24 个版本
| 0.0.24 | 2024 年 3 月 26 日 |
|---|---|
| 0.0.23 | 2024 年 3 月 26 日 |
| 0.0.20 | 2023 年 1 月 1 日 |
| 0.0.19 | 2022 年 8 月 26 日 |
| 0.0.17 | 2021 年 9 月 14 日 |
#59 in 性能分析
39 每月下载量
用于 4 包
120KB
618 行
bma-benchmark
Rust 和人类的基准测试
这是做什么的
一个轻量级且简单的 Rust 基准测试库。
如何使用
让我们创建一个简单的基准测试,只使用 crate 宏
#[macro_use]
extern crate bma_benchmark;
use std::sync::Mutex;
let n = 100_000_000;
let mutex = Mutex::new(0);
warmup!();
benchmark_start!();
std::hint::black_box(move || {
for _ in 0..n {
let _a = mutex.lock().unwrap();
}
})();
benchmark_print!(n);
同样也可以使用一个单独的 "benchmark" 宏
#[macro_use]
extern crate bma_benchmark;
use std::sync::Mutex;
let mutex = Mutex::new(0);
benchmark!(100_000_000, {
let _a = mutex.lock().unwrap();
});
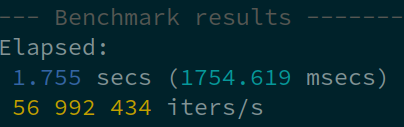
让我们创建一个更复杂的分阶段基准测试,比较例如 Mutex 与 RwLock。分阶段基准测试会显示一个比较表。如果指定了参考阶段,表格还会包含所有其他阶段的速度差异。
#[macro_use]
extern crate bma_benchmark;
use std::sync::{Mutex, RwLock};
let n = 10_000_000;
let mutex = Mutex::new(0);
let rwlock = RwLock::new(0);
warmup!();
staged_benchmark_start!("mutex");
std::hint::black_box(move || {
for _ in 0..n {
let _a = mutex.lock().unwrap();
}
})();
staged_benchmark_finish_current!(n);
staged_benchmark_start!("rwlock-read");
std::hint::black_box(move || {
for _ in 0..n {
let _a = rwlock.read().unwrap();
}
})();
staged_benchmark_finish_current!(n);
staged_benchmark_print_for!("rwlock-read");
同样也可以使用几个 staged_benchmark 宏(会自动应用黑盒)
#[macro_use]
extern crate bma_benchmark;
use std::sync::{Mutex, RwLock};
let n = 10_000_000;
let mutex = Mutex::new(0);
let rwlock = RwLock::new(0);
warmup!();
staged_benchmark!("mutex", n, {
let _a = mutex.lock().unwrap();
});
staged_benchmark!("rwlock-read", n, {
let _a = rwlock.read().unwrap();
});
staged_benchmark_print_for!("rwlock-read");
或者使用 benchmark_stage 属性分割成函数
use std::sync::{Mutex, RwLock};
#[macro_use]
extern crate bma_benchmark;
#[benchmark_stage(i=10_000_000)]
fn benchmark_mutex(mutex: Mutex<u64>) {
let _a = mutex.lock().unwrap();
}
#[benchmark_stage(i=10_000_000,name="rwlock-read")]
fn benchmark_rwlock(rwlock: RwLock<u64>) {
let _a = rwlock.read().unwrap();
}
let mutex = Mutex::new(0);
let rwlock = RwLock::new(0);
benchmark_mutex(mutex);
benchmark_rwlock(rwlock);
staged_benchmark_print_for!("rwlock-read");
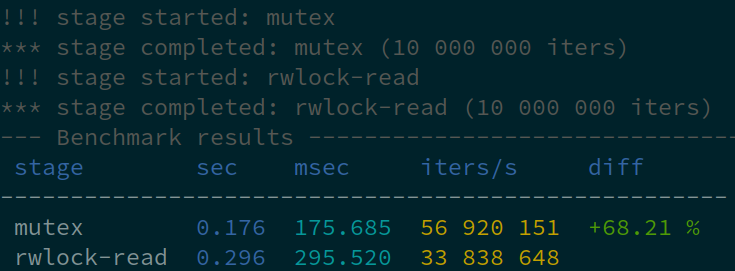
错误
宏 benchmark_print、staged_benchmark_finish 和 staged_benchmark_finish_current 接受错误计数作为额外的参数。
对于代码块,可以使用宏 benchmark_check 和 staged_benchmark_check。在这种情况下,语句必须返回 true 以正常执行,返回 false 表示错误。
#[macro_use]
extern crate bma_benchmark;
use std::sync::Mutex;
let mutex = Mutex::new(0);
benchmark_check!(10_000_000, {
mutex.lock().is_ok()
});
benchmark_stage 属性有一个 check 选项,其行为类似。如果使用,函数体必须(不是返回而是)以 bool 结尾。
如果有错误报告,将出现额外的列,成功次数、错误次数和错误率

延迟基准测试
(对于延迟基准测试,不建议预热和适用黑盒)
use bma_benchmark::LatencyBenchmark;
let mut lb = LatencyBenchmark::new();
for _ in 0..1000 {
lb.op_start();
// do something
lb.op_finish();
}
lb.print();
latency (μs) avg: 883, min: 701, max: 1_165
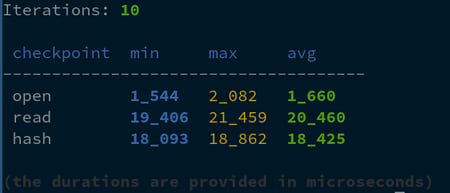
性能测量
(对于延迟基准测试,不建议预热和适用黑盒)
use bma_benchmark::Perf;
let file_path = "largefile";
let mut perf = Perf::new();
for _ in 0..10 {
perf.start();
let mut file = File::open(file_path).unwrap();
perf.checkpoint("open");
let mut hasher = Sha256::new();
let mut buffer = Vec::new();
file.read_to_end(&mut buffer).unwrap();
perf.checkpoint("read");
hasher.update(&buffer);
perf.checkpoint("hash");
}
perf.print();
需要更复杂的功能?请检查包文档,并直接使用其结构。
祝您享受!
依赖关系
~4–12MB
~116K SLoC