13 个版本
| 新 0.7.1 | 2024 年 8 月 18 日 |
|---|---|
| 0.6.6 | 2024 年 7 月 16 日 |
| 0.6.3 | 2024 年 2 月 16 日 |
| 0.6.1 | 2023 年 11 月 6 日 |
| 0.5.3 | 2023 年 2 月 25 日 |
#537 在 命令行工具
每月 252 次下载
185KB
356 行
findlargedir
![]()
![]()
![]()

(由 Esther Arzola 的 Ferris the Detective 提供,原始设计由 Karen Rustad Tölva 提供)
关于
Findlargedir 是一个专门编写的工具,旨在帮助快速识别任何文件系统中的“黑洞”目录,这些文件系统具有超过 10 万个条目的单个扁平结构。当目录具有许多条目(目录或文件)时,获取目录列表的速度会越来越慢,影响所有尝试获取目录列表的进程的性能(例如,删除一些文件和/或查找一些特定文件)。在读取大型目录inode时,进程会冻结,并最终在更长的时间内进入不可中断的休眠状态(“D”状态)。根据文件系统的不同,这可能在 10 万个条目时开始变得明显,并在 1M+ 条目时开始对性能产生非常明显的影响。
这样的目录即使在内容清理后也无法缩小,因为大多数 Linux 和 Unix 文件系统不支持目录inode缩小(例如,非常常见的 ext3/ext4)。这通常发生在被遗忘的 Web 会话目录(GC 间隔设置为几天),各种缓存目录(CMS 编译模板和缓存),POSIX 文件系统模拟对象存储等。
