4个稳定版本
| 1.2.0 | 2022年9月21日 |
|---|---|
| 1.1.0 | 2022年9月21日 |
| 1.0.1 | 2022年9月19日 |
| 1.0.0 | 2022年9月18日 |
#207 in 性能分析
每月 87 次下载
36KB
410 行
测量CPU核心到核心延迟
![]()
![]()
![]()
我们测量了CPU通过其缓存一致性协议向另一个CPU发送消息所需的延迟。
通过将两个线程固定在两个不同的CPU核心上,我们可以使它们执行大量的比较交换操作,并测量延迟。
运行方法
$ cargo install core-to-core-latency
$ core-to-core-latency
单插槽结果
| CPU | 中值延迟 |
|---|---|
| Intel Core i9-12900K,8P+8E核心,Alder Lake,第12代,2021-Q4 | 35ns,44ns,50ns |
| Intel Core i9-9900K,3.60GHz,8核心,Coffee Lake,第9代,2018-Q4 | 21ns |
| Intel Core i7-1165G7,2.80GHz,4核心,Tiger Lake,第11代,2020-Q3 | 27ns |
| Intel Core i7-6700K,4.00GHz,4核心,Skylake,第6代,2015-Q3 | 27ns |
| Intel Core i5-10310U,4核心,Comet Lake,第10代,2020-Q2 | 21ns |
| Intel Core i5-4590,3.30GHz 4核心,Haswell,第4代,2014-Q2 | 21ns |
