2 个版本
使用旧 Rust 2015
| 0.1.1 | 2016 年 8 月 27 日 |
|---|---|
| 0.1.0 | 2016 年 8 月 27 日 |
#2135 在 算法
738 每月下载次数
在 3 crates 中使用
31KB
320 行
Eudex:一个闪电般的音位缩减/散列算法。
Eudex ([juːˈdɛks]) 是一种类似于 Soundex 的音位缩减/散列算法,提供基于拼写和发音的词语的局部敏感“散列”。
它基于肺音辅音的分类(见下文)。
Eudex 比 Soundex 快两个数量级,比 Levenshtein 距离快几个数量级,使得它在极短的时间内运行大量字符串成为可能。
特性
- 基于发音的高质量局部敏感散列。
- 与英语、加泰罗尼亚语、德语、西班牙语、意大利语和瑞典语等语言兼容,但不仅限于这些语言。
- 复杂的音位映射。
- 比 Soundex 质量更好。
- 考虑非英语字母。
- 极快。
- 算法指定(见下文部分)。
- 对元音敏感。
常见问题解答
为什么 Rupert 和 Robert 没有像 Soundex 一样映射到相同的值? Eudex 不是一个音位分类器,它是一个音位散列器。它以显示差异的方式映射词语。Soundex 不提供任何形式的细微度量,只有“相似”和“不相似”。
结果看起来完全是随机的。有什么问题吗? 这可能是因为你假设相似发音的词语的散列值会映射得接近,而实际上并非如此。相反,它们的汉明距离(即异或值并求和它们的位)会很低。《distance` 现在考虑了这一点。
我担心稳定性。值会变化吗?。是的!我们鼓励你指定 Cargo 的修订版,以获得完全的稳定性,或者使用 `similar` 函数,其基本行为不会改变。
它支持非英语字母吗? 是的,它支持所有 C1 字母(例如,ü、ö、æ、ß、é 等),并考虑了它们的相应发音。
它是仅限英语的吗? 不是,它也适用于大多数欧洲语言。然而,它限于拉丁字母。
它是如何工作的? 下面将进行描述。
它考虑双字母组合吗? 表格设计用于封装双字母组合,尽管没有为这些组合单独的表格(如 Metaphone)。
它是 Levenshtein 的替代品吗? 它 不是 Levenshtein 距离的替代品,它在某些用例中是 Levenshtein 距离的替代品,例如查找拼写检查建议。
它测试了哪些语言? 它在英语、加泰罗尼亚语、德语、西班牙语、瑞典语和意大利语词典上进行了测试,并且在这些词典上均被证实质量良好。
它似乎将哈希限制为8或16个字符? 它没有这样的限制,但是出于平台和性能的考虑,哈希值仅受前N个字符的影响。结果发现,这对质量的影响很小,几乎没有影响。此外,这种限制不是算法本身的一部分,而是这个算法的实现。
实现
- Rust:此仓库。
- Java:jprante/elasticsearch-analysis-phonetic-eudex
- JavaScript:Yomguithereal/talisman
示例
extern crate eudex;
use eudex::Hash;
fn main() {
assert!((Hash::new("jumpo") - Hash::new("jumbo")).similar());
assert!(!(Hash::new("Horse") - Hash::new("Norse")).similar());
println!("{:?}", Hash::new("hello"));
}
Cargo
将以下内容添加到您的 Cargo.toml
[dependencies.eudex]
git = "https://github.com/ticki/eudex.git"
Eudex背后的黑暗魔法
算法本身相当简单。它输出一个8字节数组(一个无符号64位整数)
A00BBBBB
||/\___/
|| |
|| Trailing phones
||
|Padding
|
First phone
关键点是,所有字符都通过一个精心设计的表映射,该表是根据它们的语音分类得出的,以便使发音相似的音素具有较低的汉明距离。
如果两个连续的音素共享所有位,但奇偶校验位(即,a >> 1 = b >> 1),则第二个音素将被跳过。
表是使其有趣的地方。有四个表:一个用于第一个槽位中的ASCII字母(不是字符,而是字母),一个用于第一个槽位中的C1(拉丁补充)字符,一个用于尾随音素中的ASCII字母,以及一个用于尾随音素中的C1(拉丁补充)字符。
Eudex中元音和辅音之间有一个关键的区别。第一个音素将元音视为一等公民,通过区分元音的所有属性来做出区分。尾随音素仅在开口元音和闭口元音之间有所区分。
让我们从尾随字符的表开始。辅音的字节被处理成每个位代表音素(即,发音)的一个属性(即,右最位除外,它用于标记重复项,充当判别器)。
让我们看看IPA辅音的分类

您可能会注意到,字符通常代表多个音素,并且在特定上下文中确定给定字符代表哪个音素可以非常困难。因此,我们必须尽最大努力将每个字符放入正确的语音类别中。