程序将尝试识别任何数量此类事件,并根据校准,即每个文件系统每个目录inode中假设的目录条目数量来报告它们。在执行此操作时,它将确定目录inode增长比与条目/inode数之比,并使用该比例快速扫描文件系统,避免执行昂贵的/慢的目录查找。虽然有许多工具可以扫描文件系统(find,du,ncdu等),但它们都没有使用启发式方法来避免昂贵的查找,因为它们被设计为 完全准确,而此工具旨在使用启发式方法和在不卡在问题文件夹的情况下发出警报。
程序将不会遵循符号链接,并且需要对校准目录进行读写权限,以便计算目录inode大小与条目数量的比率,并估计目录中的条目数量而无需实际计数。虽然这种方法只是对目录中实际条目数量的近似,但它足以快速扫描受影响的目录。
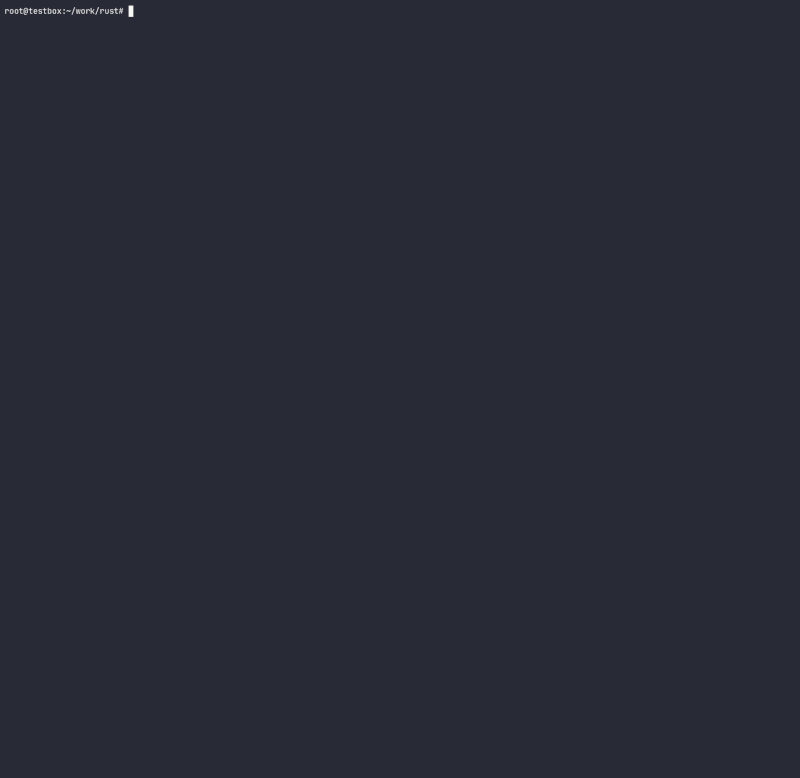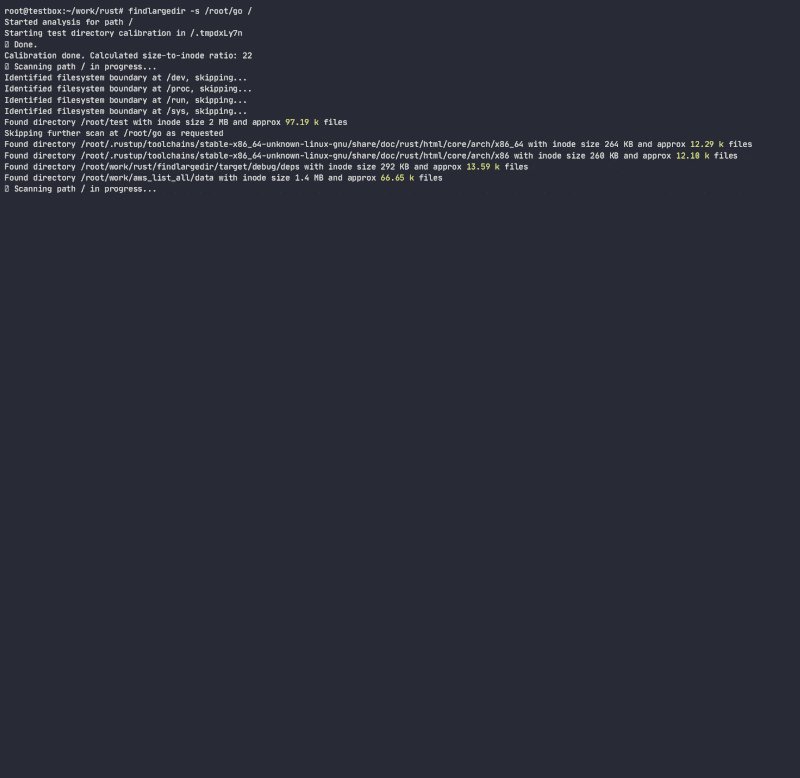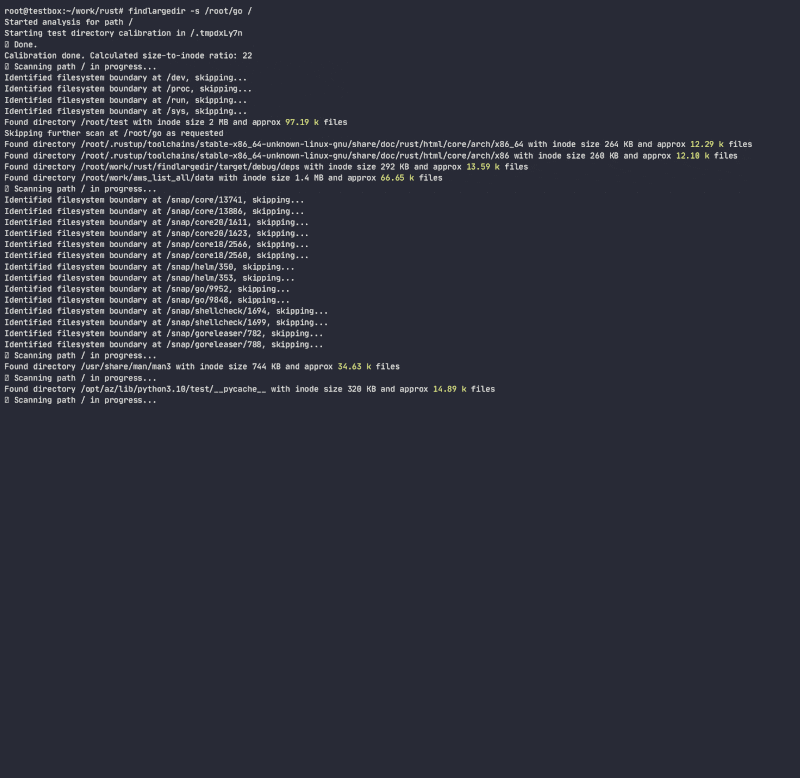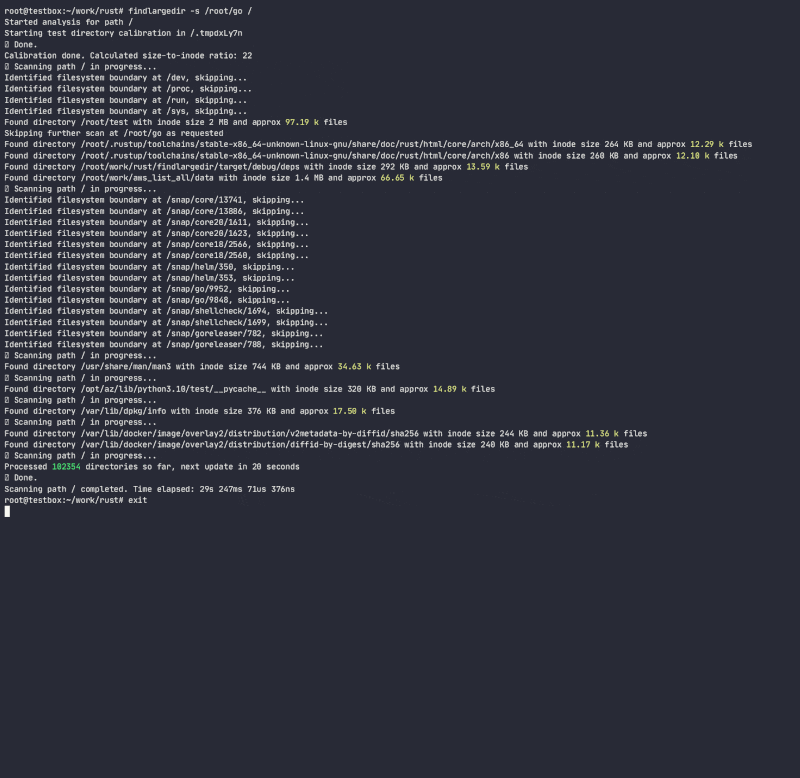
注意事项
- 需要测试每个文件系统的读写权限,它还会创建一个包含许多临时文件的临时目录,之后会被清理。
- 精确模式(
-a)可能会引起过多的I/O和内存使用;仅在必要时使用。
用法
Usage: findlargedir [OPTIONS] <PATH>...
