23 个版本 (9 个破坏性版本)
| 1.0.0-alpha.7 | 2024年4月6日 |
|---|---|
| 1.0.0-alpha.6 | 2023年10月11日 |
| 1.0.0-alpha.4 | 2023年5月13日 |
| 1.0.0-alpha.3 | 2023年3月10日 |
| 0.3.2 | 2021年7月23日 |
#2 在 解析工具
212,682 每月下载量
用于 247 个crate (90 直接)
465KB
10K SLoC
Chumsky
![]()
![]()
![]()
![]()
一个具有强大错误恢复功能的解析库,适用于人类使用。
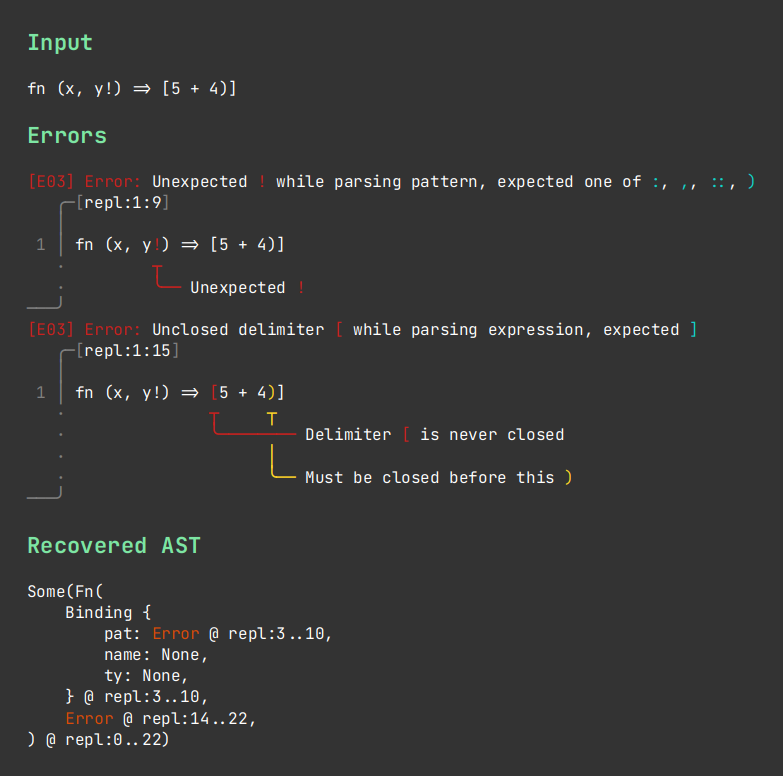
注意:错误诊断渲染由 Ariadne 执行
内容
功能
- 大量组合器!
- 泛型支持输入、输出、错误和跨度类型
- 强大的错误恢复策略
- 内联映射到您的 AST
- 针对文本的解析器,适用于
u8和char - 递归解析器
- 完全支持回溯,允许解析所有已知上下文无关文法
- 解析嵌套输入,允许您将定界符解析移动到词法阶段(就像 Rust 所做的那样!)
- 内置解析调试
Brainfuck 解析器示例
请参阅 examples/brainfuck.rs 以获取完整的解释器(cargo run --example brainfuck -- examples/sample.bf)。
use chumsky::prelude::*;
#[derive(Clone)]
enum Instr {
Left, Right,
Incr, Decr,
Read, Write,
Loop(Vec<Self>),
}
fn parser<'a>() -> impl Parser<'a, &'a str, Vec<Instr>> {
recursive(|bf| choice((
just('<').to(Instr::Left),
just('>').to(Instr::Right),
just('+').to(Instr::Incr),
just('-').to(Instr::Decr),
just(',').to(Instr::Read),
just('.').to(Instr::Write),
bf.delimited_by(just('['), just(']')).map(Instr::Loop),
))
.repeated()
.collect())
}
其他示例包括
- JSON 解析器 (
cargo run --example json -- examples/sample.json) - 一个简单的Rust语言解释器(代码:
cargo run --example nano_rust -- examples/sample.nrs)
教程
Chumsky有一个教程,教您如何编写一个解析器和解释器,用于具有一元和二元运算符、运算符优先级、函数、let声明和调用的简单动态语言。
什么是解析组合器?
解析器组合器是一种通过定义其他解析器来实现解析器的技术。结果解析器使用递归下降策略将一个令牌流转换成输出。使用解析器组合器定义解析器大致相当于使用Rust的Iterator特性定义迭代算法:类型驱动的Iterator接口使得犯错误的可能性降低,并使复杂的迭代逻辑编码变得更容易。解析器组合器也是一样。
为什么使用解析组合器?