| Apple M1 Pro,6P+2E核心,2021-Q4 | 40ns,53ns,145ns |
| Intel Xeon Platinum 8375C,2.90GHz,32核心,Ice Lake,第3代,2021-Q2 | 51ns |
| Intel Xeon Platinum 8275CL,3.00GHz,24核心,Cascade Lake,第2代,2019-Q2 | 47ns |
| Intel Xeon E5-2695 v4,2.10GHz,18核心,Broadwell,第5代,2016-Q1 | 44ns |
| AMD EPYC 7R13,48核心,Milan,第3代,2021-Q1 | 23ns,107ns |
| AMD Ryzen Threadripper 3960X,3.80GHz,24核心,Zen 2,第3代,2019-Q4 | 24ns,94ns |
| AMD Ryzen Threadripper 1950X,3.40GHz,16核心,Zen,第1代,2017-Q3 | 25ns,154ns |
| AMD Ryzen 9 5950X,3.40GHz,16核心,Zen3,第4代,2020-Q4 | 17ns,85ns |
| AMD Ryzen 9 5900X,3.40GHz,12核心,Zen3,第4代,2020-Q4 | 16ns,84ns |
| AMD Ryzen 7 5700X,3.40GHz,8核心,Zen3,第4代,2022-Q2 | 18ns |
| AMD Ryzen 7 2700X,3.70GHz,8核心,Zen+,第2代,2018-Q3 | 24ns,92ns |
| AWS Graviton3,64核心,Arm Neoverse,第3代,2021-Q4 | 46ns |
