flashmap 与其他有何不同?
此处使用的底层算法,从原则上讲,与 evmap 使用的算法相同。然而,该算法的实现已被修改,以显著提高读取性能,代价是必要的API更改和写入者不同的性能特征。有关算法实现细节的更多信息,请参阅 algorithm 模块。
何时使用 flashmap
flashmap 适用于读密集型到几乎只读的工作负载,其中单个写入者是可以接受的。良好的用例包括
- 高频率读取,偶尔插入/删除
- 通过内部可变性以低争用率频繁修改现有条目,偶尔插入/删除
- 高频率读取,另一线程执行适度的写入工作负载
不使用 flashmap 的情况包括
- 频繁的小型写入,无法批量处理
- 多线程并发写入访问
示例
use flashmap;
// Create a new map; this function returns a write handle and a read handle
// For more advanced options, see the `Builder` type
let (mut write, read) = flashmap::new::<String, String>();
// Create a write guard to modify the map
let mut write_guard = write.guard();
write_guard.insert("foo".to_owned(), "bar".to_owned());
write_guard.insert("fizz".to_owned(), "buzz".to_owned());
write_guard.insert("baz".to_owned(), "qux".to_owned());
// Publish all previous changes, making them visible to new readers. This has
// the same effect as dropping the guard.
write_guard.publish();
// You must also create a guard from a read handle to read the map, but this
// operation is cheap
assert_eq!(read.guard().get("fizz").unwrap(), "buzz");
// You can clone read handles to get multiple handles to the same map...
let read2 = read.clone();
use std::thread;
// ...and do concurrent reads from different threads
let t1 = thread::spawn(move || {
assert_eq!(read.guard().get("foo").unwrap(), "bar");
read
});
let t2 = thread::spawn(move || {
assert_eq!(read2.guard().get("baz").unwrap(), "qux");
read2
});
let read = t1.join().unwrap();
let _ = t2.join().unwrap();
// Read guards see a "snapshot" of the underlying map. You need to make a new
// guard to see the latest changes from the writer.
// Make a read guard
let read_guard = read.guard();
// Do some modifications while the read guard is still live