我们必须智能地选择分类。表中不包含某些组,其中之一在分类中很有用:液体辅音(侧辅音+半闭元音),即 r 和 l。在理想条件下,这些应该放入不同的位,但不幸的是,一个字节中只有8位,所以我们不得不限制自己。
现在,每个好的语音哈希器都应该能够将重要字符(例如,拼写困难、对单词发音至关重要的字符)与其他字符分开。因此,我们添加了一个我们称为“自信”的类别,它将占据最高有效位。在我们的“自信”字符类别中,我们放入l、r、x、z和q,因为这些要么
- 对单词的声音至关重要(因此更容易听到,更难拼错)。
- 很少出现,因此从统计上讲更难犯错误。
因此,我们的最终尾随辅音表看起来像这样
| 位置 | 修饰符 | 属性 | 音素 |
|---|---|---|---|
| 1 | 1 | 判别器 | (用于标记重复项) |
| 2 | 2 | 鼻音 | mn |
| 3 | 4 | 摩擦音 | fvsjxzhct |
| 4 | 8 | 爆破音 | pbtdcgqk |
| 5 | 16 | 齿音 | tdnzs |
| 6 | 32 | 液体 | lr |
| 7 | 64 | 唇音 | bfpv |
| 8 | 128 | 自信¹ | lrxzq |
特性对手机音质越重要,其位置就越高。
接下来,我们需要处理元音。特别是,我们不太关心末尾位置的元音,所以我们将它们简单地分为两类:开口和闭口。值得注意的是,并非所有元音都落入这些类别,因此我们将它们简单地放入与之“最接近”的类别,例如,a、(e)、o在“开口”类别中得0分。
因此,我们最终的末尾音素ASCII字母表看起来像
(for consonants)
+--------- Confident
|+-------- Labial
||+------- Liquid
|||+------ Dental
||||+----- Plosive
|||||+---- Fricative
||||||+--- Nasal
|||||||+-- Discriminant
||||||||
a* 00000000
b 01001000
c 00001100
d 00011000
e* 00000001
f 01000100
g 00001000
h 00000100
i* 00000001
j 00000101
k 00001001
l 10100000
m 00000010
n 00010010
o* 00000000
p 01001001
q 10101000
r 10100001
s 00010100
t 00011101
u* 00000001
v 01000101
w 00000000
x 10000100
y* 00000001
z 10010100
| (for vowels)
+-- Close
现在,我们以同样的方法将表扩展到C1字符
(for consonants)
+--------- Confident
|+-------- Labial
||+------- Liquid
|||+------ Dental
||||+----- Plosive
|||||+---- Fricative
||||||+--- Nasal
|||||||+-- Discriminant
||||||||
ß -----s-1 (use 's' from the table above with the last bit flipped)
à 00000000
á 00000000
â 00000000
ã 00000000
ä 00000000 [æ]
å 00000001 [oː]
æ 00000000 [æ]
ç -----z-1 [t͡ʃ]
è 00000001
é 00000001
ê 00000001
ë 00000001
ì 00000001
í 00000001
î 00000001
ï 00000001
ð 00010101 [ð̠] (represented as a non-plosive T)
ñ 00010111 [nj] (represented as a combination of n and j)
ò 00000000
ó 00000000
ô 00000000
õ 00000000
ö 00000001 [ø]
÷ 11111111 (placeholder)
ø 00000001 [ø]
ù 00000001
ú 00000001
û 00000001
ü 00000001
ý 00000001
þ -----ð-- [ð̠] (represented as a non-plosive T)
ÿ 00000001
| (for vowels)
+-- Close
到目前为止,我们已经考虑了末尾音素,现在我们需要看看第一个音素。第一个音素需要一个具有最小冲突的表,因为你几乎不会拼写单词的第一个字母。理想情况下,该表应该是单射的,但由于技术限制,这是不可能的。
我们将使用第一个位来区分元音和辅音。
之前我们只将元音分为两类,现在我们将改变这一点,但首先:辅音。为了避免重复,我们将使用上述表的复用方法。
由于最不重要的属性放在左边,我们只需将其向右移动(即截断最右边的一位)。然后,在遇到重复时将最低有效位翻转。这样,我们保留了低汉明距离,同时避免了冲突。