| AWS Graviton2,64核心,Arm Neoverse,第2代,2020-Q1 | 47ns |
| Sun/Oracle SPARC T4,2.85GHz,8核心,2011-Q3 | 98ns |
| IBM Power7,3.3GHz,8核心,2010-Q1 | 173ns |
| IBM PowerPC 970,1.8GHz,2核心,2003-Q2 | 576ns |
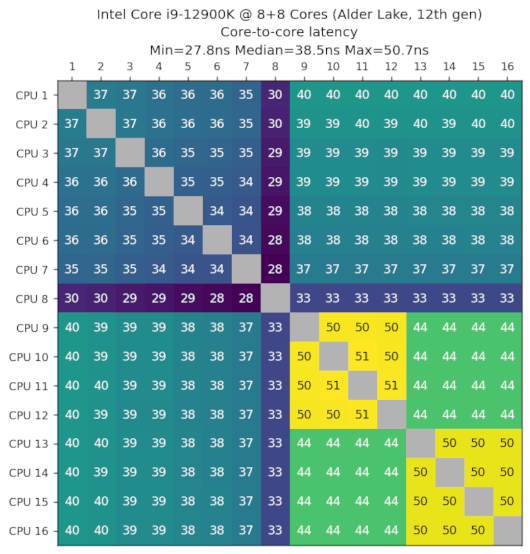
Intel Core i9-12900K,8P+8E核心,Alder Lake,第12代,2021-Q4
数据由 bizude 提供。
这款CPU拥有8个性能核心和2组4个高效核心。我们看到CPU=8,可以快速访问所有其他核心。
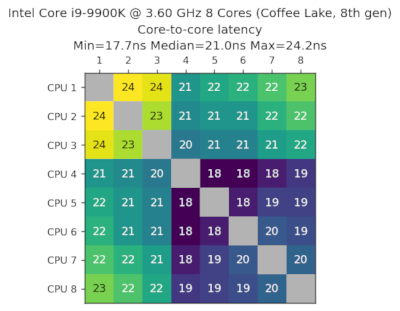
英特尔酷睿i9-9900K,3.60GHz,8核心,咖啡湖,第八代,2018年第四季度
我的游戏机,它的速度是其他面向服务器的CPU的两倍。
Intel Core i7-1165G7,2.80GHz,4核心,Tiger Lake,第11代,2020-Q3
数据由Jonas Wunderlich提供。

Intel Core i7-6700K,4.00GHz,4核心,Skylake,第6代,2015-Q3
数据由CanIGetaPR提供。

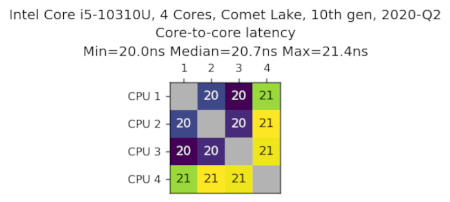
Intel Core i5-10310U,4核心,Comet Lake,第10代,2020-Q2
数据由Ashley Sommer提供。
英特尔酷睿i5-4590,3.30GHz,4核心,Haswell,第四代,2014年第二季度