let mut write_guard = write.guard();
write_guard.remove("fizz".to_owned());
write_guard.replace("baz".to_owned(), |old| {
let mut clone = old.clone();
clone.push('!');
clone
});
// Make changes visible to new readers
write_guard.publish();
// Since the read guard was created before the write was published, it will
// see the old version of the map
assert!(read_guard.get("fizz").is_some());
assert_eq!(read_guard.get("baz").unwrap(), "qux");
// Drop and re-make the read guard
drop(read_guard);
let read_guard = read.guard();
// Now we see the new version of the map
assert!(read_guard.get("fizz").is_none());
assert_eq!(read_guard.get("baz").unwrap(), "qux!");
// We can continue to read the map even when the writer is dropped
drop(write);
assert_eq!(read_guard.len(), 2);
// The resources associated with the map are deallocated once all read and
// write handles are dropped
// We need to drop this first since it borrows from `read`
drop(read_guard);
// Deallocates the map
drop(read);
性能
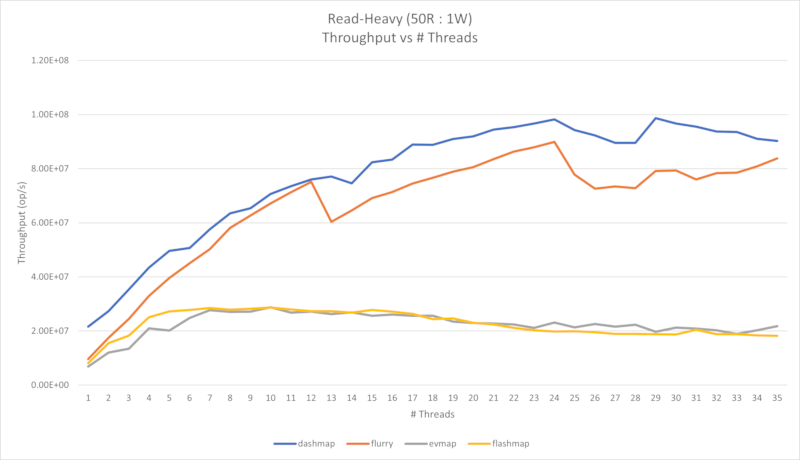
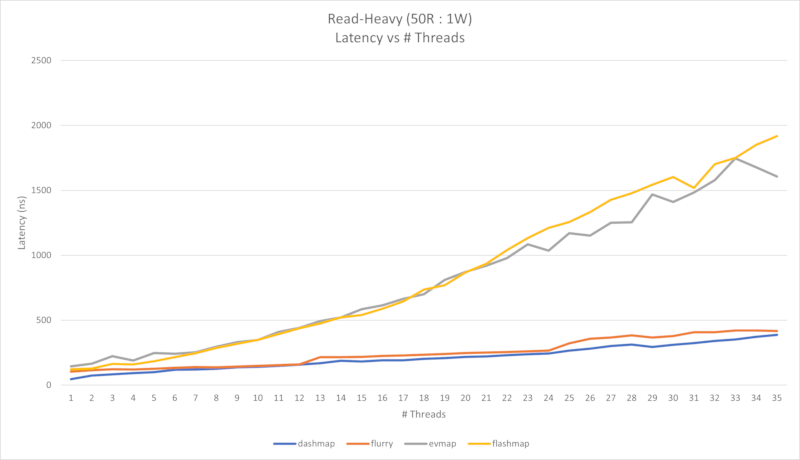
以下显示了四个性能图表。第一个是几乎只读的工作负载(每1个写入有2500次读取),第二个是读密集型工作负载(每1个写入有50次读取)。
这些基准测试是在AMD 9 Ryzen 5900X 12核心CPU(12个物理核心,24个逻辑核心)上进行的,该CPU使用x86-64架构。读密集型工作负载使用 conc-map-bench 进行测量,几乎只读工作负载是通过使用修改版的 bustle 进行测量的,以便将读取百分比偏移到99%以上。
在第一种情况下,我们可以看到吞吐量几乎呈线性增长,直到物理核心数,而逻辑核心数的增长则较小。似乎在逻辑核心数之后可能会出现极端的延迟峰值,但这一现象的原因尚未确定。
在第二种用例中,当并发增加时,flashmap和evmap都会受到影响。这是因为它们是单写者映射,因此为了允许多个线程并发写入,写者需要被封装在互斥锁中。在读取密集型情况下,限制因素实际上是互斥锁,因为与读取相比,写入要昂贵得多。如果您需要从多个线程写入映射,请对您的代码进行基准测试以确定您是否处于第一种情况或第二种情况。
点击显示“查看...图表”的文本以查看图表。您也可以再次点击文本来折叠图表。
查看几乎只读图表
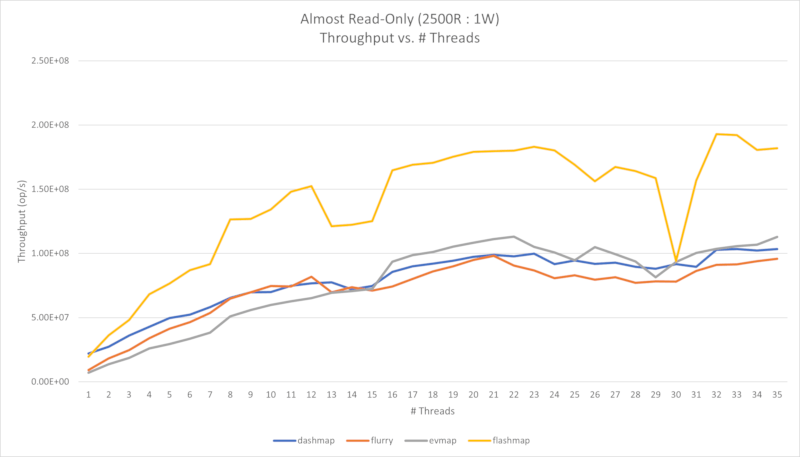
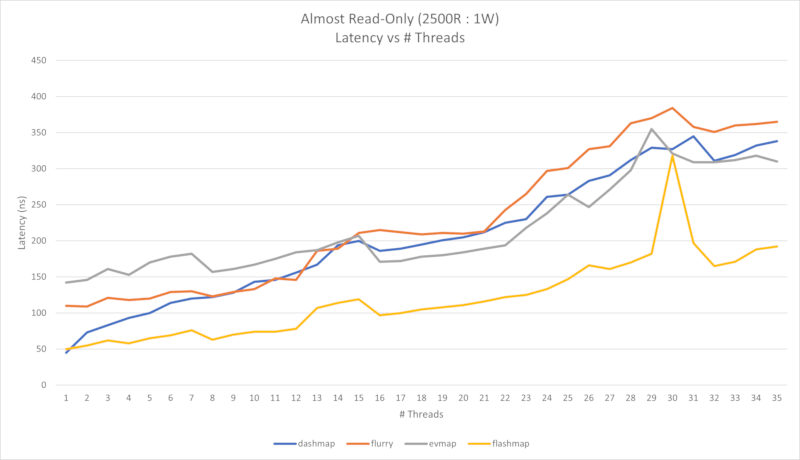
查看读取密集型图表
依赖关系
~0.7–27MB
~345K SLoC