元音更有趣。我们需要一种方法来区分元音及其声音。
幸运的是,它们的分类相当简单
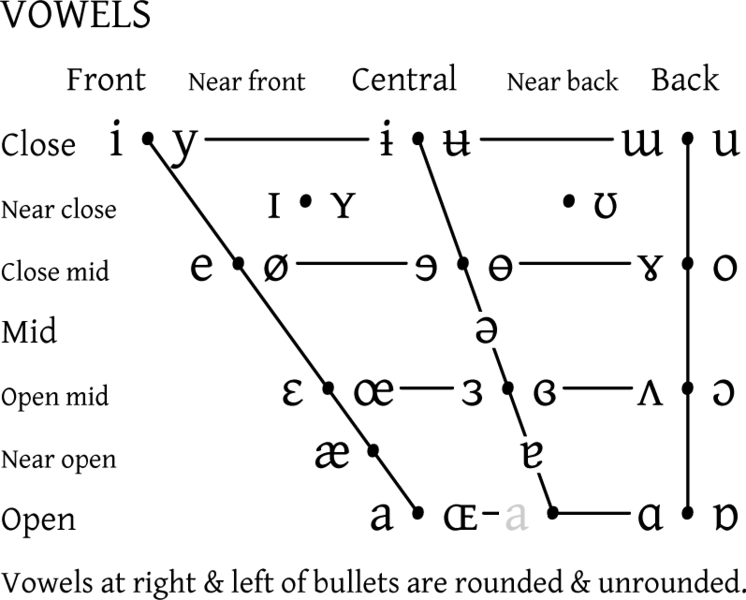
如果一个元音作为两个音素出现(例如,取决于语言),我们将它们进行或运算,并可能修改区分度,如果它与另一个音素冲突。
我们需要将每个轴划分为超过两个类别,以利用所有位,因此某些属性将不得不占用多个位。
| 位置 | 修饰符 | 属性(元音) |
|---|---|---|
| 1 | 1 | 判别器 |
| 2 | 2 | 它是开口中音吗? |
| 3 | 4 | 它是中心音吗? |
| 4 | 8 | 它是闭口中音吗? |
| 5 | 16 | 它是前音吗? |
| 6 | 32 | 它是闭音吗? |
| 7 | 64 | 比[ɜ]更接近闭音 |
| 8 | 128 | 是元音吗? |
因此,我们利用了这两个属性,即开口和“前音”。此外,我们允许的不仅仅是二进制选择
Class Close Close-mid Open-mid Open
+----------+----------+-----------+---------+
Bits .11..... ...11... ......1. .00.0.0.
让我们对另一个轴做同样的处理
Class Front Central Back
+----------+----------+----------+
Bits ...1.0.. ...0.1.. ...0.0..
我们将这些属性进行组合,即将这些表进行或运算。应用此技术,我们得到
(for vowels)
+--------- Vowel
|+-------- Closer than ɜ
||+------- Close
|||+------ Front
||||+----- Close-mid
|||||+---- Central
||||||+--- Open-mid
|||||||+-- Discriminant
||||||||
a* 10000100
b 00100100
c 00000110
d 00001100
e* 11011000
f 00100010
g 00000100
h 00000010
i* 11111000
j 00000011
k 00000101
l 01010000
m 00000001
n 00001001
o* 10010100
p 00100101
q 01010100
r 01010001
s 00001010
t 00001110
u* 11100000
v 00100011
w 00000000
x 01000010
y* 11100100
z 01001010
然后将其扩展到C1字符
+--------- Vowel?
|+-------- Closer than ɜ
||+------- Close
|||+------ Front
||||+----- Close-mid
|||||+---- Central
||||||+--- Open-mid
|||||||+-- Discriminant
||||||||
ß -----s-1 (use 's' from the table above with the last bit flipped)
à -----a-1
á -----a-1
â 10000000
ã 10000110
ä 10100110 [æ]
å 11000010 [oː]
æ 10100111 [æ]
ç 01010100 [t͡ʃ]
è -----e-1
é -----e-1
ê -----e-1
ë 11000110
ì -----i-1
í -----i-1
î -----i-1
ï -----i-1
ð 00001011 [ð̠] (represented as a non-plosive T)
ñ 00001011 [nj] (represented as a combination of n and j)
ò -----o-1
ó -----o-1
ô -----o-1
õ -----o-1
ö 11011100 [ø]
÷ 11111111 (placeholder)
ø 11011101 [ø]
ù -----u-1
ú -----u-1
û -----u-1
ü -----y-1
ý -----y-1
þ -----ð-- [ð̠] (represented as a non-plosive T)
ÿ -----y-1
现在我们有了我们的表。我们现在需要距离运算符。一个简单的方法是简单地使用汉明距离。这有一个缺点,即所有字节具有相同的权重,这并不理想,因为您更有可能拼错后面的字符,而不是第一个字符。
因此,我们使用加权汉明距离
| 字节 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 权重 | 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
也就是说,我们将两个值进行异或运算,然后为每个字节的汉明权重加上表中的系数。
这为我们提供了一个高质量的单词度量。