Arguments:
<PATH>... Paths to check for large directories
Options:
-a, --accurate <ACCURATE>
Perform accurate directory entry counting [default: false] [possible values: true, false]
-o, --one-filesystem <ONE_FILESYSTEM>
Do not cross mount points [default: true] [possible values: true, false]
-c, --calibration-count <CALIBRATION_COUNT>
Calibration directory file count [default: 100000]
-A, --alert-threshold <ALERT_THRESHOLD>
Alert threshold count (print the estimate) [default: 10000]
-B, --blacklist-threshold <BLACKLIST_THRESHOLD>
Blacklist threshold count (print the estimate and stop deeper scan) [default: 100000]
-x, --threads <THREADS>
Number of threads to use when calibrating and scanning [default: 24]
-p, --updates <UPDATES>
Seconds between status updates, set to 0 to disable [default: 20]
-i, --size-inode-ratio <SIZE_INODE_RATIO>
Skip calibration and provide directory entry to inode size ratio (typically ~21-32) [default: 0]
-t, --calibration-path <CALIBRATION_PATH>
Custom calibration directory path
-s, --skip-path <SKIP_PATH>
Directories to exclude from scanning
-h, --help
Print help information
-V, --version
Print version information
当使用精确模式(-参数)时,请注意,对大型目录的查找可能会导致进程在较长时间内完全停滞。此模式基本上是在可能受影响的目录上进行第二次完整精确的遍历,计算确切的条目数量。
为了避免深入挂载的文件系统(如find -xdev选项),默认情况下会切换到参数单文件系统模式(-参数),但在必要时可以禁用。
可以通过手动提供目录inode大小与条目数量的比率来完全跳过校准阶段,使用-参数。只有在已知比率的情况下才合理,例如从前面的运行中。
将-参数设置为0将停止程序提供偶尔的状态更新。
基准测试
Findlargedir与GNU find的比较
中端服务器/机械存储
硬件:8核心Xeon E5-1630,4盘SATA RAID-10
基准测试设置
$ cat bench1.sh
#!/bin/dash
exec /usr/bin/find / -xdev -type d -size +200000c
$ cat bench2.sh
#!/bin/dash
exec /usr/local/sbin/findlargedir /
使用hyperfine测量的实际结果
$ hyperfine --prepare 'echo 3 | tee /proc/sys/vm/drop_caches' \
./bench1.sh ./bench2.sh
Benchmark 1: ./bench1.sh
Time (mean ± σ): 357.040 s ± 7.176 s [User: 2.324 s, System: 13.881 s]
Range (min … max): 349.639 s … 367.636 s 10 runs
Benchmark 2: ./bench2.sh
Time (mean ± σ): 199.751 s ± 4.431 s [User: 75.163 s, System: 141.271 s]
Range (min … max): 190.136 s … 203.432 s 10 runs
Summary
'./bench2.sh' ran
1.79 ± 0.05 times faster than './bench1.sh'
高端服务器/SSD存储
硬件:48核心Xeon Silver 4214,7盘SM883 SATA HW RAID-5阵列,2TB内容(数十个小文件的容器)
相同的基准测试设置。结果
$ hyperfine --prepare 'echo 3 | tee /proc/sys/vm/drop_caches' \
./bench1.sh ./bench2.sh
Benchmark 1: ./bench1.sh
Time (mean ± σ): 392.433 s ± 1.952 s [User: 16.056 s, System: 81.994 s]
Range (min … max): 390.284 s … 395.732 s 10 runs
Benchmark 2: ./bench2.sh
Time (mean ± σ): 34.650 s ± 0.469 s [User: 79.441 s, System: 528.939 s]
Range (min … max): 34.049 s … 35.388 s 10 runs
Summary
'./bench2.sh' ran
11.33 ± 0.16 times faster than './bench1.sh'
星历史

依赖关系
~8–18MB
~259K SLoC