编写具有良好错误恢复能力的解析器在概念上很困难,也很耗时。这需要理解递归下降算法的复杂性,然后在其之上实现恢复策略。如果您正在开发编程语言,您几乎肯定会在过程中改变对语法的想法,从而导致一些缓慢且痛苦的分析器重构。解析器组合器通过提供一个易于使用的API来快速迭代语法,从而解决了这两个问题。
解析器组合器也非常适合没有现有解析器的领域特定语言。在这种情况下编写一个可靠、容错性强的解析器,在良好的解析器组合器库的帮助下,可以从多天的任务变成半小时的任务。
分类
Chumsky的解析器是递归下降解析器,能够解析解析表达式语法(PEGs),这包括了所有已知上下文无关语言。从理论上讲,可以进一步扩展Chumsky以接受有限的上下文相关语法,尽管这很少需要。
错误恢复
Chumsky支持错误恢复,这意味着它可以遇到语法错误,报告错误,然后尝试将自己恢复到一个可以继续解析的状态,从而一次可以产生多个错误,并仍然可以从输入生成部分AST以供后续编译阶段使用。
然而,没有银弹策略可以用于错误恢复。根据定义,如果解析器的输入无效,那么解析器只能对输入的意义做出有根据的猜测。不同的恢复策略对不同语言以及语言中的不同模式会更好。
Chumsky提供了各种恢复策略(每个都实现了Strategy特质),但重要的是要了解您应用的、应用的地点以及应用的顺序将极大地影响Chumsky能够产生的错误质量,以及它能够恢复的有用AST的广泛程度。
- 哪些
- 在哪里
- 顺序如何
将极大地影响Chumsky能够产生的错误质量,以及它能够恢复的有用AST的广泛程度。在可能的情况下,您应该首先尝试更“具体”的恢复策略,而不是盲目跳过大量输入的策略。
建议您在不同的场景和解析器不同层级上尝试应用不同的策略,以找到让您满意的配置。如果提供的错误恢复策略中没有一种能够覆盖您希望捕获的特定模式,您甚至可以通过深入研究Chumsky的内部机制并实现自己的策略来创建自己的策略!如果您想出了一种有用的策略,请随意在主仓库上发起PR!
性能
Chumsky侧重于高质量错误和人体工程学,而不是性能。尽管如此,Chumsky能够跟上您编译器的其他部分是很重要的!遗憾的是,由于Chumsky的性能完全取决于您正在解析的内容、您如何构建解析器、解析器首先尝试匹配的模式、错误类型的复杂度、构建AST所涉及的内容等,因此给出有意义的基准指标是极其困难的。尽管如此,这里提供了一些我在Ryzen 7 3700x上运行的JSON基准中的数据。
test chumsky ... bench: 4,782,390 ns/iter (+/- 997,208)
test pom ... bench: 12,793,490 ns/iter (+/- 1,954,583)
我还包含了来自pom的结果,这是另一个具有类似设计的解析器组合crate,作为参考点。被解析的样本文件大致代表了典型的JSON数据,有3,018行。这意味着每秒可以解析超过630,000行的JSON。
显然,这比一个优化良好的手写解析器要慢一些:但这是可以接受的!Chumsky的目标是足够快。如果您已经为您的语言编写了足够多的代码,以至于解析性能甚至开始成为一个问题,那么您已经投入了足够的时间和资源到您的语言中,手写解析器是最佳选择!
计划中的功能
- 一个优化过的“快乐路径”解析器模式,跳过错误恢复和错误生成
- 一个更快的“验证”解析器模式,保证不进行分配,不生成输出,只验证输入的有效性
哲学
Chumsky应该是
- 易于使用,即使您不完全理解解析器在底层是如何工作的
- 类型驱动的,在编译时将用户推向反模式
- 默认情况下是一个成熟的、“包含了电池”的上下文无关解析解决方案。如果您需要手动实现
Parser或Strategy,那么这是一个需要解决的问题 - 足够快,但不是更快(即在错误质量和性能之间有权衡时,Chumsky将始终选择前者)
- 模块化和可扩展的,允许用户实现自己的解析器、恢复策略、错误类型、跨度,并对输入令牌和输出AST进行泛型处理
注意
对于选择这样一个荒谬的名字,我为Noam表示歉意。
许可证
Chumsky采用MIT许可证(见主仓库中的LICENSE)。
依赖项
~1.4–6.5MB
~91K SLoC