数据由Felipe Lube de Bragança提供。

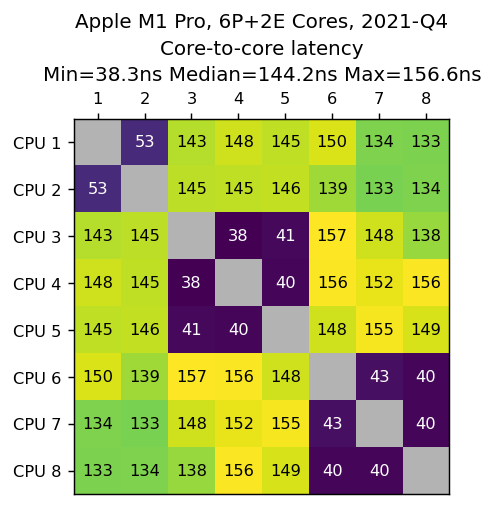
Apple M1 Pro,6P+2E核心,2021-Q4
数据由Aditya Sharma提供。
我们看到两个高效核心聚在一起,延迟为53ns,然后是两组3个性能核心,延迟为40ns。跨组通信速度慢,约为145ns,这在多插槽配置中通常可以看到的延迟。
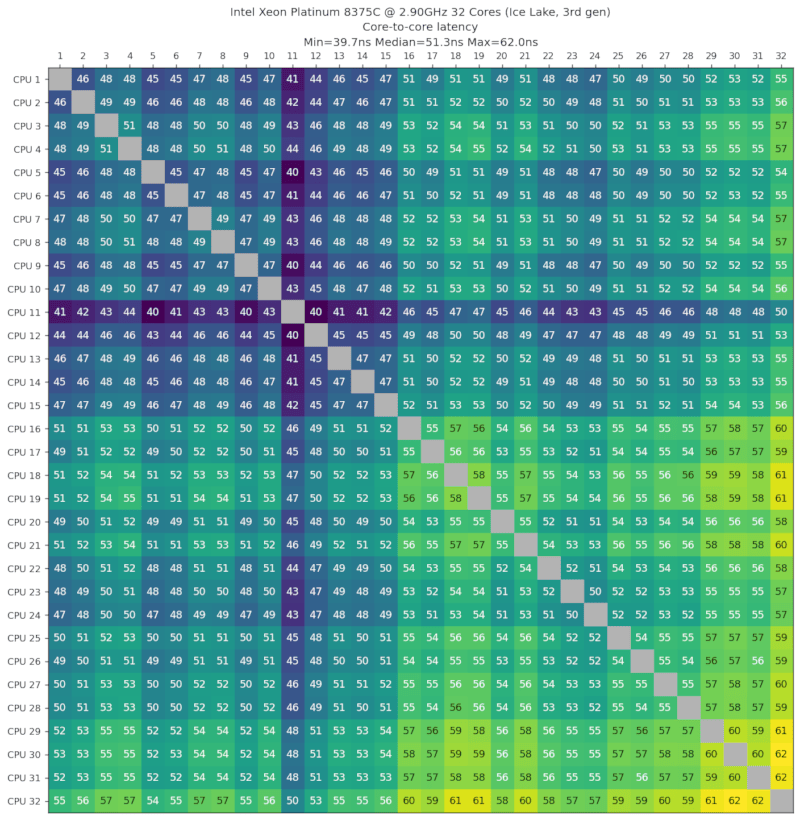
英特尔至强铂金8375C,2.90GHz,32核心,冰湖,第三代,2021年第二季度
来自AWS c6i.metal机器。
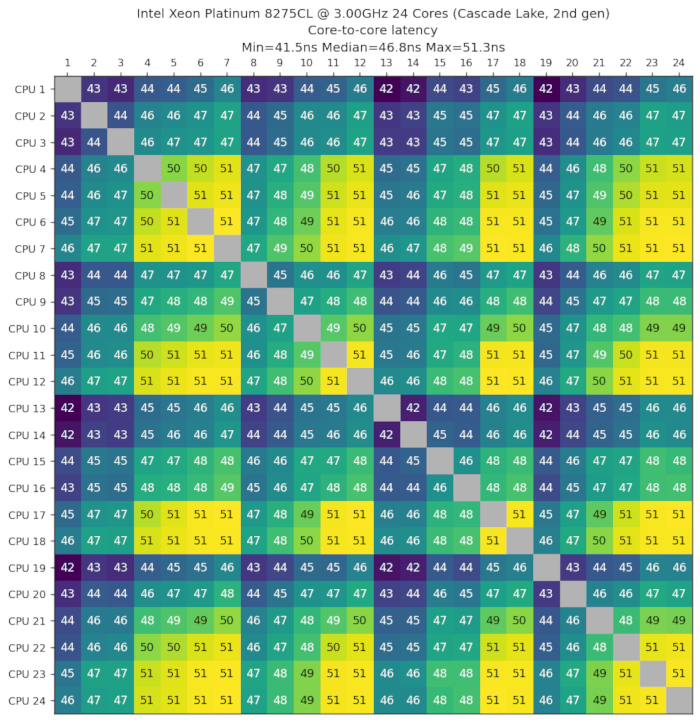
英特尔至强铂金8275CL,3.00GHz,24核心,Cascade Lake,第二代,2019年第二季度
来自AWS c5.metal机器。
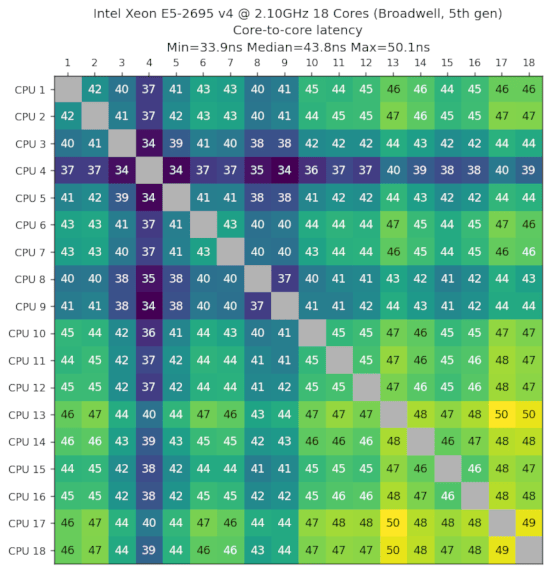
英特尔至强E5-2695 v4,2.10GHz,18核心,Broadwell,第五代,2016年第一季度
来自GTHost提供的机器。
AMD EPYC 7R13,48核心,Milan,第3代,2021-Q1
来自AWS c6a.metal机器。
我们可以看到核心以6组8个的方式排列,组内延迟优异(23ns)。当数据跨组时,延迟跳到大约110ns。请注意,最后3组跨组延迟比前3组更好(约90ns)。

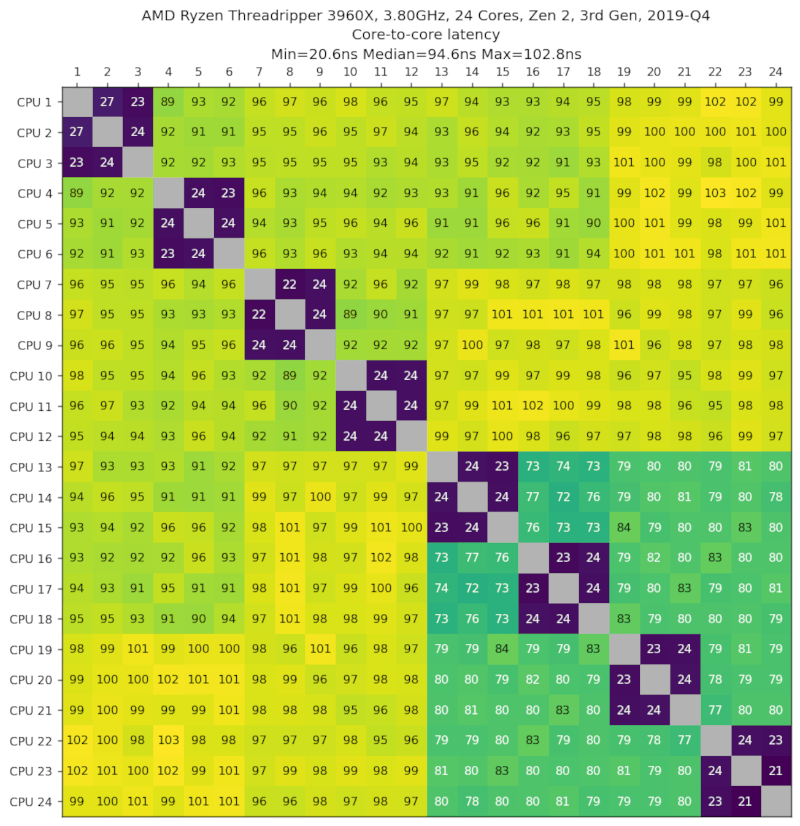
AMD Ryzen Threadripper 3960X,3.80GHz,24核心,Zen 2,第3代,2019-Q4
数据由Mathias Siegel提供。
我们看到CPU以8组3个的方式排列,并且组[13,24]中的CPU性能更好。
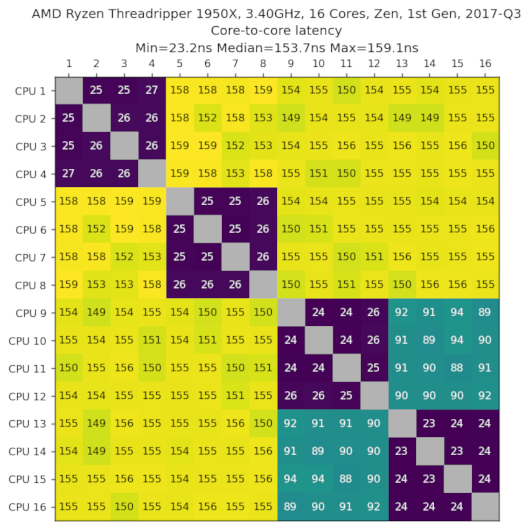
AMD Ryzen Threadripper 1950X,3.40GHz,16核心,Zen,第1代,2017-Q3
数据由Jakub Okoński提供。
我们看到CPU以4组4个的方式排列,并且组[9,16]中的CPU性能更好。
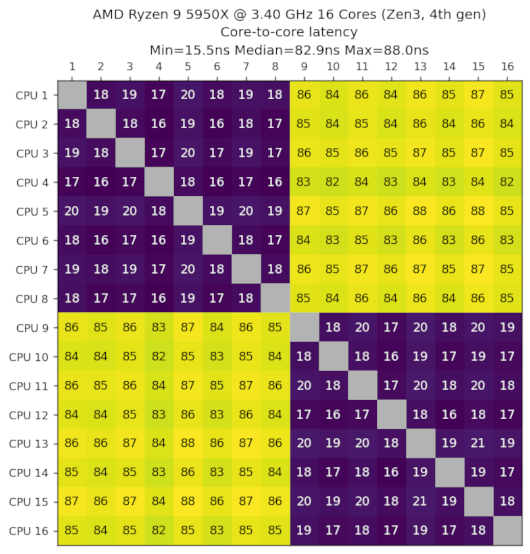
AMD Ryzen 9 5950X,3.40GHz,16核心,Zen3,第四代,2020年第一季度
数据由John Schoenick提供。
我们可以看到两组8个核心,组内延迟为17ns,组间延迟为85ns。
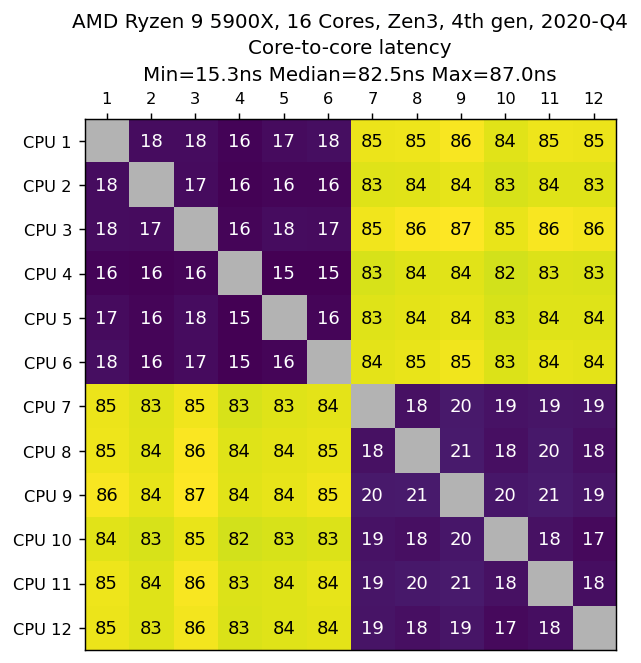
AMD Ryzen 9 5900X,3.40GHz,12核心,Zen3,第4代,2020-Q4
数据由Scott Markwell提供。
我们看到两组6个核心,组内延迟为16ns,组间延迟为84ns。
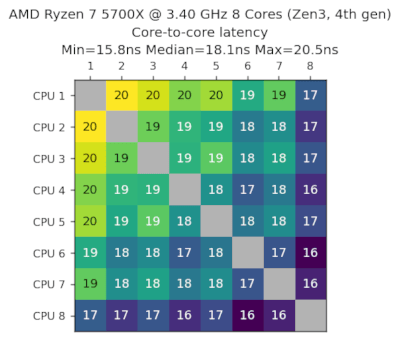
AMD Ryzen 7 5700X,3.40GHz,8核心,Zen3,第4代,2022-Q2
数据由Ashley Sommer提供。
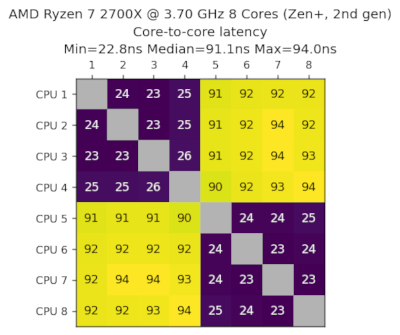
AMD Ryzen 7 2700X,3.70GHz,8核心,Zen+,第2代,2018-Q3
数据由David Hoppenbrouwers提供。
我们可以看到两组4个核心,组内延迟为24ns,组间延迟为92ns。
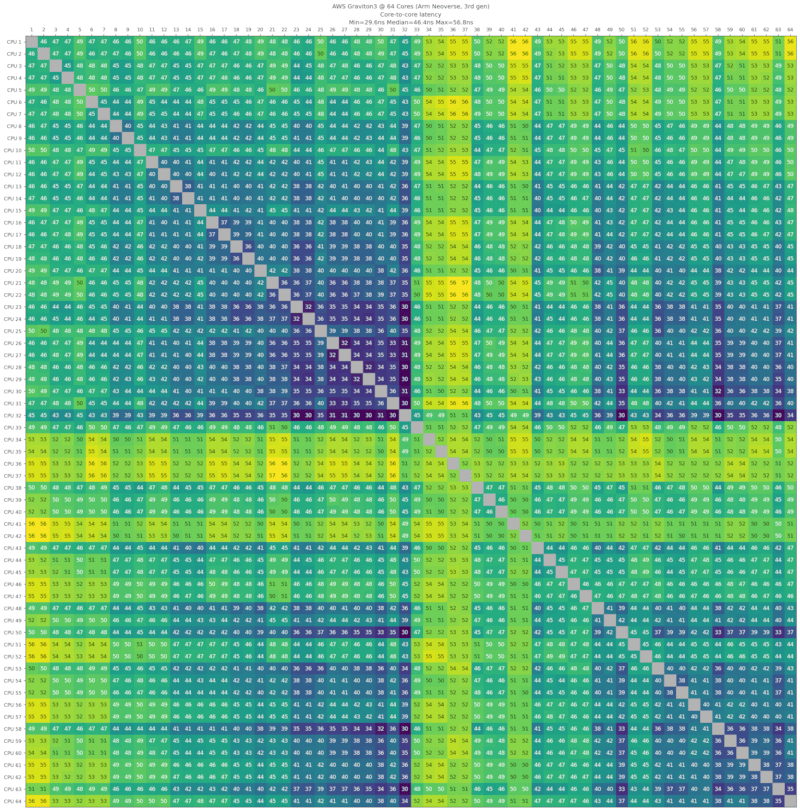
AWS Graviton3,64核心,Arm Neoverse,第3代,2021-Q4
来自AWS c7g.16xlarge机器。
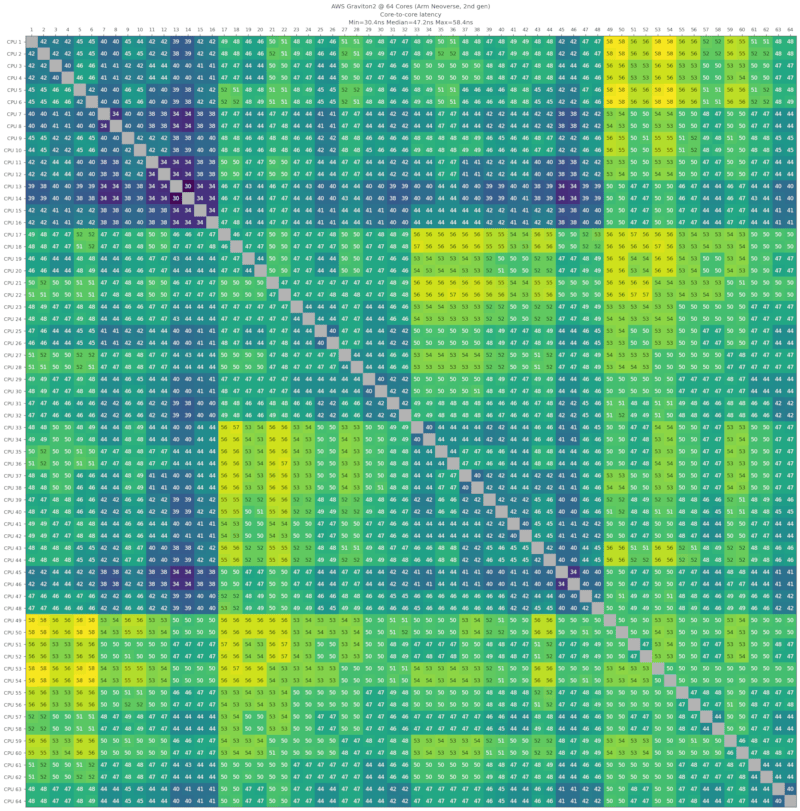
AWS Graviton2,64核心,Arm Neoverse,第二代,2020年第一季度
来自AWS c6gd.metal机器。
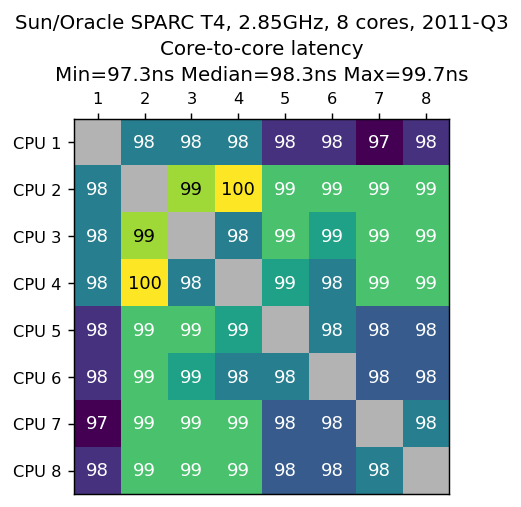
Sun/Oracle SPARC T4,2.85GHz,8核心,2011-Q3
数据由Kokoa van Houten提供。
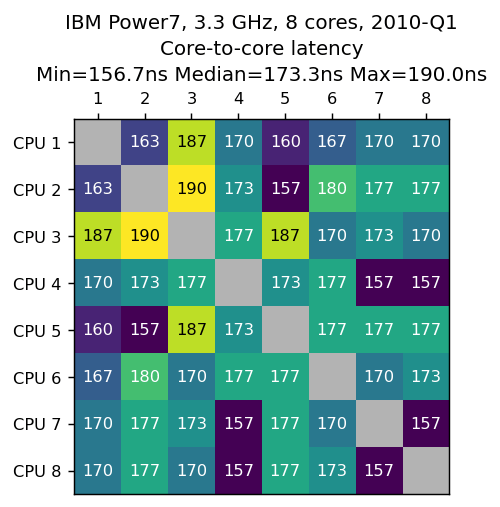
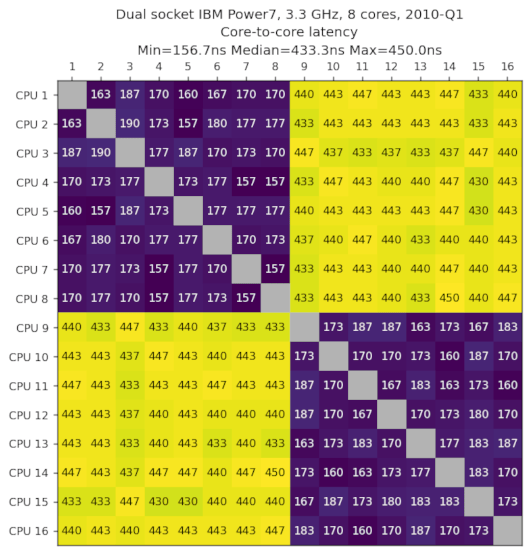
IBM Power7,3.3GHz,8核心,2010-Q1
数据由Kokoa van Houten提供。
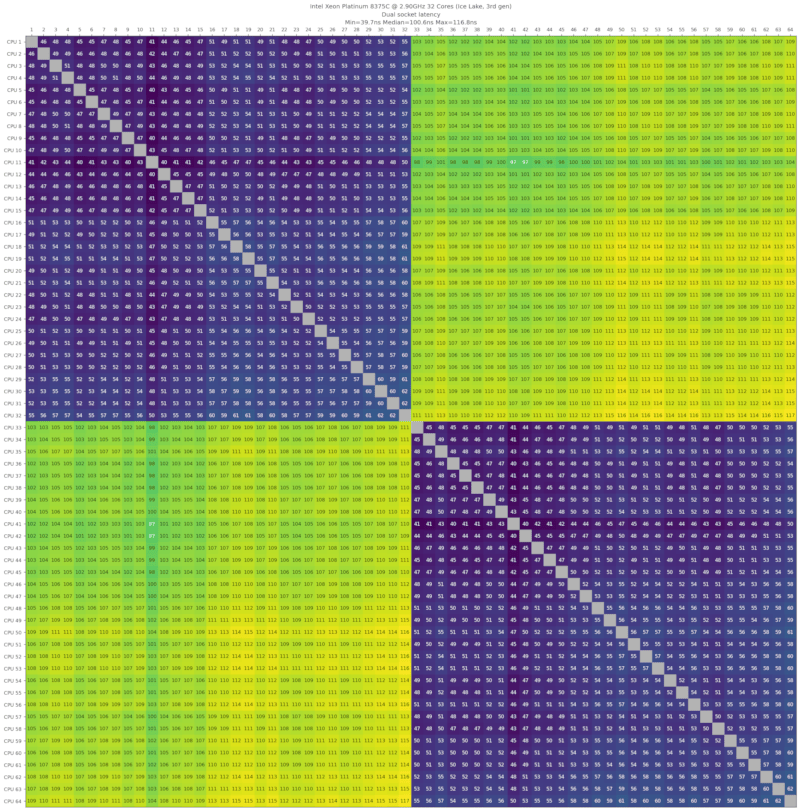
双插槽结果
以下显示了双插槽配置的延迟,其中第一个插槽上的一个CPU向第二个插槽上的另一个CPU发送消息。延迟旁边的数字表示与单插槽相比的减速。
| CPU | 中值延迟 |
|---|---|
| Intel Xeon Platinum 8375C,2.90GHz,32核心,Ice Lake,第3代,2021-Q2 | 108ns (2.1x) |
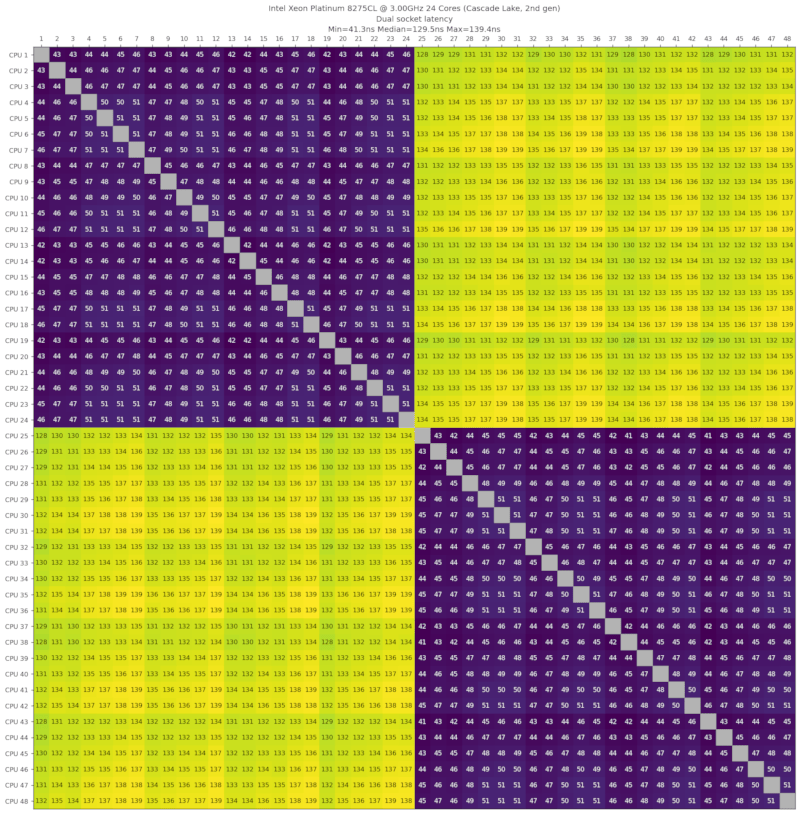
| Intel Xeon Platinum 8275CL,3.00GHz,24核心,Cascade Lake,第2代,2019-Q2 | 134ns (2.8x) |
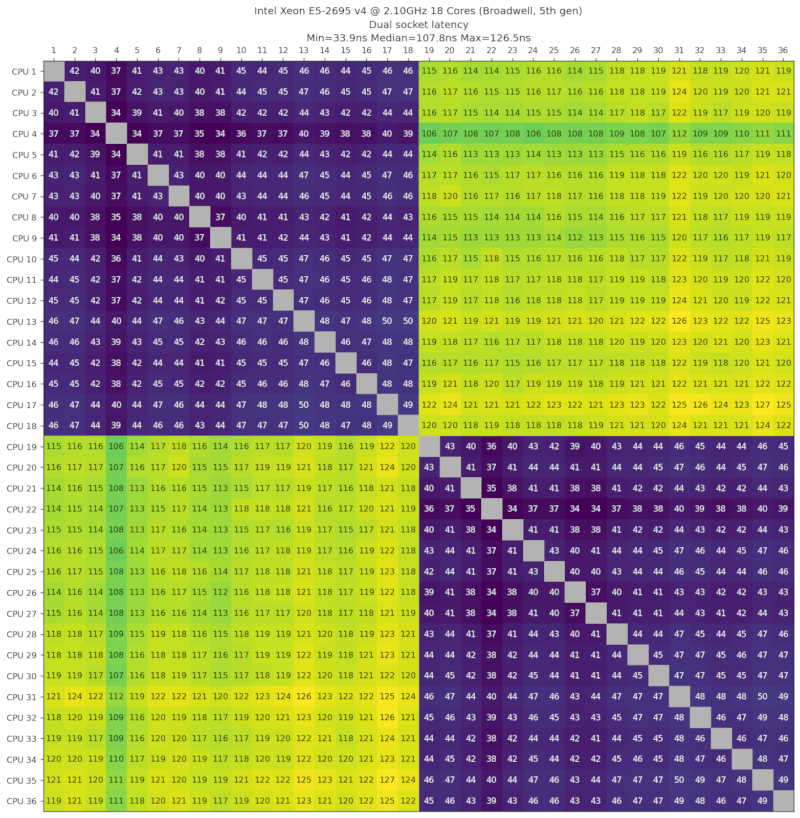
| Intel Xeon E5-2695 v4,2.10GHz,18核心,Broadwell,第5代,2016-Q1 | 118ns (2.7x) |
| AMD EPYC 7R13,48核心,Milan,第3代,2021-Q1 | 197ns |
| Sun/Oracle SPARC T4,2.85GHz,8核心,2011-Q3 | 356ns (3.6x) |
| IBM Power7,3.3GHz,8核心,2010-Q1 | 443ns (2.5x) |
双英特尔至强铂金8375C,2.90GHz,32核心,冰湖,第三代,2021年第二季度
来自AWS c6i.metal机器。
双英特尔至强铂金8275CL,3.00GHz,24核心,Cascade Lake,第二代,2019年第二季度
来自AWS c5.metal机器。
双英特尔至强E5-2695 v4,2.10GHz,18核心,Broadwell,第五代,2016年第一季度
来自GTHost提供的机器。
双AMD EPYC 7R13,48核心,Milan,第三代,2021年第一季度
来自AWS c6a.metal机器。
这个情况有些奇怪。Socket 1的单插槽测试显示,跨组的平均延迟为107ns,但Socket 2显示为200ns。它慢了2倍,非常奇怪。其他平台不会这样表现。实际上,Socket 2中的插槽到插槽延迟比插槽内的核心到核心延迟还要低。
Anandtech对双插槽AMD EPYC 7763和7742进行了类似测量。
Socket 2的表现与Socket 1不同,它慢了一倍.

Sun/Oracle SPARC T4,2.85GHz,8核心,2011-Q3
数据由Kokoa van Houten提供。

双IBM Power7,3.3GHz,8核心,2010-Q1
数据由Kokoa van Houten提供。
超线程
我们测量同一核心的两个超线程之间的延迟
| CPU | 中值延迟 |
|---|---|
| Intel Core i9-12900K,8+8核心,Alder Lake,12代,2021-Q4 | 4.3ns |
| Intel Core i9-9900K,3.60GHz,8核心,Coffee Lake,第9代,2018-Q4 | 6.2ns |
| Intel Core i7-1165G7,2.80GHz,4核心,Tiger Lake,第11代,2020-Q3 | 5.9ns |
| Intel Core i7-6700K,4.00GHz,4核心,Skylake,第6代,2015-Q3 | 6.9ns |
| Intel Core i5-10310U,4核心,Comet Lake,第10代,2020-Q2 | 7.3ns |
| Intel Xeon Platinum 8375C,2.90GHz,32核心,Ice Lake,第3代,2021-Q2 | 8.1ns |
| Intel Xeon Platinum 8275CL,3.00GHz,24核心,Cascade Lake,第2代,2019-Q2 | 7.6ns |
| Intel Xeon E5-2695 v4,2.10GHz,18核心,Broadwell,第5代,2016-Q1 | 7.6ns |
| AMD EPYC 7R13,48核心,Milan,第3代,2021-Q1 | 9.8ns |
| AMD Ryzen Threadripper 3960X,3.80GHz,24核心,Zen 2,第3代,2019-Q4 | 6.5ns |
| AMD Ryzen Threadripper 1950X,3.40GHz,16核心,Zen,第1代,2017-Q3 | 10ns |
| AMD Ryzen 9 5950X,3.40GHz,16核心,Zen3,第4代,2020-Q4 | 7.8ns |
| AMD Ryzen 9 5900X,3.40GHz,12核心,Zen3,第4代,2020-Q4 | 7.6ns |
| AMD Ryzen 7 5700X,3.40GHz,8核心,Zen3,第4代,2022-Q2 | 7.8ns |
| AMD Ryzen 7 2700X,3.70GHz,8核心,Zen+,第2代,2018-Q3 | 9.7ns |
| Sun/Oracle SPARC T4,2.85GHz,8核心,2011-Q3 | 24ns |
| IBM Power7,3.3GHz,8核心,2010-Q1 | 70ns |
笔记本results/results.ipynb包含生成这些图表的代码
如何使用
首先在linux上安装Rust和gcc,然后
$ cargo install core-to-core-latency
$ core-to-core-latency
Num cores: 10
Using RDTSC to measure time: false
Num round trips per samples: 1000
Num samples: 300
Showing latency=round-trip-time/2 in nanoseconds:
0 1 2 3 4 5 6 7 8 9
0
1 52±6
2 38±6 39±4
3 39±5 39±6 38±6
4 34±6 38±4 37±6 36±5
5 38±5 38±6 38±6 38±6 37±6
6 38±5 37±6 39±6 36±4 49±6 38±6
7 36±6 39±5 39±6 37±6 35±6 36±6 38±6
8 37±5 38±6 35±5 39±5 38±6 38±5 37±6 37±6
9 48±6 39±6 36±6 39±6 38±6 36±6 41±6 38±6 39±6
Min latency: 34.5ns ±6.1 cores: (4,0)
Max latency: 52.1ns ±9.4 cores: (1,0)
Mean latency: 38.4ns
贡献
使用core-to-core-latency 5000 --csv > output.csv指令程序使用每个样本5000次迭代以减少噪声,并保存结果。
它可用于results/results.ipynb笔记本中的渲染图表。
创建一个包含生成的output.csv文件的GitHub问题,我将添加你的结果。
许可
本软件根据MIT许可证授权
依赖
~4.5–7MB
~127K SLoC